python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)
之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下直接登陆的爬取:
爬虫是模拟人的行为来请求网页读取数据的现在我们划分一下过程,从登陆到获取:
先看一下我们到个人中心的过程:
登陆界面->输入账号密码->进入个人中心
1 进入登陆页面 可以说是第一次请求 此时会产生相应的COOKIE值,因为你只要先进入到页面才可以进行密码输入等行为
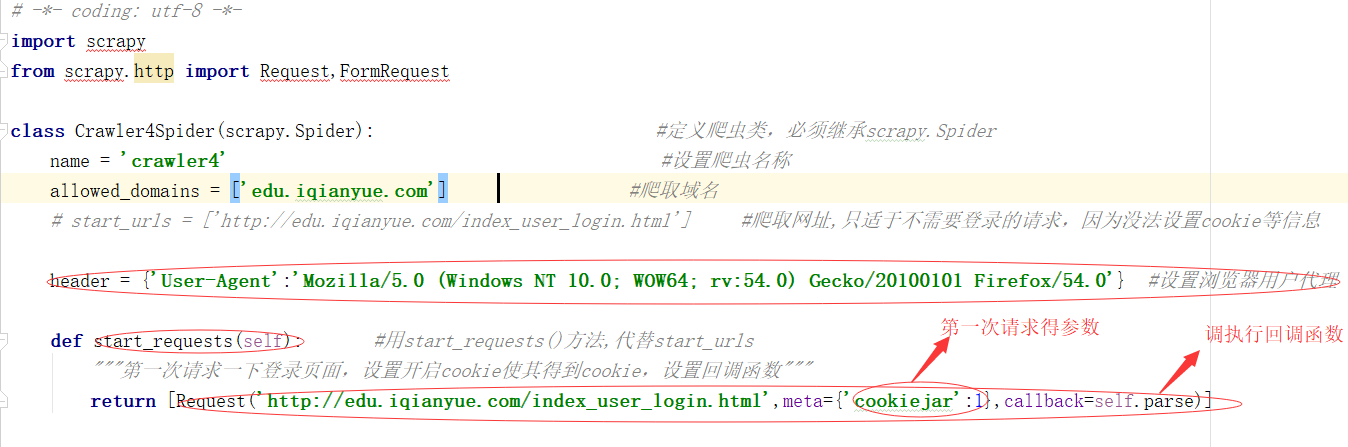
cookiejar:1表示开启COOKIE记录
现在看下回调函数:
2 进入登陆页面后需要进行输入数据行为,方式为POST请求,传输的数据在NETWORK里找一下字段 ,一般都是NUMBER,USERNAME什么的 作为POST携带的数据

看下结果

3 之前请求的是登陆页面用的是GET请求,现在需要做一步登陆的过程就变成了POST请求,也就是第二步请求,同样的是在parse函数里执行了
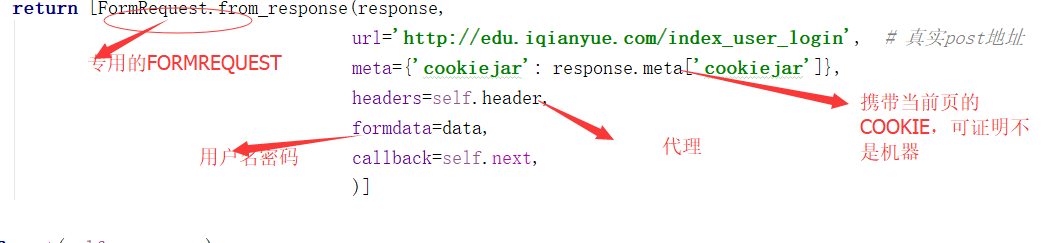
4 meta={'cookiejar':True}表示使用授权后的cookie访问需要登录查看的页面

5 获取请求后的COOKIE,响应COOKIE,然后进行获取个人中心:
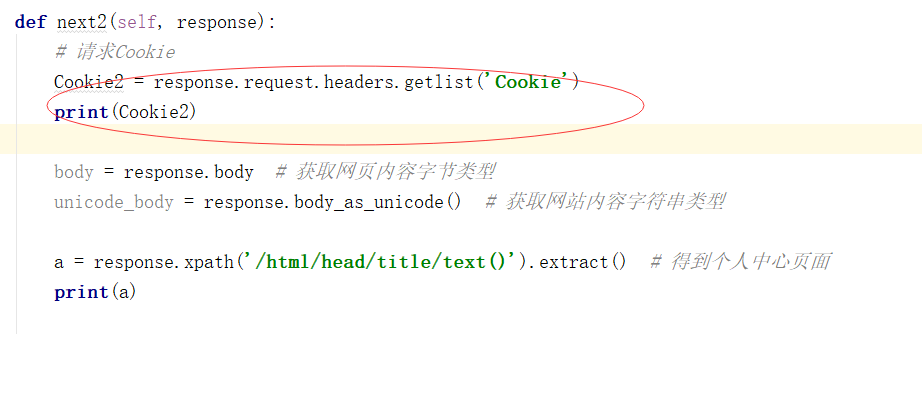
看下结果:

python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)的更多相关文章
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量 先准备下下数据:商品名,商品链接,评价数量 第一步:在item ...
- python3下scrapy爬虫(第八卷:循环爬取网页多页数据)
之前我们做的数据爬取都是单页的现在我们来讲讲多页的 一般方式有两种目标URL循环抓取 另一种在主页连接上找规律,现在我用的案例网址就是 通过点击下一页的方式获取多页资源 话不多说全在代码里(因为刚才写 ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- python3下scrapy爬虫(第七卷:编辑器内执行scrapy)
之前我们都是在终端切入到scrapy的路境内执行爬虫的,你要多敲多少行的字节,所以这次我们谈谈如何在编辑器里执行,这个你可以用在爬虫中,当你使用PYTHONWEB开发时尽量不要在编辑器内启动端口服务那 ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- 使用ApiPost测试接口时需要先登录怎么办?利用Cookie模拟登陆!
ApiPost简介: ApiPost是一个支持团队协作,并可直接生成文档的API调试.管理工具.它支持模拟POST.GET.PUT等常见请求,是后台接口开发者或前端.接口测试人员不可多得的工具 . 下 ...
- Python爬虫【三】利用requests和正则抓取猫眼电影网上排名前100的电影
#利用requests和正则抓取猫眼电影网上排名前100的电影 import requests from requests.exceptions import RequestException imp ...
随机推荐
- Digit sum (第 44 届 ACM/ICPC 亚洲区域赛(上海)网络赛)进制预处理水题
131072K A digit sum S_b(n)Sb(n) is a sum of the base-bb digits of nn. Such as S_{10}(233) = 2 + 3 ...
- tensorflow笔记(北大网课实战)
1. tf.multiply(x,y1) # 对应元素相乘 tf.matmul(x,y2) # 矩阵相乘 2.会话:执行计算图中的节点运算的. with tf.Session() as sess: p ...
- Vue.js——2.第一个Vue程序
代码 <div id="app"> <p>{{msg}}</p> </div> <script> let vm=new ...
- 18 11 04 初用单片机 c语言学习
---恢复内容开始--- 1 作为单片机使用的的 c 语言学习 ++ 增位运算符 在原有基础上加一 -- 相同 由于单片机只有 ~ 取反 & 两个 参数里有没有 | 两个 参数里有没有 ^ 两 ...
- Python笔记_第四篇_高阶编程_实例化方法、静态方法、类方法和属性方法概念的解析。
1.先叙述静态方法: 我们知道Python调用类的方法的时候都要进行一个实例化的处理.在面向对象中,一把存在静态类,静态方法,动态类.动态方法等乱七八糟的这么一些叫法.其实这些东西看起来抽象,但是很好 ...
- UML-类图-关联
- python导入自定义的库
一.导入项目文件夹下的模块 1.导入整个模块 import 模块名 2.导入模块的某个函数 from 模块名 import 函数名 示例 untitled是项目文件夹,文件结构如下 ①在a.py导入c ...
- 1. 模块化的引入与导出 (commonJS规范 和ES6规范)
node组件导出模块 node一般用commonJS规范 可以通过module.exports导出自己写的模块 这样其他的js文件就可以引用并使用这个模块 module.exports = { log ...
- Vue 项目中应用
Vue使用 一.vue生命周期 # main.js import Vue from 'vue' import App from './App.vue' import router from './ro ...
- jmlr论文下载
下载脚本 #!/bin/bash # down_jmlr.sh ver=$1 wget http://www.jmlr.org/papers/$ver/ -O index.htm cat index. ...