降维之奇异值分解(SVD)
看了几篇关于奇异值分解(Singular Value Decomposition,SVD)的博客,大部分都是从坐标变换(线性变换)的角度来阐述,讲了一堆坐标变换的东西,整了一大堆图,试图“通俗易懂”地向读者解释清楚这个矩阵分解方法。然而这个“通俗易懂”到我这就变成了“似懂非懂”,这些漂亮的图可把我整懵了。
就像《没想到吧》里王祖蓝对一个碎碎念的观众说的,“我问你的问题是,你是很熟悉邓紫棋的歌吗,我只问了你一个问题,你回我这么多干嘛”(上B站忍不住又看了邓紫棋3个视频,差点回不来)。我就想知道这个奇异值分解的数学公式是什么,然后明白它是怎么一步步推导出来的,以及怎么推导出奇异值分解和主成分分析法的关系,咋就要整这么多图呢?
如果你也有这种感觉,那这篇博客就带着你,以数学推导为主,一步步搞清楚奇异值分解是什么。这篇博客反其道而行之,全是数学推导,没有一个图,就是这么任性。当然相信我,这些推导并不难。
这篇博客整理如下的内容:
1、奇异值分解的数学公式;
2、奇异值分解的流程总结和案例;
3、用奇异值分解进行降维;
4、特征分解、奇异值分解和主成分分析法的关系;
5、奇异值分解在词向量降维中的应用。
一、奇异值分解的数学公式
我们直接抛出相关结论,不推导也不证明。
一个n×m的矩阵X的奇异值分解定义为:

其中U称为左奇异矩阵,是一个n×n的正交矩阵,即满足UTU=E,UT=U-1;而V称为右奇异矩阵,是一个m×m的正交矩阵。Σ为n×m的对角矩阵,对角线上的非零元素是奇异值(Singular Value)。
1、求奇异值
首先看Σ或者说奇异值是什么。如果矩阵X的秩rank(A)=r,那么实对称矩阵XTX与X的秩相等,XTX有r个非零的特征值和m-r个零特征值:λ1≥λ2≥ λ3...≥λr>λr+1=...=λm=0。奇异值σ为:

矩阵Σ可以表示为:
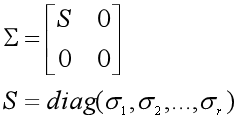
2、求右奇异矩阵V
然后看右奇异矩阵V是什么。将V写成列向量的形式(v1, v2, ...vr,.. vm),那么V的列向量是实对称矩阵XTX的单位特征向量,也就是有:
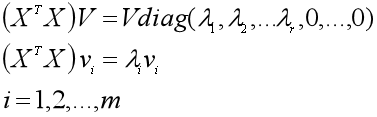
3、求左奇异矩阵U
(1)第一种做法
第一种做法更多是为了与右奇异矩阵V的求法相对应,实际计算时会采用另外的方法。前面说了实对称矩阵XTX与X的秩相等,有r个非零特征值,那么另一个实对称矩阵XXT与XTX的秩相等,同样有r个非零特征值,且这两个矩阵的非零特征值相等。将U也写成列向量的形式(u1, u2, ...ur,.. un),那么U的列向量是实对称矩阵XXT的单位特征向量,也就是有:

看到这里,虽然不知道这是怎么推导过来的,但是感受到了一种强烈的数学之美,有没有!
(2)第二种做法
在第二种做法中,我们会充分利用实对称矩阵XTX与右奇异矩阵V,来求得左奇异矩阵U,而不用另外去求XXT的单位特征向量。我们首先把XTX的特征值分为两组:特征值大于零的一组(r个),特征值等于零的一组(m-r个),相应的把右奇异矩阵的列向量分为两组:前r个非零特征值对应的单位特征向量为V1=(v1, v2, ...vr),而零特征值对应的单位特征向量为V2=(vr+1,.. vm)。再把左奇异矩阵U的列向量也分为两组,尽管我们还不知道具体的元素值,但是我们知道它有n个列向量:前r个列向量U1=(u1, u2, ...ur),后n-r个列向量U2=(ur+1, ur+2, ...un)。那么我们可以用X、V1和奇异值构成的对角阵方阵S来求出U1。
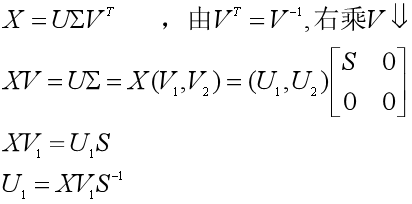
由第一种做法我们已知U1是XXT非零特征值的单位特征向量,那么U2就是零特征值的单位特征向量了。我们不用去求U2,只要构造n-r个列向量,每一个列向量满足:与其他n-1个列向量正交,且是单位向量——这通常是比较容易构造的。于是我们就得到了左奇异矩阵U=(U1, U2)。
我们还可以证明一下,由XV1S-1所得到的U1的确满足:列向量相互正交且为单位向量。这个证明很有用,并不复杂。

二、奇异值分解的流程和案例
好,有了第一部分的内容,那尽管我们不知道怎么推导出来的,我们也已经知道如何进行奇异值分解了。
1、奇异值分解的计算过程
如果有一个n×m的矩阵X,秩为r,那么对X进行奇异值分解的一种做法是:
(1)求出实对称矩阵XTX的m个特征值λi(其中非零的有r个)和m个单位特征向量vi,
(2)把m个特征值λi从大到小排序,求出奇异值σi=√λi(i=1,...,r),并得到S=diag(σ1,σ2,...,σr);
(3)相应地把m个特征向量vi进行排列,就可以得到右奇异矩阵V=(v1, v2, ...vr,.. vm),同时得到非零特征值的特征向量矩阵V1=(v1, v2, ...vr);
(4)由XV1S-1求出n×r的矩阵U1,写成U1=(u1, u2, ...ur);
(5)构造n-r个列向量ui,每个都满足与其他n-1个列向量正交且是单位向量的条件,写成U2=(ur+1, ur+2, ...un),于是得到左奇异矩阵U=(U1, U2)=(u1, u2, ... ur, ..., un);
(6)得到X的奇异值分解:
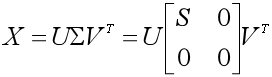
接下来我们就举一个简单的例子,按这个流程走一遍。
2、奇异值分解的小案例
问题:
对以下的矩阵X进行奇异值分解。
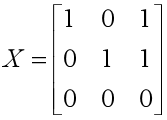
求解:

三、用奇异值分解做降维
用奇异值分解做降维,主要用到了线性代数里的分块矩阵理论。
1、简化奇异值分解
我们可以看到矩阵Σ由奇异值和很多0元素构成,这些0看着很多余很难受对不对?尤其是对角线上的!所幸我们可以用分块矩阵的理论,把Σ中为0的对角元素抛弃掉。
和之前一样,X是n×m的矩阵,右奇异矩阵V中的前r个列向量为V1=(v1, v2, ...vr),左奇异矩阵U中的前r个列向量为U1=(u1, u2, ...ur),S=diag(σ1,σ2,...,σr)是奇异值构成的对角矩阵。则可以将奇异值分解的形式化简为X=U1SV1T。

2、用奇异值分解降维
我们是用分块矩阵对原来的奇异值分解形式进行化简的,现在让我们分块到底!
我们知道U1中有r个列向量,我们再将其分块,比如我们想把维度降到d维(d<r),那么把U1分块为两个子矩阵U1=[U11, U12],有U11=[u1,u2,...,ud],U12=[ud+1,ud+2,...,ur]。
同样把V1进行分块,得到V1=[V11, V12],V11=[v1,v2,...,vd],V12=[vd+1,vd+2,...,vr]。
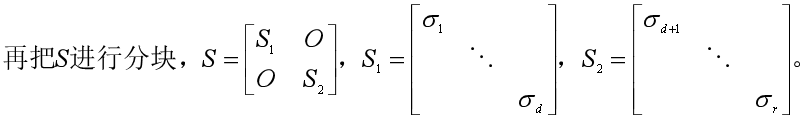
于是我们可以把X=U1SV1T也分块成:
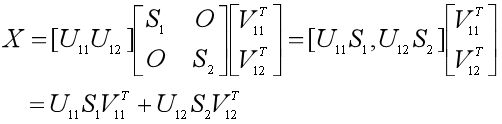
因此如果我们想把维度降到d维,那么就让X≈U11S1V11T。这样我们就舍弃了r-d维的信息U12S2V12T,那不免让人担心,信息是否会损失太多。那如何计算损失的信息量呢?
3、度量降维后的信息量
在主成分分析法的文章中,提到了可以用数据集的方差来衡量数据所包含的信息量,方差越大,包含的信息越多。而方差又和特征值密切相关,在某些特殊情况下方差就等于特征值。于是我们隐约感觉到可以用我们求出来的奇异值或者特征值来度量矩阵的信息量。
是的,矩阵X的信息量就定义为所有奇异值的平方和,也就是XTX的特征值之和:F=λ1+λ2+…+λr。
那么降维后的矩阵U11S1V11T的信息量为:F1=λ1+λ2+…+λd,而损失的信息为矩阵U12S2V12T的信息量:F2=λd+1+λd+2+…+λr。
于是损失的信息量占总信息量的比例为:

这样我们就可以清晰地看到降到d维后,信息量是否损失太大,是否让我们无法承受。不过好在S中的奇异值是从大到小进行排列的,而且一般下降得特别快,前面少数几个奇异值的平方占总信息量的比例一般就已经很大了,剩下的舍弃了影响也不会很大。
好,到这里我们就明白了怎么度量降维后的矩阵所包含的信息量了。
然后,作为好奇宝宝的你也许会问,为什么矩阵X的信息量就是所有奇异值的平方和呢?好的,邓紫棋已经听到你的呼唤了,返场唱最后一首歌。这里是用矩阵X的F范数的平方来度量信息量。
什么是矩阵的F范数呢?矩阵的F范数定义为矩阵中每个元素平方之和的平方根,那么F范数的平方就是每个元素的平方和。
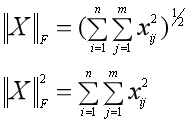
因为矩阵X每个元素的平方和(F范数的平方)是方阵XTX的对角线元素之和(迹),于是我们进行证明:

其实不证明我们也知道方阵XTX的对角线元素之和(迹)就是其特征值之和,哈哈哈,被我带偏了。
四、特征分解、奇异值值分解与主成分分析法
1、由特征分解到奇异值分解
(1)什么是特征分解
一个n×n的方阵A的特征分解(Eigenvalue Decomposition )定义为:
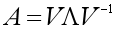
其中V是n×n的方阵,其中每一列都是A的特征向量,∧是对角阵,其中每一个元素是A的特征值。
如果A是对称矩阵,那么A的特征分解就变成了:
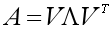
其中V是正交矩阵,即V-1=VT。注意是方阵才可以进行特征分解哦。
(2)推导奇异值分解
如果有一个n×m的矩阵X,我们是没法对X进行特征分解的,那么怎么由特征分解推导出奇异值分解呢?
我们注意到XTX是m×m实对称矩阵,于是先对XTX进行特征分解:
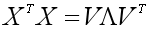
V的列向量是单位特征向量,对角阵∧中的对角元素是特征值,且我们对特征值进行降序排列。假设X的秩为r,那么非零的特征值有r个。
V中的列向量(v1, v2, ...vr,.. vm)可以看成是m维空间中的m个标准正交基。XTX特征分解就相当于一个线性变换,用标准正交基构成的矩阵V对对角矩阵进行线性变换,得到XTX。
那么n×m的矩阵X应该也可以由一个n维空间中的n个标准正交基和一个m维空间中的m个标准正交基,对某个矩阵进行线性变换得到。我们想办法来找到这些标准正交基。
我们就让XTX的单位特征向量V=(v1, v2, ...vr,.. vm)作为m个标准正交基,再找另外n个标准正交基。瞎折腾了一阵后,突然发现Xvi与Xvj是正交的!
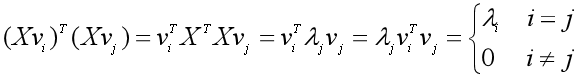
太好了!这意味着只要我们把(Xv1,Xv2,..., Xvm)中的非零列向量进行标准化,就可以得到另一组标准正交基了!如果X的秩为r,那么非零列向量是(Xv1,Xv2,..., Xvr)(我不知道这怎么来的,装逼失败),且满足:

于是我们对Xvi进行标准化:
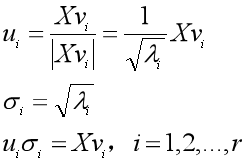
得到了r个标准正交基(u1, u2, ... ur),可是我们需要n个,还少了n-r个。没关系,我们直接找任意n-r个列向量,填补上去,使得U=(u1, u2, ... ur, ..., un)是一组标准正交基。σi是奇异值,我们用σi作为对角元素来构造一个n×m维的矩阵Σ,那么X就可以用U和V这两个标准正交基组对Σ进行线性变换得到,也就是奇异值分解:X=UΣVT。
2、奇异值分解与主成分分析法
奇异值分解是主成分分析法的一种常用的解决方案。如果数据集X是一个n×m的矩阵,n是变量的个数,m是样本的数量,那么进行主成分分析,也就是用奇异值分解的左奇异矩阵或者右奇异矩阵的装置作为主成分分析法中的转换矩阵,去乘以数据集X,从而得到主成分矩阵Y。
(1)为什么用奇异值分解
可是在《降维之主成分分析法(PCA)》中,我们明白了,可以求出X的协方差矩阵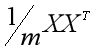 的单位特征向量矩阵E,用E的转置ET作为转换矩阵P,然后由PX=Y得到主成分矩阵,再挑出前k主成分就可以做到降维。那我们直接去求E不就好了吗?干嘛还要把奇异值分解拉扯进来?
的单位特征向量矩阵E,用E的转置ET作为转换矩阵P,然后由PX=Y得到主成分矩阵,再挑出前k主成分就可以做到降维。那我们直接去求E不就好了吗?干嘛还要把奇异值分解拉扯进来?
这是因为求解n维矩阵XXT的特征值和特征向量的算法复杂度为O(n3),因此如果X是高维的数据,也就是n非常大时,进行主成分分析就要计算超大矩阵的特征值。这就出现了算法复杂度过高,计算效率太低的问题。
可是奇异值分解也要对矩阵XTX进行特征分解来求右奇异矩阵V啊,算法复杂度不也是O(n3)?是这样的,不过对高维矩阵进行奇异值分解时,有一些更高效的算法,不用采取暴力特征分解的方式。
(2)奇异值分解与主成分分析法等价
我们先按照主成分分析法的步骤,对XXT进行特征分解,得到:

然后对X进行奇异值分解,沿用前面的符号体系,得到X=UΣVT,把X的奇异值分解代入到上面的特征分解式中:

由于在主成分分析法中我们用ET作为转换矩阵P,那么从上面的推导可知,可以用X的左奇异矩阵U的转置UT作为转换矩阵P,来求出主成分矩阵Y,UTX=Y。
(3)用奇异值分解做主成分降维
X的奇异值分解还可以简化地写成X=U1SV1T,同样代入XXT的特征分解中,得到:XXT=U1SSTU1T。U1=(u1, u2, ...ur)是n×r的矩阵,那么U1T是一个r×n的矩阵,U1TX就把X的特征从n维降至了r维。
进一步,我们在前面用分块矩阵的思想,把U1分块为U1=[U11, U12],U11T是一个d×n维的矩阵,那么用U11T作为转换矩阵,就可以把X的特征进一步压缩至d维。
(4)其他补充
如果你看了其他博主写的博客,会发现有些是用右奇异矩阵V的转置VT来作为特征压缩的转换矩阵,和本文不一样。这是因为那些博客把有m个样本,n维特征的数据集写成了m×n的矩阵X,而本文把数据集写成n×m的矩阵,所以那些博客是用右奇异矩阵V,而本文是用左奇异矩阵U。
五、奇异值分解与词向量降维
我们来看怎么把奇异值分解用在词向量降维上。如果我们手头有一份文本数据集,里头有m篇文档,总共有n个不重复的词,那么我们可以通过统计文档中所有词出现的次数,整理成一个矩阵X,来构造词向量。
一般有两种方法来构造词向量矩阵:一是TF-IDF,词向量矩阵是n×m维的,行向量是每个词的词向量;二是基于窗口的共现矩阵,如果窗口是1,那么词向量矩阵是n×n维的,行向量是每个词的词向量。这两种词向量的表示方法存在很大的问题,那就是数据稀疏和词表维度过高。想象一下,如果文档有10万篇,词有5万个,那会是多么恐怖的一个场景。
因此我们非常有必要运用奇异值分解,对词向量矩阵进行降维。
1、对TF-IDF词向量矩阵进行降维
TF-IDF不用多解释了,由每个词的词频和逆文档频率两部分计算得到每个词的TF-IDF,然后所有词的TF-IDF构成词向量矩阵Xn×m。这个矩阵太大了,我们对这个矩阵X进行奇异值分解得到U1SV1T,U1是n×r的矩阵,我们用U1的行向量作为n个词的词向量,就实现了对文档数量维度的压缩。
如果还嫌词表维度太高,那么我们可以继续降维,从U1中拿出前d个列向量,组成新的n×d维的词向量矩阵U11,行向量作为降到d维后每个词的词向量。
d取多少合适呢?我们可以用奇异值的平方和计算降到d维后的剩余的信息量。如果我们希望保留85%的信息,那么就取以下公式大于或等于85%时的d值,作为降维后的维度。
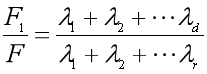
2、对基于窗口的共现矩阵进行降维
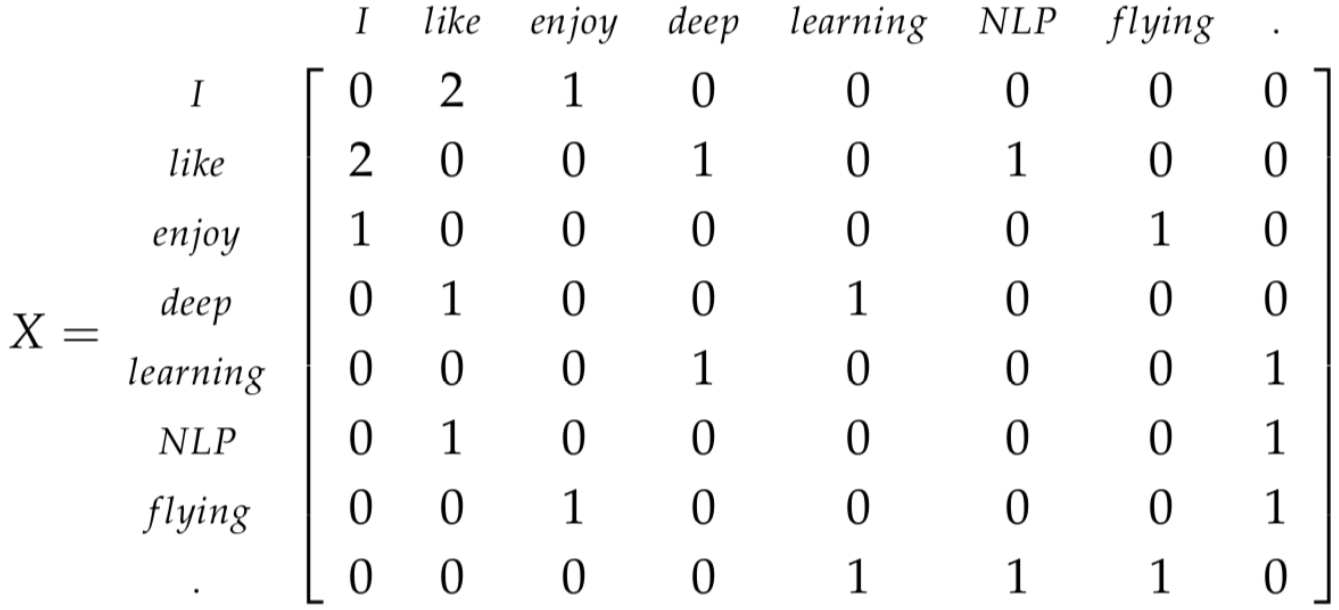
这种方法是用一个相关性矩阵来构造词向量矩阵,叫做共现矩阵。 假设有3个句子(看成三篇文档也没毛病),一共8个不重复的词(把标点也算上),窗口设定为1,也就是把句子拆成一个个的词。
- I enjoy flying.
- I like NLP.
- I like deep learning
那么共现矩阵就是一个8维的方阵X:
同样用奇异值分解,把X分解为X=U1SV1T,然后用U1的行向量作为每次词的词向量,就把词向量的维度从n维降到了r维。如果觉得还太高了,那么可以按照TF-IDF中的做法,继续进行降维。
参考资料:
1、《A Tutorial on Principal Component Analysis. Derivation, Discussion and Singular Value Decomposition》
2、《A Singularly Valuable Decomposition: The SVD of a Matrix 》
降维之奇异值分解(SVD)的更多相关文章
- 第十四章:降维:奇异值分解SVD
- 一步步教你轻松学奇异值分解SVD降维算法
一步步教你轻松学奇异值分解SVD降维算法 (白宁超 2018年10月24日09:04:56 ) 摘要:奇异值分解(singular value decomposition)是线性代数中一种重要的矩阵分 ...
- 机器学习实战(Machine Learning in Action)学习笔记————10.奇异值分解(SVD)原理、基于协同过滤的推荐引擎、数据降维
关键字:SVD.奇异值分解.降维.基于协同过滤的推荐引擎作者:米仓山下时间:2018-11-3机器学习实战(Machine Learning in Action,@author: Peter Harr ...
- 机器学习降维方法概括, LASSO参数缩减、主成分分析PCA、小波分析、线性判别LDA、拉普拉斯映射、深度学习SparseAutoEncoder、矩阵奇异值分解SVD、LLE局部线性嵌入、Isomap等距映射
机器学习降维方法概括 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014772862/article/details/52335970 最近 ...
- 【疑难杂症】奇异值分解(SVD)原理与在降维中的应用
前言 在项目实战的特征工程中遇到了采用SVD进行降维,具体SVD是什么,怎么用,原理是什么都没有细说,因此特开一篇,记录下SVD的学习笔记 参考:刘建平老师博客 https://www.cnblogs ...
- [机器学习笔记]奇异值分解SVD简介及其在推荐系统中的简单应用
本文先从几何意义上对奇异值分解SVD进行简单介绍,然后分析了特征值分解与奇异值分解的区别与联系,最后用python实现将SVD应用于推荐系统. 1.SVD详解 SVD(singular value d ...
- 奇异值分解(SVD)原理详解及推导(转载)
转载请声明出处http://blog.csdn.net/zhongkejingwang/article/details/43053513 在网上看到有很多文章介绍SVD的,讲的也都不错,但是感觉还是有 ...
- 奇异值分解(SVD)原理详解及推导 (转载)
转载请声明出处http://blog.csdn.net/zhongkejingwang/article/details/43053513 在网上看到有很多文章介绍SVD的,讲的也都不错,但是感觉还是有 ...
- 奇异值分解(SVD)详解
在网上看到有很多文章介绍SVD的,讲的也都不错,但是感觉还是有需要补充的,特别是关于矩阵和映射之间的对应关系.前段时间看了国外的一篇文章,叫A Singularly Valuable Decompos ...
随机推荐
- [aac @ ...] Specified sample format s16 is invalid or not supported
在使用FFmpeg打开编码器的时候出现以下错误: [aac @ 000001da19fd7200] Specified sample format s16 is invalid or not supp ...
- C# String 字符串一些关键理解
#1 :在.Net Framework中,字符总是表示成16位Unicode的代码#2 :String 和string 其实是一样的只是表现形式上不同#3 :string类型被视为基元类型,也就是编译 ...
- 图论初步<蒟蒻专属文章>
前言: 图论乃noip之重要知识点,但有点难理解 本人因此吃过不少亏 因为本人实在太弱,所以此篇乃正宗<蒟蒻专属文章> 正文:(本文仅介绍图论中的重点.难点,其余部分略将或不讲) 图 ...
- pytest+allure(pytest-allure-adaptor基于这个插件)设计定制化报告
一:环境准备 1.python3.6 2.windows环境 3.pycharm 4.pytest-allure-adaptor 5.allure2.8.0 6.java1.8 pytest-allu ...
- ionic3记录之弹窗Alert
一个业务流程需要多个弹窗: 在上一个弹窗的onDidDissmiss写下一个弹窗:
- java学习-初级入门-面向对象④-类与对象-类与对象的定义和使用2
我们继续学习类与对象,上一篇我们定义了 坐标类(Point), 这次我们在Point的基础上,创建一个圆类(Circle). 案例:创建一个圆类 题目要求: 计算圆的周长和面积:求判断两个圆的位置关 ...
- Celery的常用知识
什么是Clelery Celery是一个简单.灵活且可靠的,处理大量消息的分布式系统.专注于实时处理的异步任务队列.同时也支持任务调度. Celery的架构由三部分组成,消息中间件(message ...
- angularJS MVVM
- 关于Tomcat部署项目的点点滴滴
在给客户部署环境时,我们不可能想开发一样,在编辑软件部署一下tomcat就可以正常运行.我们也应该清楚java的运行机制**“先编译,后解释”**的原则.(如下图)![图片描述][1]那么在Tomca ...
- 2-10 就业课(2.0)-oozie:13、14、clouderaManager的服务搭建
3.clouderaManager安装资源下载 第一步:下载安装资源并上传到服务器 我们这里安装CM5.14.0这个版本,需要下载以下这些资源,一共是四个文件即可 下载cm5的压缩包 下载地址:htt ...