在线问诊 Python、FastAPI、Neo4j — 生成 Cypher 语句
这边只是为了测试,演示效果和思路,实际应用中,可以通过NLP构建CQL
接上一篇的问题分类
question = "请问最近看东西有时候清楚有时候不清楚是怎么回事"
# 最终输出
data = {'args': {'看东西有时候清楚有时候不清楚': ['symptom']}, 'question_types': ['symptom_disease']}
question = "干眼常用药有哪些"
# 最终输出
data = {'args': {'干眼': ['disease']}, 'question_types': ['disease_drug']}
question = "干眼哪些不能吃"
data = {'args': {'干眼': ['disease']}, 'question_types': ['disease_not_food']}
构建节点字典
目的,为了拼CQL,查出符合条件的节点详情
def build_nodedict(self, args):
"""
构建节点字典
:param args: {'看东西有时候清楚有时候不清楚': ['symptom']}
:return: 组装成 => {'symptom': '看东西有时候清楚有时候不清楚'}
"""
node_dict = {}
for arg, types in args.items():
for type in types:
if type not in node_dict:
node_dict[type] = [arg]
else:
node_dict[type].append(arg)
return node_dict
# 输入:
{'看东西有时候清楚有时候不清楚': ['symptom']}
# 输出:
{'symptom': ['看东西有时候清楚有时候不清楚']}
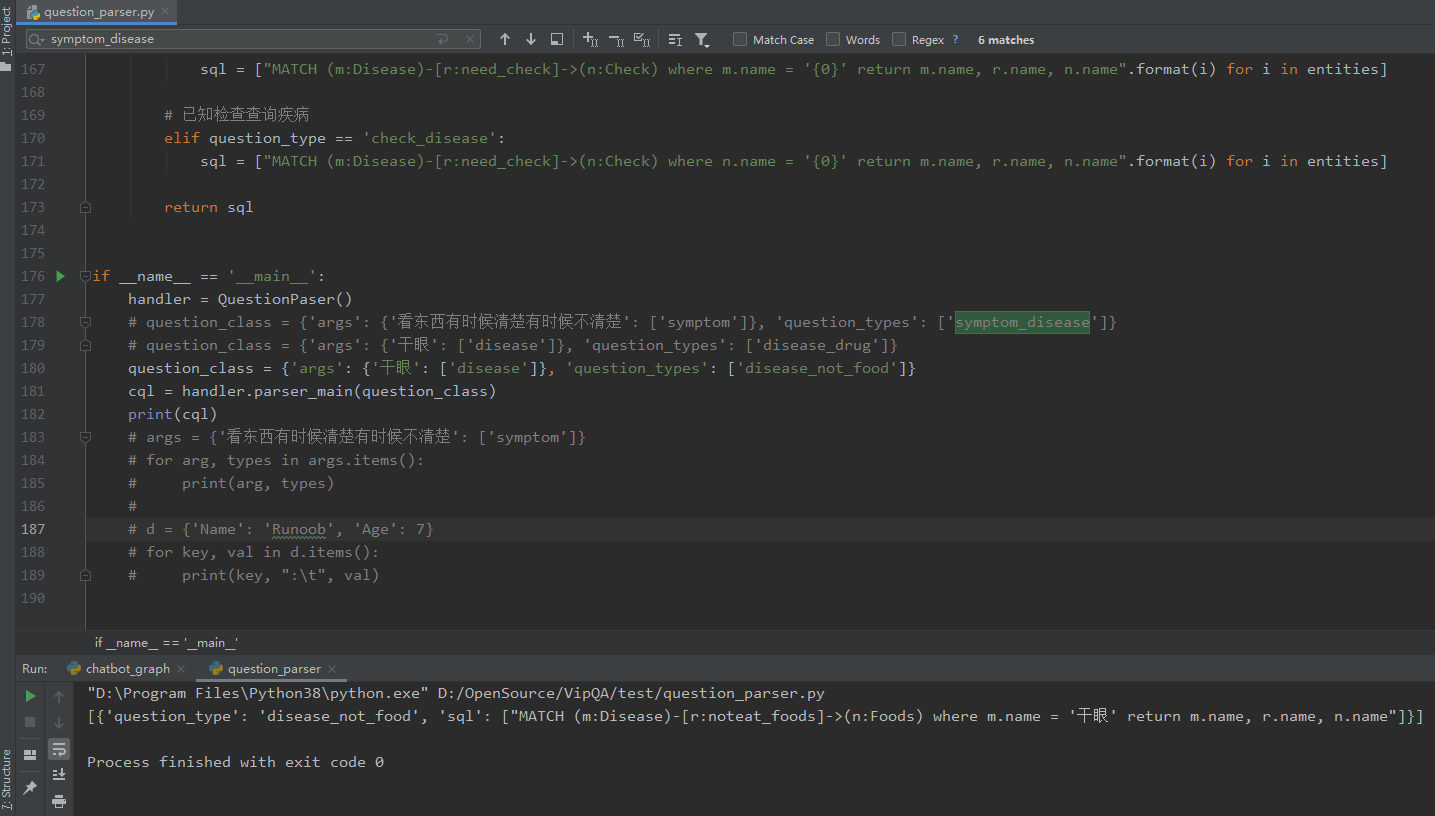
构建Cypher CQL语句
# 查询症状会导致哪些疾病
if question_type == 'symptom_disease':
sql = ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 查询症状会导致哪些疾病
if question_type == 'symptom_disease':
sql = ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) where n.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 查询疾病常用药品-药品别名记得扩充
if question_type == 'disease_drug':
sql = ["MATCH (m:Disease)-[r:used_drugs]->(n:Drug) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
# 查询疾病的忌口
if question_type == 'disease_not_food':
sql = ["MATCH (m:Disease)-[r:noteat_foods]->(n:Foods) where m.name = '{0}' return m.name, r.name, n.name".format(i) for i in entities]
node_dict.get('symptom')
Test
if __name__ == '__main__':
handler = QuestionPaser()
question_class = {'args': {'看东西有时候清楚有时候不清楚': ['symptom']}, 'question_types': ['symptom_disease']}
cql = handler.parser_main(question_class)
print(cql)
输出:
# 输入
question_class = {'args': {'看东西有时候清楚有时候不清楚': ['symptom']}, 'question_types': ['symptom_disease']}
# 输出
[{'question_type': 'symptom_disease', 'sql': ["MATCH (m:Disease)-[r:has_symptom]->(n:Symptom) where n.name = '看东西有时候清楚有时候不清楚' return m.name, r.name, n.name"]}]
# 输入:
question_class = {'args': {'干眼': ['disease']}, 'question_types': ['disease_drug']}
# 输出:
[{'question_type': 'disease_drug', 'sql': ["MATCH (m:Disease)-[r:used_drugs]->(n:Drug) where m.name = '干眼' return m.name, r.name, n.name"]}]
# 输入:
question_class = {'args': {'干眼': ['disease']}, 'question_types': ['disease_not_food']}
# 输出:
[{'question_type': 'disease_not_food', 'sql': ["MATCH (m:Disease)-[r:noteat_foods]->(n:Foods) where m.name = '干眼' return m.name, r.name, n.name"]}]
后面根据 生成的 CQL语句,查询出知识图谱中对应的数据,
源代码地址:https://gitee.com/VipSoft/VipQA
在线问诊 Python、FastAPI、Neo4j — 生成 Cypher 语句的更多相关文章
- neo4j中cypher语句多个模糊查询
总结一下经验: neo4j中,cypher语句的模糊查询,好像是个正则表达式结构. 对于一个属性的多个模糊查询,可以使用如下写法: 比如,查询N类型中,属性attr包含'a1'或者'a2'的所有节点. ...
- neo4j常用cypher语句
阅读更多 1.删除带有关系的节点 a.先删除关系 match (n:Node)-[r:关系名称]-() where (n...条件) delete r b.删除节点 match (n:Node ...
- neo4j 基本概念和Cypher语句总结
下面是一个介绍基本概念的例子,参考链接Graph database concepts: (1) Nodes(节点) 图谱的基本单位主要是节点和关系,他们都可以包含属性,一个节点就是一行数据,一个关系也 ...
- CYPHER 语句(Neo4j)
CYPHER 语句(Neo4j) 创建电影关系图 新增 查找 修改 删除 导入 格式转换 创建电影关系图 CREATE (TheMatrix:Movie {title:'The Matrix', re ...
- python批量生成SQL语句
1,首先写一条能运行成功插入SQL的语句 INSERT INTO sign_guest(realname,phone,email,sign,event_id)VALUES("jack&quo ...
- Day2 Python的运算符及三大语句控制结构
Python的运算符 Python语言支持以下类型的运算符: 算术运算符 比较(关系)运算符 赋值运算符 逻辑运算符 位运算符 成员运算符 身份运算符 运算符优先级 Python的三大语句控制结构: ...
- python脚本批量生成数据
在平时的工作中,经常会遇到造数据,特别是性能测试的时候更是需要大量的数据.如果一条条的插入数据库或者一条条的创建数据,效率未免有点低.如何快速的造大量的测试数据呢?在不熟悉存储过程的情况下,今天给大家 ...
- Neo4j之Cypher学习总结
Cypher 语句 Cypher是图形数据库Neo4j的声明式查询语言. Cypher语句规则和具备的能力: Cypher通过模式匹配图数据库中的节点和关系,来提取信息或者修改数据. Cypher语句 ...
- Python - 条件控制、循环语句 - 第十二天
Python 条件控制.循环语句 end 关键字 关键字end可以用于将结果输出到同一行,或者在输出的末尾添加不同的字符,实例如下: Python 条件语句是通过一条或多条语句的执行结果(True 或 ...
- Cypher 语句实战
Cypher 语句实战 下载和安装 Neo4j windows 桌面版- 环境设置 https://www.w3cschool.cn/neo4j/neo4j_exe_environment_setup ...
随机推荐
- Redis数据结构:高频面试题及解析
概述 Redis 是速度非常快的非关系型(NoSQL)内存键值数据库,可以存储键和五种不同类型的值之间的映射. 键的类型只能为字符串,值支持五种数据类型:字符串.列表.集合.散列表.有序集合. Red ...
- 【HarmonyOS】详解低代码端云一体化开发之数据模型
[关键字] 元服务.低代码平台.端云一体化开发.数据模型.拖拽式UI [1.写在前面] 上一篇中分享了关于低代码平台开发元服务的基本使用,有兴趣的可以看一下,文章地址如下: https://devel ...
- Git使用教程(带你玩转GitHub)
Git使用教程(理论实体结合体系版) 下载安装: 按照这个博客来就好 Windows系统Git安装教程(详解Git安装过程) - 学为所用 - 博客园 (cnblogs.com) Git命令大全: G ...
- 一篇讲懂Java运行类型、编译类型和多态(面向对象语言精髓之一)
对象:运行类型.编译类型和多态 1.搞清楚面向对象的运行类型和编译类型就掌握了对象的精髓,我们用举个例子 class Father { Father() { System.out.println(&q ...
- Liunx下对php内核的调试
0x01前言 主要是对上一篇文章中php_again这道题的补充. 0x02下载php源码 cd /usr/local wget https://www.php.net/distributions/p ...
- Unity UGUI的Mask(遮罩)组件的介绍及使用
Unity UGUI的Mask(遮罩)组件的介绍及使用 1. 什么是Mask组件? Mask(遮罩)组件是Unity UGUI中的一个重要组件,用于限制子对象的可见区域.通过设置遮罩组件,可以实现一些 ...
- 万字长文 | Hadoop 上云: 存算分离架构设计与迁移实践
一面数据原有的技术架构是在线下机房中使用 CDH 构建的大数据集群.自公司成立以来,每年都保持着高速增长,业务的增长带来了数据量的剧增. 在过去几年中,我们按照每 1 到 2 年的规划扩容硬件,但往往 ...
- Day02_Java_作业
A:选择题 1. 若有定义:int a,b; a=a+10;则执行上述语句后,a的值是(d). A. 10 B. 11 C. 0 D. 编译产生错误 2. 以下选项中变量均已正确定义,合法的赋值语句是 ...
- EntityCleanFramework
EF几乎是按照领域的概念诞生,它可以和Clean结合(ECF是我新想出的名字).ECF 是为了统一业务架构开发方式,也可以说成在 微服务架构 中服务的通用开发方式.当有了统一开发方式后,协作将更上一层 ...
- Django reset framework: 序列化
序列化与反序列化 将模型转换为json 称之为 序列化 将json转换为模型 称之为 反序列化 何时进行序列化与反序列化 序列化:当后端将数据库中信息取出返回给前端时,要进行序列化操作 反序列化:当需 ...