在pytorch下使用tensorboardX(win10;谷歌浏览器;jupyter notebook)
使用环境:win10 ,在jupyter notebook下运行 谷歌浏览器
1、环境安装
使用conda 安装,打开anacond powershell,输入pip install tensorboard ,然后安装pip install tensorflow
2、使用操作
在终端或者环境命令行下,打开程序所在目录,使用shift+右键进入cmd,输入jupyter notebook,进入环境,打开程序。
(1)在程序开头加入
from torch.utils.tensorboard import SummaryWriter,而不是from tensorboardX import SummaryWriter,参考https://pytorch.org/tutorials/intermediate/tensorboard_tutorial.html
(2)writer = SummaryWriter('runs/exp1'),runs/exp1表示相关信息存储位置,可自行定义。然后调用相关函数即可。例如想知道训练次数epoch与损失函数之间的关系,调用writer.add_scalar('Train Loss', train_loss / len(train_data), global_step=epoch) 。然后运行一次函数,等待程序运行完毕。
(3)打开runs文件夹的上一级目录,然后使用shift+右键进入cmd,输入tensorboard --logdir=runs ,随后弹出如下

复制网址,然后打开(据说只能使用谷歌浏览器,未经验证)。有可能出现如下提示,打开exp1文件夹,如果文件大小为0,则表示数据未成功写入,重新运行程序即可。或者重新操作第三步
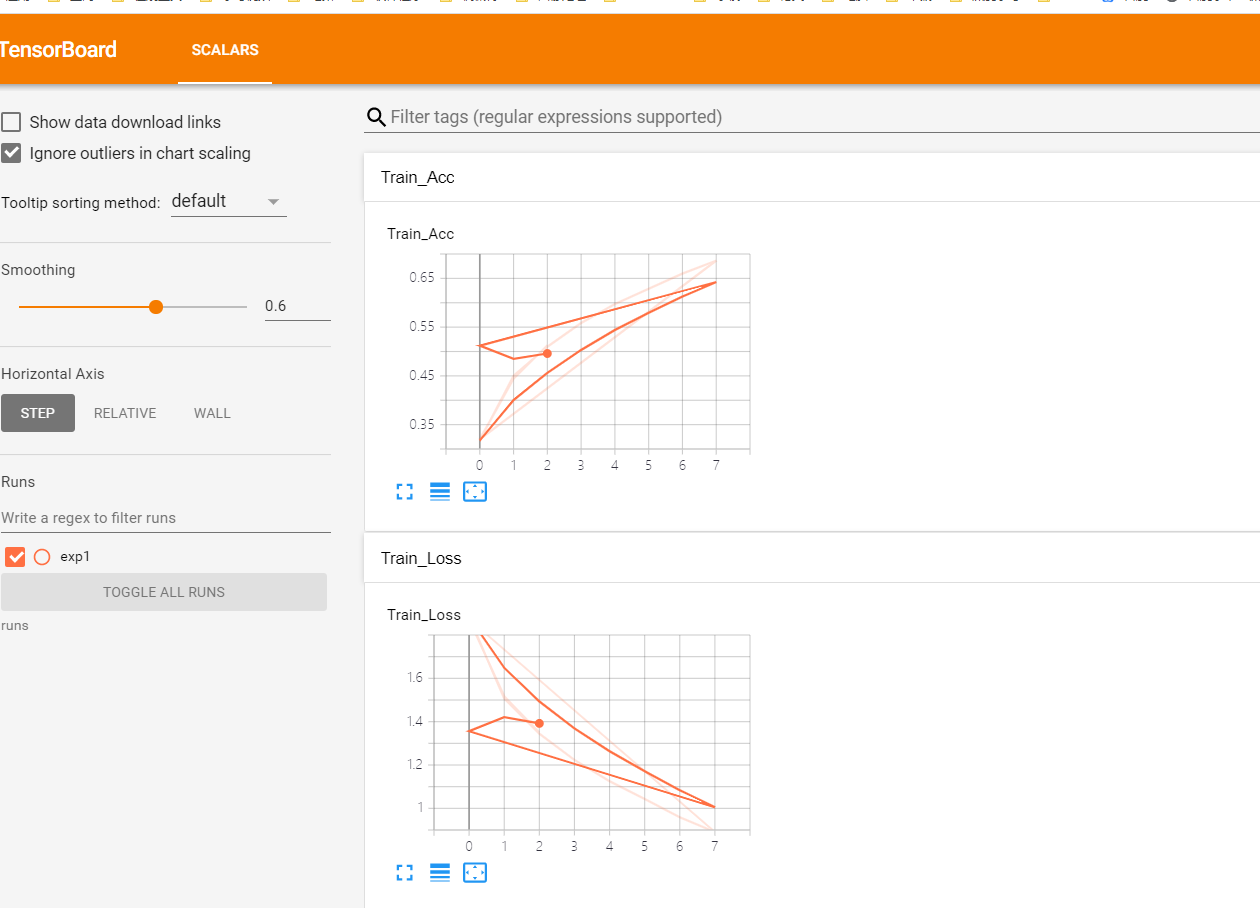
如果进入如下类似页面,则表示成功
指令集补充
(1)add_scalar(tag, scalar_value, global_step=None, walltime=None)
功能:
在一个图表中记录一个标量的变化,常用于 Loss 和 Accuracy 曲线的记录。
参数:
tag(string)- 该图的标签,类似于 polt.title。
scalar_value(float or string/blobname)- 用于存储的值,曲线图的 y 坐标
global_step(int)- 曲线图的 x 坐标
walltime(float)- 为 event 文件的文件名设置时间,默认为 time.time()
(2)add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
功能:
在一个图表中记录多个标量的变化,常用于对比,如 trainLoss 和 validLoss 的比较
等。
参数:
main_tag(string)- 该图的标签。
tag_scalar_dict(dict)- key 是变量的 tag, value 是变量的值。
global_step(int)- 曲线图的 x 坐标
walltime(float)- 为 event 文件的文件名设置时间,默认为 time.time()
writer.add_scalars('result', {'Train Loss':train_loss / len(train_data),'Train Acc':train_acc / len(train_data),'Valid Loss':valid_loss / len(valid_data),'Valid Acc':valid_acc / len(valid_data)}, global_step=epoch)
类似上面代码,其中result表示标题,train Loss等表示每条线名字,epoch表示x轴
(3)add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None)
功能:
绘制直方图和多分位数折线图,常用于监测权值及梯度的分布变化情况,便于诊断网
络更新方向是否正确。
参数:
tag(string)- 该图的标签,类似于 polt.title。
values(torch.Tensor, numpy.array or string/blobname)- 用于绘制直方图的值
global_step(int)- 曲线图的 y 坐标
bins(string)- 决定如何取 bins,默认为‘tensorflow’ ,可选: ’auto’, ‘fd’ 等
walltime(float)- 为 event 文件的文件名设置时间,默认为 time.time()
(4)add_image(tag, img_tensor, global_step=None, walltime=None)
功能:
绘制图片,可用于检查模型的输入,监测 feature map 的变化,或是观察 weight。
参数:
tag(string)- 该图的标签,类似于 polt.title。
img_tensor(torch.Tensor,numpy.array, or string/blobname)- 需要可视化的图片数
据, shape = [C,H,W]。
global_step(int)- x 坐标。
walltime(float)- 为 event 文件的文件名设置时间,默认为 time.time()。
通常会借助 torchvision.utils.make_grid() 将一组图片绘制到一个窗口
(5)torchvision.utils.make_grid(tensor, nrow=8, padding=2, normalize=False, ra
nge=None, scale_each=False, pad_value=0)
功能:
将一组图片拼接成一张图片,便于可视化。
参数:
tensor(Tensor or list)- 需可视化的数据, shape:(B x C x H x W) ,B 表示 batch 数,即
几张图片
nrow(int)- 一行显示几张图,默认值为 8。
padding(int)- 每张图片之间的间隔,默认值为 2。
normalize(bool)- 是否进行归一化至(0,1)。
range(tuple)- 设置归一化的 min 和 max,若不设置,默认从 tensor 中找 min 和 max。
scale_each(bool)- 每张图片是否单独进行归一化,还是 min 和 max 的一个选择。
pad_value(float)- 填充部分的像素值,默认为 0,即黑色。
(6)add_graph(model, input_to_model=None, verbose=False, **kwargs)
功能:
绘制网络结构拓扑图。
参数:
model(torch.nn.Module)- 模型实例
inpjt_to_model(torch.autograd.Variable)- 模型的输入数据,可以生成一个随机数,只
要 shape 符合要求即可
运行以下代码:
import torch
from torch import nn
import numpy as np
from torch.autograd import Variable
from torchvision.datasets import CIFAR10 from datetime import datetime
import os
from torch.utils.tensorboard import SummaryWriter
import torchvision.models as models
import tensorflow as tf #定义网络架构
class AlexNet(nn.Module):
def __init__(self):
super().__init__() # 第一层是 5x5 的卷积, 输入的 channels 是 ,输出的 channels 是 , 步长是 , 没有 padding
self.conv1 = nn.Sequential(
nn.Conv2d(, , ),
nn.ReLU(True)) # 第二层是 3x3 的池化, 步长是 , 没有 padding
self.max_pool1 = nn.MaxPool2d(
, ) # 第三层是 5x5 的卷积, 输入的 channels 是 ,输出的 channels 是 , 步长是 , 没有 padding
self.conv2 = nn.Sequential(
nn.Conv2d(, , , ),
nn.ReLU(True)) # 第四层是 3x3 的池化,步长是 ,没有 padding
self.max_pool2 = nn.MaxPool2d(, ) # 第五层是全连接层,输入是 ,输出是
self.fc1 = nn.Sequential(
nn.Linear(, ),
nn.ReLU(True)) # 第六层是全连接层,输入是 ,输出是
self.fc2 = nn.Sequential(
nn.Linear(, ),
nn.ReLU(True)) # 第七层是全连接层,输入是 ,输出是
self.fc3 = nn.Linear(, ) def forward(self, x):
x = self.conv1(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = self.max_pool2(x) # 将矩阵拉平
x = x.view(x.shape[], -)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x alexnet = AlexNet() writer = SummaryWriter('runs/exp1')
dummy_input = Variable(torch.zeros(, , , ))
with writer:
writer.add_graph(alexnet,dummy_input)
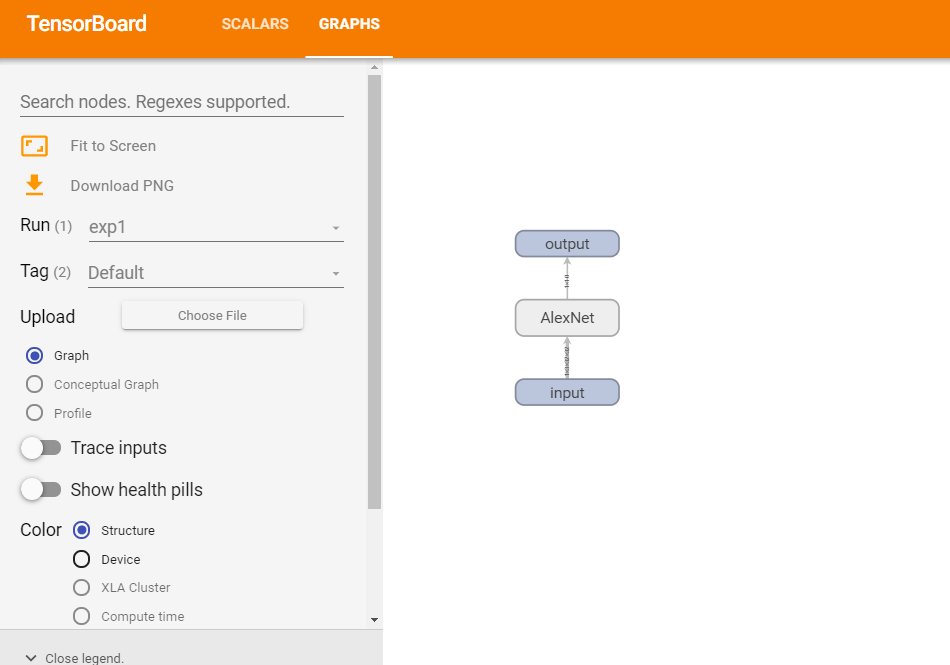
可在 GRAPHS 中看到 Resnet18 的网络拓扑
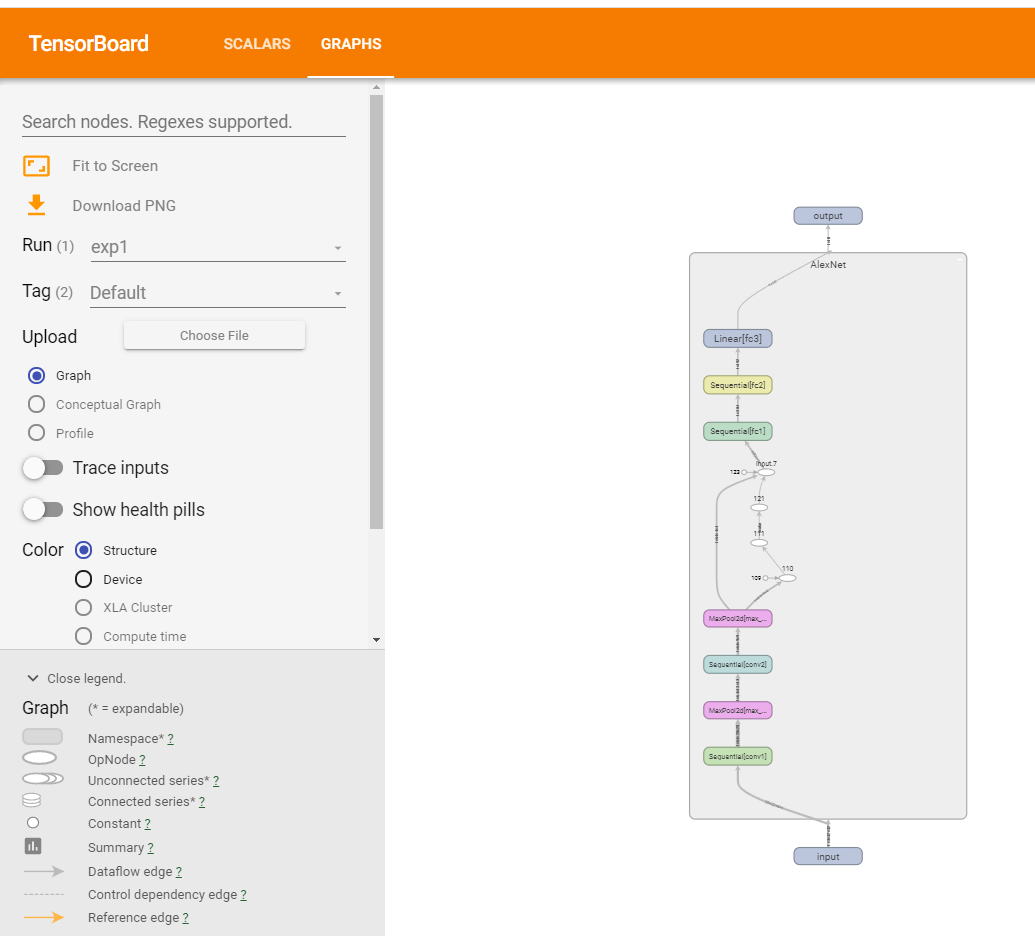
双击AlexNet
(7)add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='de
fault', metadata_header=None)
功能:
在三维空间或二维空间展示数据分布,可选 T-SNE、 PCA 和 CUSTOM 方法。
参数
mat(torch.Tensor or numpy.array)- 需要绘制的数据,一个样本必须是一个向量形式。
shape = (N,D), N 是样本数, D 是特征维数。
metadata(list)- 数据的标签,是一个 list,长度为 N。
label_img(torch.Tensor)- 空间中展示的图片, shape = (N,C,H,W)。
global_step(int)- Global step value to record,不理解这里有何用处呢?知道的朋友补
充一下吧。
tag(string)- 标签
(8)add_text(tag, text_string, global_step=None, walltime=None)
功能: 记录文字
(9)add_video(tag, vid_tensor, global_step=None, fps=4, walltime=None)
功能: 记录 video
(10)add_figure(tag, figure, global_step=None, close=True, walltime=None)
功能: 添加 matplotlib 图片到图像中
(11)add_image_with_boxes(tag, img_tensor, box_tensor, global_step=None, walltime
=None, **kwargs)
功能: 图像中绘制 Box,目标检测中会用到
(12)add_pr_curve(tag, labels, predictions, global_step=None, num_thresholds=127, w
eights=None, walltime=None)
功能: 绘制 PR 曲线
(13)add_pr_curve_raw(tag, true_positive_counts, false_positive_counts, true_negati
ve_counts, false_negative_counts, precision, recall, global_step=None, num_thres
holds=127, weights=None, walltime=None)
功能: 从原始数据上绘制 PR 曲线
(14)export_scalars_to_json(path)
功能: 将 scalars 信息保存到 json 文件,便于后期使用
注意:没有验证或者验证有问题参考官方链接
在pytorch下使用tensorboardX(win10;谷歌浏览器;jupyter notebook)的更多相关文章
- windows10 下安装tensorflow 并且在jupyter notebook 上使用tensorflow
一.安装jupyter notebook并配置环境 首先建议大家安装anaconda,最新版本请到官网下载(点击下载连接),没错,直接点击下载python3.6版本的(当然选择做自己电脑相应的位数,我 ...
- win10修改jupyter notebook默认路径
安装anaconda3 ,因此自带jupyter notebook 发送到jupyter notebook到桌面快捷方式 右击属性,将目标的%USERPROFILE%,修该为自己需要的路径 起始位置修 ...
- jupyter notebook下python2和python3共存(Ubuntu)
提示NOTICE 时间:2018/04/06 主题:Ubuntu 下CAFFE框架 主角:Jupyter Notebook 简介: Jupyter Notebook(此前被称为 IPython not ...
- 在Anaconda环境下使用Jupyter Notebook
!!!Anaconda 和 Jupyter Notebook 在 zsh 环境下不能正常使用! 启动建立的 Anaconda 环境 安装 nb_conda:conda install nb_conda ...
- 如何在任意文件下启动jupyter notebook,而不用担心环境配置问题
网上看了很多帖子,说可以写一个bat文件,将bat文件放在你想启动jupyter notebook的地方.可是不行,不能解决我的问题!!!!!!!!!!! 网上是这样说的: ######这为引用### ...
- Jupyter Notebook在多个虚拟环境配置与使用
1 问题描述 使用Anaconda配置了包括Pytorch.Tensorflow等多个虚拟环境后,依然无法使用Jupyter Notebook选择不同的虚拟环境运行代码,问题如下图所示. 2 解决方法 ...
- Jupyter Notebook 介绍 安装和使用技巧
Jupyter Notebook介绍.安装及使用教程 原文链接:https://www.jianshu.com/p/91365f343585 目录一.什么是Jupyter Notebook? 1. 简 ...
- 【Python】和【Jupyter notebook】的正确安装方式?
学了那么久Python,你的Python安装方式正确吗?今天给你看看什么才是Python正确的安装方式,教程放在下面了,喜欢的记得点赞. Python安装 Python解答Q群:660193417## ...
- win10下Anaconda 2 和 3 共存安装,并切换jupyter notebook和Pycharm中的对应版本
win10下Anaconda 2 和 3 共存安装,并切换jupyter notebook和Pycharm中的对应版本 zoerywzhou@163.com http://www.cnblogs.co ...
随机推荐
- 搭建Hadoop集群需要注意的问题:
搭建Hadoop集群需要注意的问题: 1.检查三台主机名是否正确 2.检查三台IP是否正确 3.检查 /etc/hosts 映射是否正确 4.检查 JDK和Hadoop 是否安装成功(看环境变量配置) ...
- 微信小程序分享转发用法大全——自定义分享、全局分享、组合分享
官方提供的自定义分享 使用隐式页面配置函数实现的全局分享-推荐 使用隐式路由实现的全局分享-不推荐,仅供了解隐式路由 前言: 目前微信小程序只开放了页面自定义分享的API,为了能够更灵活的进行分享配置 ...
- Ceph学习笔记(2)- CRUSH数据分布算法
前言: 分布式存储系统需要让数据均匀的分布在集群中的物理设备上,同时在新设备加入,旧设备退出之后让数据重新达到平衡状态尤为重要.新设备加入后,数据要从不同的老设备中迁移过来.老设备退出后,数据迁移 ...
- adb的多种连接方式(二)
一,设备连接 1,USB数据线连接 win10下USB连接Android 1.手机端的设置,以红米4为例: a.打开开发者模式,小米手机打开开发者模式方法为,连续点击MIUI版本,就可以进入开发者模式 ...
- Springcloud zuul 实现API 网关
1,https://github.com/Netflix/zuul zuul 网关文档 2,什么是网关 网关就是客户端进行访问的时候,先经过网关服务器,再由网关服务器进行转发到真实的服务器.类似于Ng ...
- iOS 引用计数
一.简介 OC 在创建对象时,不会直接返回该对象,而是返回一个指向对象的指针. OC 在内存管理上采用了引用计数,它是一个简单而有效管理对象生命周期的方式.在对象内部保存一个用来表示被引用次数的数字, ...
- css中border-sizing属性详解和应用
box-sizing用于更改用于计算元素宽度和高度的默认的 CSS 盒子模型.它有content-box.border-box和inherit三种取值.inherit指的是从父元素继承box-sizi ...
- Redis 笔记(一)——数据类型简介
Redis 是一个 key-value 存储系统,但是它的 value 值不仅仅可以存储字符串,value 共有 五种 数据结构类型,具体如下: 数据结构类型 结构类型 结构存储的值 结构的读写能力 ...
- DOS命令集
1.ASSOC显示或修改文件扩展名关联.ASSOC [.ext[=[fileType]]] .ext 指定跟文件类型关联的文件扩展名 fileType 指定跟文件扩展名关联的文件类型键 ...
- 数据库学习 day1 认识数据库
从SQL的角度而言,数据库是一个以某种有组织的方式储存的数据集合. 我们可以把它比作一个“文件柜”,这个“文件柜”是一个存放数据的物理位置,不管数据是什么,也不管数据是如何组织的. 下面介绍几个术语 ...