《深入理解计算机系统》实验五 —— Perfom Lab
本次实验是CSAPP的第5个实验,这次实验主要是让我们熟悉如何优化程序,如何写出更具有效率的代码。通过这次实验,我们可以更好的理解计算机的工作原理,在以后编写代码时,具有能结合软硬件思考的能力。
@
实验简介
本次实验主要处理优化内存密集型代码。图像处理提供了许多可以从优化中受益的功能示例。在本实验中,我们将考虑两种图像处理操作:旋转,可将图像逆时针旋转90o,平滑,可以“平滑”或“模糊”图片。
在本实验中,我们将考虑将图像表示为二维矩阵M,其中\({M_{i,j}}\)表示M的第(i,j)个像素的值,像素值是红色,绿色和蓝色(RGB)值的三倍。我们只会考虑方形图像。令N表示图像的行(或列)数。行和列以C样式编号,从0到N − 1。
给定这种表示形式,旋转操作可以非常简单地实现为以下两个矩阵运算:
转置:对于每对(i,j),\({M_{i,j}}\)和\({M_{j,i}}\)是互换的
交换行:第i行与第N-1 − i行交换。
具体如下图所示

通过用周围所有像素的平均值替换每个像素值(在以该像素为中心的最大3×3窗口)中替换每个像素值来实现平滑操作。如下图所示。像素的值\(M2[1][1]\) 和\(M2[N - 1][N - 1]\)如下所示:
\(M2[1][1] = \frac{{\sum\nolimits_{i = 0}^2 {\sum\nolimits_{j = 0}^2 {M1[i][j]} } }}{9}\)
\(M2[N - 1][N - 1] = \frac{{\sum\nolimits_{i = N - 2}^{N - 1} {\sum\nolimits_{j = N - 2}^{N - 1} {M1[i][j]} } }}{4}\)

本次实验中,我们需要修改唯一文件是kernels.c。driver.c程序是一个驱动程序,可让对我们修改的程序进行评分。使用命令make driver生成驱动程序代码并使用./driver命令运行它。
数据结构体
图像的核心数据是用结构体表示的。像素是一个结构,如下所示:
typedef struct {
unsigned short red; /* R value */
unsigned short green; /* G value */
unsigned short blue; /* B value */
} pixel;
可以看出,RGB值具有16位表示形式(“ 16位颜色”)。图像I表示为一维像素阵列,其中第(i,j)个像素为I [RIDX(i,j,n)]。这里n是图像矩阵的维数, RIDX是定义如下的宏:
#define RIDX(i,j,n) ((i)*(n)+(j))
有关此代码,请参见文件defs.h。
旋转Rotate
以下C函数计算将源图像src旋转90°的结果,并将结果存储在目标图像dst中。dim是图像的尺寸。
void naive_rotate(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(dim-1-j,i,dim)] = src[RIDX(i,j,dim)];
return;
}
上面的代码扫描源图像矩阵的行,然后复制到目标图像矩阵的列中。我们的任务是使用代码移动,循环展开和阻塞等技术重写此代码,以使其尽可能快地运行。(有关此代码,请参见文件kernels.c。)
平滑Smooth
平滑功能将源图像src作为输入,并在目标图像dst中返回平滑结果。这是实现的一部分:
void naive_smooth(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(i,j,dim)] = avg(dim, i, j, src); /* Smooth the (i,j)th pixel */
return;
}
函数avg返回第(i,j)个像素周围所有像素的平均值。我们的任务是优化平滑(和avg)以尽可能快地运行。 (注意:函数avg是一个局部函数,可以完全摆脱它而以其他方式实现平滑)。(这段代码(以及avg的实现)位于kernels.c文件中。)
评价指标
我们的主要性能指标是CPE。如果某个函数需要C个周期来运行大小为N×N的图像,则CPE值为\(C/{N^2}\)。
版本管理
我们可以编写旋转和平滑例程的许多版本。为了帮助您比较编写的所有不同版本的性能,我们提供了一种“注册”功能的方式。
例如,我们提供给您的文件kernels.c包含以下功能:
void register_rotate_functions() {
add_rotate_function(&rotate, rotate_descr);
}
此函数包含一个或多个调用以添加旋转函数。在上面的示例中,添加旋转函数将函数旋转与字符串旋转说明一起注册,该字符串是函数功能的ASCII描述。请参阅文件kernels.c以了解如何创建字符串描述。该字符串的长度最多为256个字符。
驱动
将编写的源代码将与我们提供给驱动程序二进制文件的目标代码链接。要创建此二进制文件,您将需要执行以下命令
unix> make driver
每次更改kernels.c中的代码时,都需要重新制作驱动程序。要测试您的实现,然后可以运行以下命令:
unix> ./driver
该驱动程序可以在四种不同的模式下运行:
默认模式,在其中运行实施的所有版本。
Autograder模式,其中仅运行rotation()和smooth()函数。这是当我们使用驱动程序对您的切纸进行评分时将运行的模式。
文件模式,其中仅运行输入文件中提到的版本。
转储模式,其中每个版本的单行描述转储到文本文件中。然后,您可以编辑该文本文件,以仅使用文件模式保留要测试的版本。您可以指定是在转储文件之后退出还是要运行您的实现。
如果不带任何参数运行,驱动程序将运行所有版本(默认模式)。其他模式和选项可以通过驱动程序的命令行参数来指定,如下所示:
-g:仅运行rotate()和smooth()函数(自动分级模式)。
-f :仅执行在中指定的那些版本(文件模式)。
-d :将所有版本的名称转储到名为的转储文件中,将一行转储到版本(转储模式)。
-q :将版本名称转储到转储文件后退出。与-d一起使用。例如,要在打印转储文件后立即退出,请键入./driver -qd dumpfile。
-h:打印命令行用法。
优化程序的方法
emsp; 回顾下常用的优化程序的方法,总结如下:
(1)高级设计
为遇到的问题选择适当的算法和数据结构。要特别警觉,避免使用那些会渐进地产生糟糕性能的算法或编码技术。
(2)基本编码原则
避免限制优化的因素,这样编译器就能产生高效的代码。
消除连续的函数调用。在可能时,将计算移到循环外。考虑有选择地妥协程序的模块性以获得更大的效率。
消除不必要的内存引用。引入临时变量来保存中间结果。只有在最后的值计算出来时,才将结果存放到数组或全局变量中。
(3)低级优化
结构化代码以利用硬件功能。
展开循环,降低开销,并且使得进一步的优化成为可能。
通过使用例如多个累积变量和重新结合等技术,找到方法提高指令级并行。
用功能性的风格重写条件操作,使得编译采用条件数据传送。
(4)使用性能分析工具
当处理大型程序时,将注意力集中在最耗时的部分变得很重要。代码剖析程序和相关的工具能帮助我们系统地评价和改进程序性能。我们描述了 GPROF,一个标准的Unix剖析工具。还有更加复杂完善的剖析程序可用,例如 Intel的VTUNE程序开发系统,还有 Linux系统基本上都有的 VALGRIND。这些工具可以在过程级分解执行时间,估计程序每个基本块( basic block)的性能。(基本块是内部没有控制转移的指令序列,因此基本块总是整个被执行的。)
Optimizing Rotate
在这一部分中,我们将优化旋转以实现尽可能低的CPE。您应该编译驱动程序,然后使用适当的参数运行它以测试您的实现。例如,运行提供的原始版本(用于旋转)的驱动程序将生成如下所示的输出:

函数源码如下:
void naive_rotate(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(dim-1-j,i,dim)] = src[RIDX(i,j,dim)];
return;
}
其中,defs.h中RIDX定义为:#define RIDX(i,j,n) ((i)*(n)+(j))下面详细分析下程序。
i = 0 j = 0 dest[20] = src[0] i = 1 j = 0 dest[21] = src[5]
i = 0 j = 1 dest[15] = src[1] i = 1 j = 1 dest[16] = src[6]
i = 0 j = 2 dest[10] = src[2] i = 1 j = 2 dest[11] = src[7]
i = 0 j = 3 dest[5] = src[3] i = 1 j = 3 dest[6] = src[8]
i = 0 j = 4 dest[0] = src[4] i = 1 j = 4 dest[1] = src[9]
具体如下图所示:
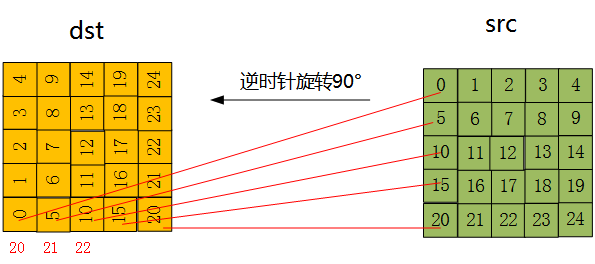
这段代码的作用就是将dim * dim大小的方块中所有的像素进行行列调位、导致整幅图画进行了90度旋转。观察源代码我们发现,程序进行了嵌套循环,随着dim的增加,循环的复杂度越来越大,而且每循环一次,dim-1-j就要计算一次,因此,我们考虑进行分块优化。
优化版本一:分块 8 * 8
对于循环分块,这里的分块指的是一个应用级的数据组块,而不是高速缓存中的块,这样构造程序,能将一个片加载到L1高速缓存中去,并在这个片中进行所需要的所有读和写,然后丢掉这个片,加载下一个片,以此类推。
/*分块:8 * 8*/
char rotate_descr[] = "rotate1: Current working version";
void rotate(int dim, pixel *src, pixel *dst) {
int i,j,i1,j1;
for(i=0; i < dim; i+=8)
for(j=0; j < dim; j+=8)
for(i1=i; i1 < i+8; i1++)
for(j1=j; j1 < j+8; j1++)
dst[RIDX(dim-1-j1,i1,dim)] = src[RIDX(i1,j1,dim)];
}
优化后的版本测试如下所示:
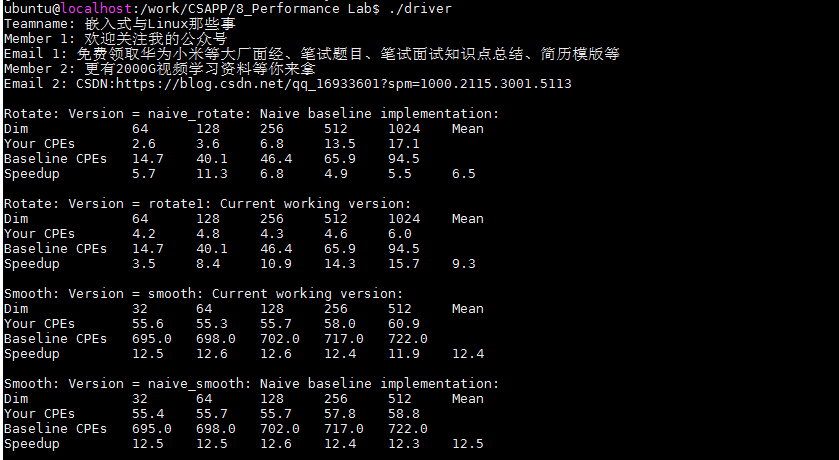
右上图可以看到,得分有了明显的提升,Dim规模较小时,提升并不明显,在Dim为1024*1024时,由原来的17.1降低到了6.0.说明我们的方法还是有效的,但是最后的总得得分只有9.3分,效果不是很好。
优化版本二:分块 32 * 32
char rotate_descr[] = "rotate2: Current working version";
void rotate(int dim, pixel *src, pixel *dst) {
int i,j,i1,j1;
for(i=0; i < dim; i+=32)
for(j=0; j < dim; j+=32)
for(i1=i; i1 < i+32; i1++)
for(j1=j; j1 < j+32; j1++)
dst[RIDX(dim-1-j1,i1,dim)] = src[RIDX(i1,j1,dim)];
}
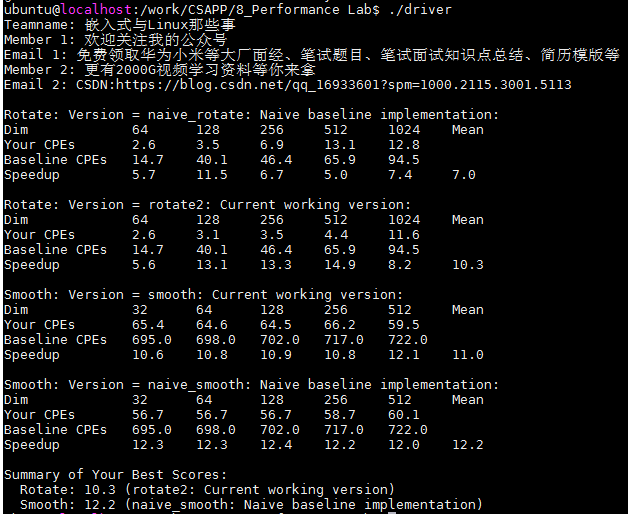
本次继续采用的是分块策略,分为了32块,但是由下图的得分可以看到,性能基本有提升,所以,需要换个思路了。
优化版本三:循环展开,32路并行
在版本二的基础上,我们进行循环展开,32路并行,并使用指针代替RIDX进行数组访问,这里牺牲了程序的尺寸来换取速度优化。
char rotate_descr[] = "rotate3: Current working version";
void rotate(int dim, pixel *src, pixel *dst) {
int i,j;
int dst_base = (dim-1)*dim;
dst +=dst_base;
for(i = 0;i < dim;i += 32){
for(j = 0;j < dim;j++){
*dst = *src; src +=dim; dst++; //31组
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src +=dim; dst++;
*dst = *src; src++;
src -= (dim<<5)-dim; //src -=31*dim;
dst -=31+dim;
}
dst +=dst_base + dim;
dst +=32;
src +=(dim<<5)-dim; //src +=31*dim;
}
}
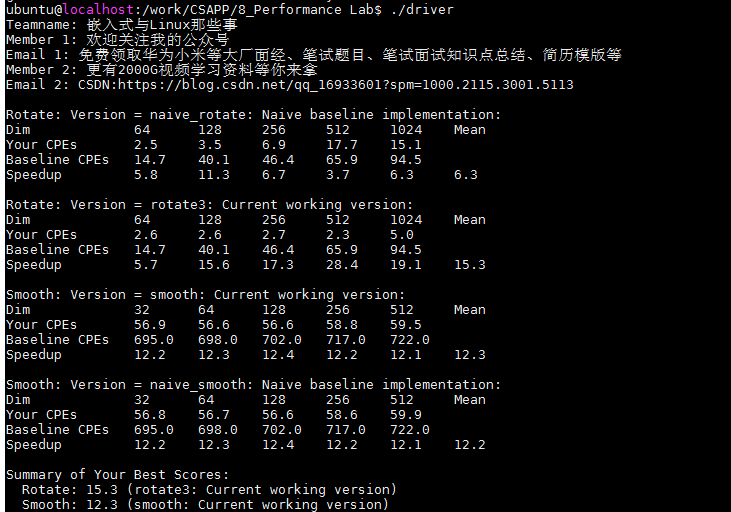
我们在版本二的基础上,将原来的程序的内循环展开成32个并行,每一次同时处理32个像素点,即将循环次数减少了32倍,大大加速了程序。分数由版本二的10.3分涨到了15.3分。特别是在哦1024 * 1024时,由15.1直接降到了5.0,性能提升还是很明显的。
Optimizing Smooth
在这一部分中,您将优化平滑度以实现尽可能低的CPE。例如,运行提供的朴素版本(为了平滑)的驱动程序将生成如下所示的输出:
unix> ./driver
Smooth: Version = naive_smooth: Naive baseline implementation:
Dim 32 64 128 256 512 Mean
Your CPEs 695.8 698.5 703.8 720.3 722.7
Baseline CPEs 695.0 698.0 702.0 717.0 722.0
Speedup 1.0 1.0 1.0 1.0 1.0 1.0
void naive_smooth(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(i,j,dim)] = avg(dim, i, j, src); /* Smooth the (i,j)th pixel */
return;
}
这个函数的作用是平滑图像,在smooth函数中因为要求周围点的平均值,所以会频繁的调用avg函数,而且avg函数还是一个2层for循环,所以我们可以考虑循环展开或者消除函数调用等方法,减少avg函数调用和循环。
Smooth函数处理分为4块,一为主体内部,由9点求平均值;二为4个顶点,由4点求平均值;三为四条边界,由6点求平均值。从图片的顶部开始处理,再上边界,顺序处理下来,其中在处理左边界时,for循环处理一行主体部分。
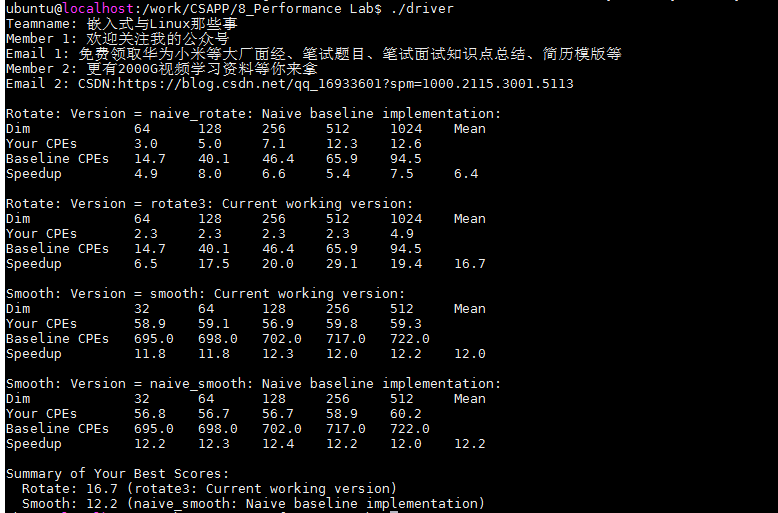
未经优化的函数性能如下,得分为12.2分。
优化版本一:消除函数调用
void smooth(int dim, pixel *src, pixel *dst)
{
pixel_sum rowsum[530][530];
int i, j, snum;
for(i=0; i<dim; i++)
{
rowsum[i][0].red = (src[RIDX(i, 0, dim)].red+src[RIDX(i, 1, dim)].red);
rowsum[i][0].blue = (src[RIDX(i, 0, dim)].blue+src[RIDX(i, 1, dim)].blue);
rowsum[i][0].green = (src[RIDX(i, 0, dim)].green+src[RIDX(i, 1, dim)].green);
rowsum[i][0].num = 2;
for(j=1; j<dim-1; j++)
{
rowsum[i][j].red = (src[RIDX(i, j-1, dim)].red+src[RIDX(i, j, dim)].red+src[RIDX(i, j+1, dim)].red);
rowsum[i][j].blue = (src[RIDX(i, j-1, dim)].blue+src[RIDX(i, j, dim)].blue+src[RIDX(i, j+1, dim)].blue);
rowsum[i][j].green = (src[RIDX(i, j-1, dim)].green+src[RIDX(i, j, dim)].green+src[RIDX(i, j+1, dim)].green);
rowsum[i][j].num = 3;
}
rowsum[i][dim-1].red = (src[RIDX(i, dim-2, dim)].red+src[RIDX(i, dim-1, dim)].red);
rowsum[i][dim-1].blue = (src[RIDX(i, dim-2, dim)].blue+src[RIDX(i, dim-1, dim)].blue);
rowsum[i][dim-1].green = (src[RIDX(i, dim-2, dim)].green+src[RIDX(i, dim-1, dim)].green);
rowsum[i][dim-1].num = 2;
}
for(j=0; j<dim; j++)
{
snum = rowsum[0][j].num+rowsum[1][j].num;
dst[RIDX(0, j, dim)].red = (unsigned short)((rowsum[0][j].red+rowsum[1][j].red)/snum);
dst[RIDX(0, j, dim)].blue = (unsigned short)((rowsum[0][j].blue+rowsum[1][j].blue)/snum);
dst[RIDX(0, j, dim)].green = (unsigned short)((rowsum[0][j].green+rowsum[1][j].green)/snum);
for(i=1; i<dim-1; i++)
{
snum = rowsum[i-1][j].num+rowsum[i][j].num+rowsum[i+1][j].num;
dst[RIDX(i, j, dim)].red = (unsigned short)((rowsum[i-1][j].red+rowsum[i][j].red+rowsum[i+1][j].red)/snum);
dst[RIDX(i, j, dim)].blue = (unsigned short)((rowsum[i-1][j].blue+rowsum[i][j].blue+rowsum[i+1][j].blue)/snum);
dst[RIDX(i, j, dim)].green = (unsigned short)((rowsum[i-1][j].green+rowsum[i][j].green+rowsum[i+1][j].green)/snum);
}
snum = rowsum[dim-1][j].num+rowsum[dim-2][j].num;
dst[RIDX(dim-1, j, dim)].red = (unsigned short)((rowsum[dim-2][j].red+rowsum[dim-1][j].red)/snum);
dst[RIDX(dim-1, j, dim)].blue = (unsigned short)((rowsum[dim-2][j].blue+rowsum[dim-1][j].blue)/snum);
dst[RIDX(dim-1, j, dim)].green = (unsigned short)((rowsum[dim-2][j].green+rowsum[dim-1][j].green)/snum);
}
}
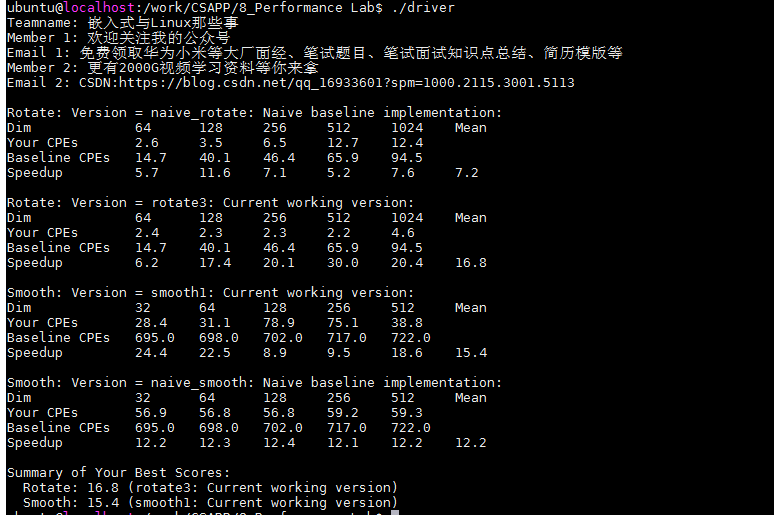
在以上的优化中,我们取消了对avg函数的直接调用,而是直接对像素点的fgb颜色分别求均值,并且将重复利用的数据存储在了数组之中,因此,速度比之前有所提升,但是提升并不高,由12.2提升到15.4。
优化版本二:分开讨论,分块求平均
void smooth(int dim, pixel *src, pixel *dst)
{
int i,j;
int dim0=dim;
int dim1=dim-1;
int dim2=dim-2;
pixel *P1, *P2, *P3;
pixel *dst1;
P1=src;
P2=P1+dim0;
//左上角像素处理
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red)>>2;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
dst++;
//上边界处理
for(i=1;i<dim1;i++)
{
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red)/6;
dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green)/6;
dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue)/6;
dst++;
P1++;
P2++;
}
//右上角像素处理
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red)>>2;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
dst++;
P1=src;
P2=P1+dim0;
P3=P2+dim0;
//左边界处理
for(i=1;i<dim1;i++)
{
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red+P3->red+(P3+1)->red)/6;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green+P3->green+(P3+ 1)->green)/6;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue+P3->blue+(P3+1)->blue)/6;
dst++;
dst1=dst+1;
//中间主体部分处理
for(j=1;j<dim2;j+=2)
{
//同时处理两个像素
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red+P3->red+(P3+1)->red+(P3+2)->red)/9;
dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green+P3->green+(P3+1)->green+(P3+2)->green)/9;
dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue+P3->blue+(P3+1)->blue+(P3+2)->blue)/9;
dst1->red=((P1+3)->red+(P1+1)->red+(P1+2)->red+(P2+3)->red+(P2+1)->red+(P2+2)->red+(P3+3)->red+(P3+1)->red+(P3+2)->red)/9;
dst1->green=((P1+3)->green+(P1+1)->green+(P1+2)->green+(P2+3)->green+(P2+1)->green+(P2+2)->green+(P3+3)->green+(P3+1)->green+(P3+2)->green)/9;
dst1->blue=((P1+3)->blue+(P1+1)->blue+(P1+2)->blue+(P2+3)->blue+(P2+1)->blue+(P2+2)->blue+(P3+3)->blue+(P3+1)->blue+(P3+2)->blue)/9;
dst+=2;
dst1+=2;
P1+=2;
P2+=2;
P3+=2;
}
for(;j<dim1;j++)
{
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red+P3->red+(P3+1)->red+(P3+2)->red)/9;
dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green+P3->green+(P3+1)->green+(P3+2)->green)/9;
dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue+P3->blue+(P3+1)->blue+(P3+2)->blue)/9;
dst++;
P1++;
P2++;
P3++;
}
//右侧边界处理
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red+P3->red+(P3+1)->red)/6;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green+P3->green+(P3+1)->green)/6;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue+P3->blue+(P3+1)->blue)/6;
dst++;
P1+=2;
P2+=2;
P3+=2;
}
//右下角处理
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red)>>2;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
dst++;
//下边界处理
for(i=1;i<dim1;i++)
{
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red)/6;
dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green)/6;
dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue)/6;
dst++;
P1++;
P2++;
}
//右下角像素处理
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red)>>2;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
}
在这个版本中,我们在版本一的基础上继续优化。将Smooth函数分为内部-顶点-边界的四部分,一为主体内部,由9点求平均值;二为4个顶点,由4点求平均值;三为四条边界,由6点求平均值。从图片的顶部开始处理,再上边界,顺序处理下来,其中在处理左边界时,for循环处理一行主体部分,就是以上的代码。
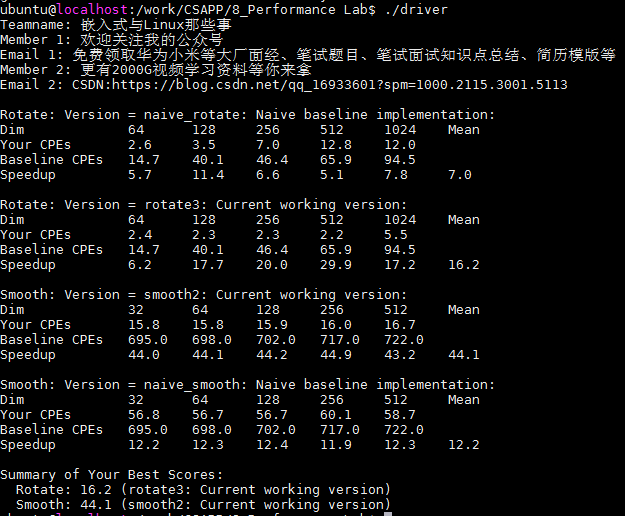
下图为测试结果,由版本一的分15.4分提升到了44.1分,性能提升显著!
总结
本次实验的趣味性不如前几个实验,难度也没有前几个实验的大。在实际优化程序时,我们不能一味的为了速度而展开程序,或者消除函数引用,以程序的体积和可读性去换取性能的提升是非常不划算的。在保证可读性的前提下尽可能去提升程序的性能。
有任何问题,均可通过公告中的二维码联系我
《深入理解计算机系统》实验五 —— Perfom Lab的更多相关文章
- 深入理解计算机系统项目之 Shell Lab
博客中的文章均为meelo原创,请务必以链接形式注明本文地址 Shell Lab是CMU计算机系统入门课程的一个实验.在这个实验里你需要实现一个shell,shell是用户与计算机的交互界面.普通意义 ...
- CS:APP3e 深入理解计算机系统_3e C Programming Lab实验
queue.h: /* * Code for basic C skills diagnostic. * Developed for courses 15-213/18-213/15-513 by R. ...
- 《深入理解计算机系统》实验一 —Data Lab
本文是CSAPP第二章的配套实验,通过使用有限的运算符来实现正数,负数,浮点数的位级表示.通过完成这13个函数,可以使我们更好的理解计算机中数据的编码方式. 准备工作 首先去官网Lab Assig ...
- 《深入理解计算机系统》实验三 —— Buf Lab
这是CSAPP的第三个实验,主要让我们熟悉GDB的使用,理解程序栈帧的结构和缓冲区溢出的原理. 实验目的 本实验的目的在于加深对IA-32函数调用规则和栈结构的具体理解.实验的主要内容是对一个可执 ...
- 深入理解计算机系统 BombLab 实验报告
又快有一个月没写博客了,最近在看<深入理解计算机系统>这本书,目前看完了第三章,看完这章,对程序的机器级表示算是有了一个入门,也对 C 语言里函数栈帧有了一个初步的理解. 为了加深对书本内 ...
- 4.2《深入理解计算机系统》笔记(五)并发、多进程和多线程【Final】
该书中第11章是写web服务器的搭建,无奈对web还比较陌生.还没有搞明白. 这些所谓的并发,其实都是操作系统做的事情,比如,多进程是操作系统fork函数实现的.I/O多路复用需要内核挂起进程.多线程 ...
- 20145221 《信息安全系统设计基础》实验五 简单嵌入式WEB服务器实验
20145221 <信息安全系统设计基础>实验五 简单嵌入式WEB服务器实验 实验报告 队友博客:20145326蔡馨熠 实验博客:<信息安全系统设计基础>实验五 简单嵌入式W ...
- 深入理解计算机系统_3e 第九章家庭作业 CS:APP3e chapter 9 homework
9.11 A. 00001001 111100 B. +----------------------------+ | Parameter Value | +--------------------- ...
- 《深入理解计算机系统》(CSAPP)读书笔记 —— 第一章 计算机系统漫游
本章通过跟踪hello程序的生命周期来开始对计算机系统进行学习.一个源程序从它被程序员创建开始,到在系统上运行,输出简单的消息,然后终止.我们将沿着这个程序的生命周期,简要地介绍一些逐步出现的关键概念 ...
- 【DIY】【CSAPP-LAB】深入理解计算机系统--datalab笔记
title: 前言 <深入理解计算机系统>一书是入门计算机系统的极好选择,从其第三版的豆瓣评分9.8分可见一斑.该书的起源是卡耐基梅龙大学 计算机系统入门课(Introduction to ...
随机推荐
- javascript+php 实现blob加密视频(html video)
1.mp4地址加密为blob链接在html5的video标签展示 PHP: 1 $file_path = "...mp4"; //视频文件地址 2 ob_end_clean(); ...
- c++学习,和友元函数
第一友元函数访问私有元素时不会显示,但是是可以调用的(我使用的是gcc10.3版本的)友元函数可以访问任何元素.就是语法你别写错了. 继承如果父类已经写了构造函数,子类一定要赋值给构造函数,要么父类就 ...
- 机器人行业数据闭环实践:从对象存储到 JuiceFS
JuiceFS 社区聚集了来自各行各业的前沿科技用户.本次分享的案例来源于刻行,一家商用服务机器人领域科技企业. 商用服务机器人指的是我们日常生活中常见的清洁机器人.送餐机器人.仓库机器人等.刻行采用 ...
- Oracle-Rman备份全解析
RMAN备份数据库物理文件到备份集(backupset)中.在创建备份集时,仅备份已经使用的数据库(不备份空闲的数据块),而且还可以采用压缩功能. RMAN恢复时指当数据库出现介质失败时,使用RMAN ...
- python操作mongodb实现读写分离
读写分离 默认情况下,MongoClient 实例将查询发送到副本集的主要成员. 要使用副节点作为查询,以实现读写分离,我们必须更改读取首选项: 读取首选项在模块pymongo.ReadPrefere ...
- Java 21 虚拟线程:使用指南(一)
虚拟线程是由 Java 21 版本中实现的一种轻量级线程.它由 JVM 进行创建以及管理.虚拟线程和传统线程(我们称之为平台线程)之间的主要区别在于,我们可以轻松地在一个 Java 程序中运行大量.甚 ...
- 终于卷完了!MySQL 打怪升级进阶成神之路(2023 最新版)!
从第一篇文章开始,我们逐步详细介绍了 MySQL 数据库的基础知识,如:数据类型.存储引擎.性能优化(软.硬及sql语句),MySQL 数据库的高可用架构的部分,如:主从同步.读写分离的原理与实践.跨 ...
- JavaFx之使用高版本JDK(二十八)
JavaFx之使用高版本JDK(二十八) 如何使用高版本的jfx? 根据官网的需要手动引入jfx模块(运行参数:–module-path) 要知道高版本jfx已经集成了丰富的主流功能,例如视频编码,大 ...
- Luogu P4524 Ceste 题解
题目链接:\(\texttt{Luogu P4524 Ceste}\) 简化题意 给定一个有 \(n\) 个点 \(m\) 条边的无向图.每条边的边权为一个二元组 \((a, b)\),求以 \(1\ ...
- 【scikit-learn基础】--『监督学习』之 随机森林分类
随机森林分类算法是一种基于集成学习(ensemble learning)的机器学习算法,它的基本原理是通过对多个决策树的预测结果进行平均或投票,以产生最终的分类结果. 随机森林算法可用于回归和分类问题 ...