Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍
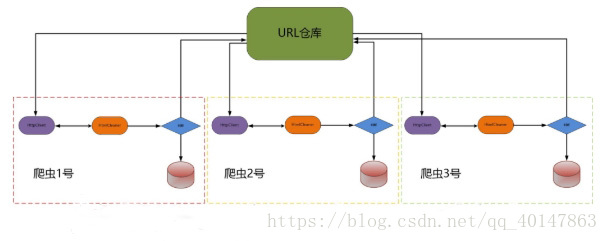
- 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫
什么是分布式爬虫
- 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集。单机爬虫就是只在一台计算机上的爬虫。
- 其实搜索引擎都是爬虫,负责从世界各地的网站上爬取内容,当你搜索关键词时就把相关的内容展示给你,只不过他们那都是灰常大的爬虫,爬的内容量也超乎想象,也就无法再用单机爬虫去实现,而是使用分布式了,一台服务器不行,我来1000台。我这么多分布在各地的服务器都是为了完成爬虫工作,彼此得通力协作才行啊,于是就有了分布式爬虫
- 单机爬虫的问题:
- 一台计算机的效率问题
- IO 的吞吐量,传输速率也有限
- 多爬虫问题
- 多爬虫要实现数据共享
- 比如说一个爬取了某个网站,下载了哪些内容,其他爬虫要知道,以避免重复爬取等很多问题,所以要实现数据共享
- 在空间上不同的多台机器,可以成为分布式
- 多爬虫要实现数据共享
- 多爬虫条件:
- 需要共享队列
- 去重,让多个爬虫不爬取其他爬虫爬取过的爬虫
- 理解分布式爬虫:
- 假设上万的 url 需要爬取,有 100 多个爬虫,分布在全国不同的城市
- url 被分给不同的爬虫,但是不同爬虫的效率又是不一样的,所以说共享队列,共享数据,让效率高的爬虫多去做任务,而不是等着效率低的爬虫
- Redis
- Redis 是完全开源免费的,遵守BSD协议,是一个高性能的 key-value 数据库
- 内存数据库,数据存放在内存
- 同时可以落地保存到硬盘
- 可以去重
- 可以把 Redis 理解成一共 dict,set,list 的集合体
- Redis 可以对保存的内容进行生命周期
- Redis 教程:Redis 教程 - 菜鸟教程
- 内容保存数据库
- MongoDB,运行在内存,数据保存在硬盘
- MySQL
- 等等
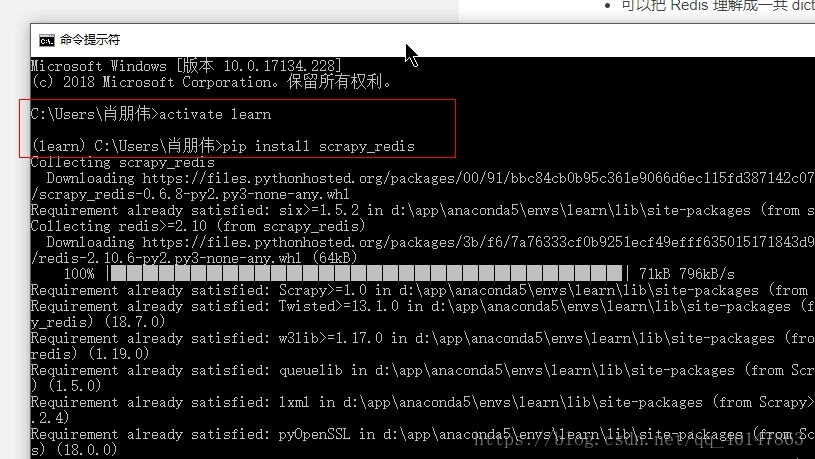
安装 scrapy_redis
- 1.打开【cmd】
- 2.进入使用的 Anaconda 环境
- 3.使用 pip 安装
- 4.操作截图
分布式爬虫的结构
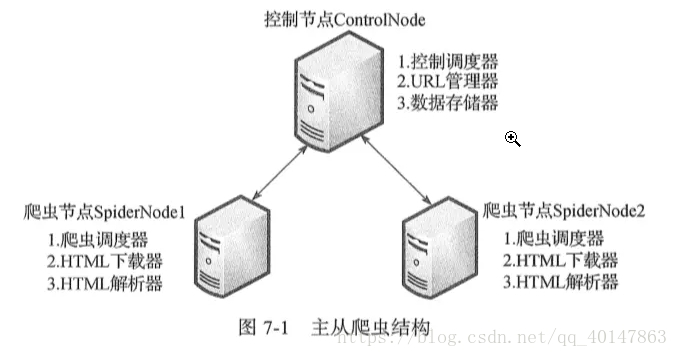
主从分布式爬虫
- 所谓主从模式,就是由一台服务器充当 master,若干台服务器充当 slave,master 负责管理所有连接上来的 slave,包括管理 slave 连接、任务调度与分发、结果回收并汇总等;每个 slave 只需要从 master 那里领取任务并独自完成任务最后上传结果即可,期间不需要与其他 slave 进行交流。这种方式简单易于管理,但是很明显 master 需要与所有 slave 进行交流,那么 master 的性能就成了制约整个系统的瓶颈,特别是当连接上的slave数量庞大的时候,很容易导致整个爬虫系统性能下降
- 主从分布式爬虫结构图:
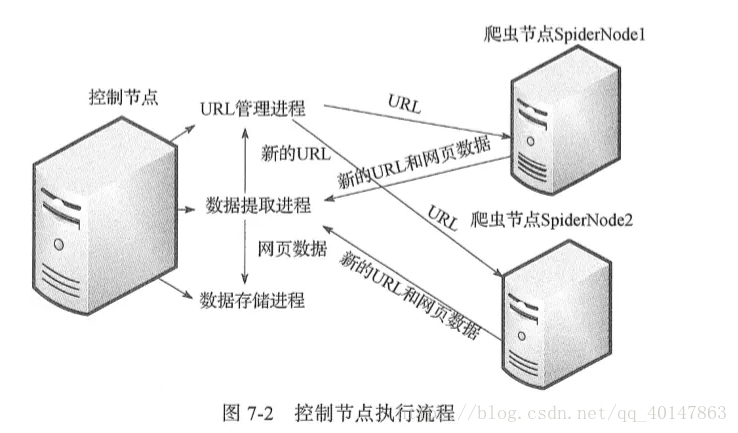
这是经典的主从分布式爬虫结构图,图中的控制节点ControlNode就是上面提到的master,爬虫节点SpiderNode就是上面提到的slave。下面这张图展示了爬虫节点slave的执行任务示意图 - 控制节点执行流程图:
- 这两张图很明了地介绍了整个爬虫框架,我们在这里梳理一下:
- 1.整个分布式爬虫系统由两部分组成:master控制节点和slave爬虫节点
- 2.master控制节点负责:slave节点任务调度、url管理、结果处理
- 3.slave爬虫节点负责:本节点爬虫调度、HTML下载管理、HTML内容解析管理
- 4.系统工作流程:master将任务(未爬取的url)分发下去,slave通过master的URL管理器领取任务(url)并独自完成对应任务(url)的HTML内容下载、内容解析,解析出来的内容包含目标数据和新的url,这个工作完成后slave将结果(目标数据+新url)提交给master的数据提取进程(属于master的结果处理),该进程完成两个任务:提取出新的url交于url管理器、提取目标数据交于数据存储进程,master的url管理进程收到url后进行验证(是否已爬取过)并处理(未爬取的添加进待爬url集合,爬过的添加进已爬url集合),然后slave循环从url管理器获取任务、执行任务、提交结果......
- 本篇就介绍到这里了
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
Python爬虫教程-34-分布式爬虫介绍的更多相关文章
- Python爬虫教程-新浪微博分布式爬虫分享
爬虫功能: 此项目实现将单机的新浪微博爬虫重构成分布式爬虫. Master机只管任务调度,不管爬数据:Slaver机只管将Request抛给Master机,需要Request的时候再从Master机拿 ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- Scrapy 教程(八)-分布式爬虫
scrapy 本身并不是一个分布式框架,而 Scrapy-redis 库使得分布式成为可能: Scrapy-redis 并没有重构框架,而是基于redis数据库重写了框架的某些组件. 分布式框架要解决 ...
- [scrapy-redis] 将scrapy爬虫改造成分布式爬虫 (2)
1. 修改redis设置 redis默认处在protection mode, 修改/etc/redis.conf, protected-mode no, 或者给redis设置密码, 将bind 127 ...
- 大爽Python入门教程 3-4 实践例题
大爽Python入门公开课教案 点击查看教程总目录 1. 求和 使用循环,计算列表所有项的和,并输出这个和. 列表示例 lst = [8, 5, 7, 12, 19, 21, 10, 3, 2, 11 ...
- python3 分布式爬虫
背景 部门(东方IC.图虫)业务驱动,需要搜集大量图片资源,做数据分析,以及正版图片维权.前期主要用node做爬虫(业务比较简单,对node比较熟悉).随着业务需求的变化,大规模爬虫遇到各种问题.py ...
- 分布式爬虫系统设计、实现与实战:爬取京东、苏宁易购全网手机商品数据+MySQL、HBase存储
http://blog.51cto.com/xpleaf/2093952 1 概述 在不用爬虫框架的情况,经过多方学习,尝试实现了一个分布式爬虫系统,并且可以将数据保存到不同地方,类似MySQL.HB ...
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
随机推荐
- 基础篇:3)规范化:3d制图总章
本章目的:明确3d绘图也有相应的准则,遵守者方有相应的进阶之路. 1.建模目标:拥有自己的建模思想 学习完成3d制图,最直接的评价标准就是--拥有自己的建模思想. 其表现为: 1)建模思路明确,能独立 ...
- CF1067D. Computer Game(斜率优化+倍增+矩阵乘法)
题目链接 https://codeforces.com/contest/1067/problem/D 题解 首先,如果我们获得了一次升级机会,我们一定希望升级 \(b_i \times p_i\) 最 ...
- Codeforces - tag::data structures 大合集 [占坑 25 / 0x3f3f3f3f]
371D 小盘子不断嵌套与大盘子,最后与地面相连,往里面灌水,溢出部分会往下面流,求每次操作时当前的盘子的容量 其实这道题是期末考前就做好了的.. 链式结构考虑并查集,然后没了(求大佬解释第一个T的点 ...
- Javascript 定时器的使用陷阱 (setInterval)
setTimeout(function(){ // 其他代码 setTimeout(arguments.callee, interval); }, interval); setInterval会产生回 ...
- MySQL保留字冲突 关键词:保留字, 关键字
在Mysql中,当表名或字段名乃至数据库名和保留字冲突时,在sql语句里可以用撇号`(Tab键上方的按键)括起来. 注意,只有保留字需要``括起来,非保留字的关键字不需要. MySQL 8.0 官方文 ...
- google +ubuntu16.04
1.在终端中输入以下命令 sudo wget https://repo.fdzh.org/chrome/google-chrome.list -P /etc/apt/sources.list.d/ 2 ...
- Mongodb利用aggregation实现抽样查询(按记录数和时间)
之前对mongodb不熟,但是项目要用,因为数据量比较大,并且领导要实现抽样查询,控制数据流量,所以自己研究了下,亲测可用,分享一下! 话不多说,上代码: 第一种方案:加自增主键,实现按记录数抽样 1 ...
- oracle 表空间tablespace
一.Oracle 表空间的组成 Everoone knows Oracle数据库真正存放数据的是数据文件,Oracle表空间是逻辑上的概念,他在物理上是并不存在的,把多个DataFile合并到一起就是 ...
- dubbo序列化hibernate.LazyInitializationException could not initialize proxy - no Session懒加载异常的解决
dubbo序列化,hibernate.LazyInitializationException could not initialize proxy - no Session懒加载异常的解决 转载声明: ...
- 等待页面元素(webdriverwait)
前言 在脚本中加入太多的 sleep 后会影响脚本的执行速度,虽然 implicitly_wait ()这种方法隐式等待方法一定程度上节省了很多时间.但是一旦页面上某些 js 无法加载出来(其实界面元 ...