【GUI软件】小红书搜索结果批量采集,支持多个关键词同时抓取!
一、背景介绍
1.1 爬取目标
您好!我是@马哥python说 ,一名10年程序猿。
我用python开发了一个爬虫采集软件,可自动按关键词抓取小红书笔记数据。
为什么有了源码还开发界面软件呢?方便不懂编程代码的小白用户使用,无需安装python,无需改代码,双击打开即用!
软件界面截图:
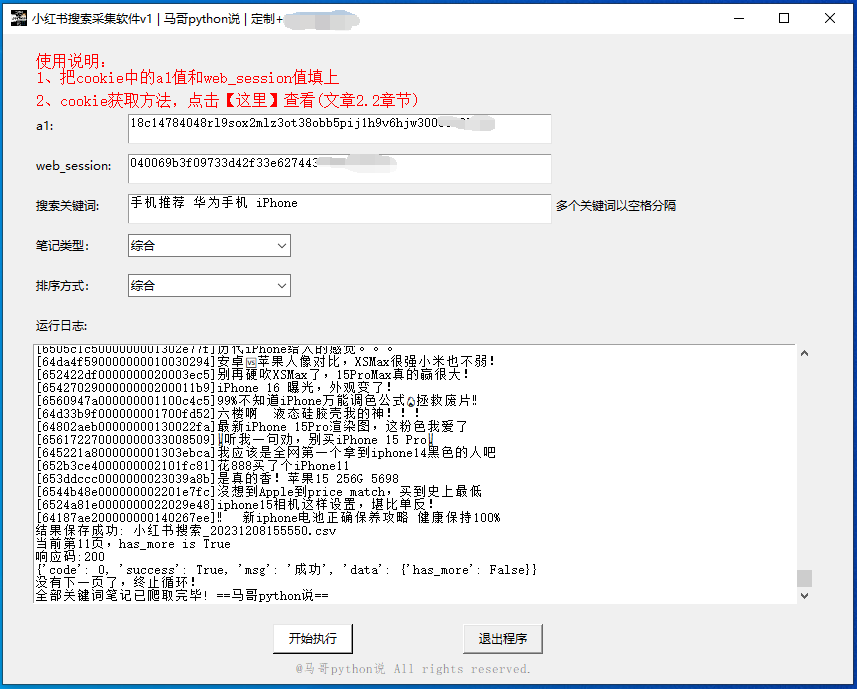
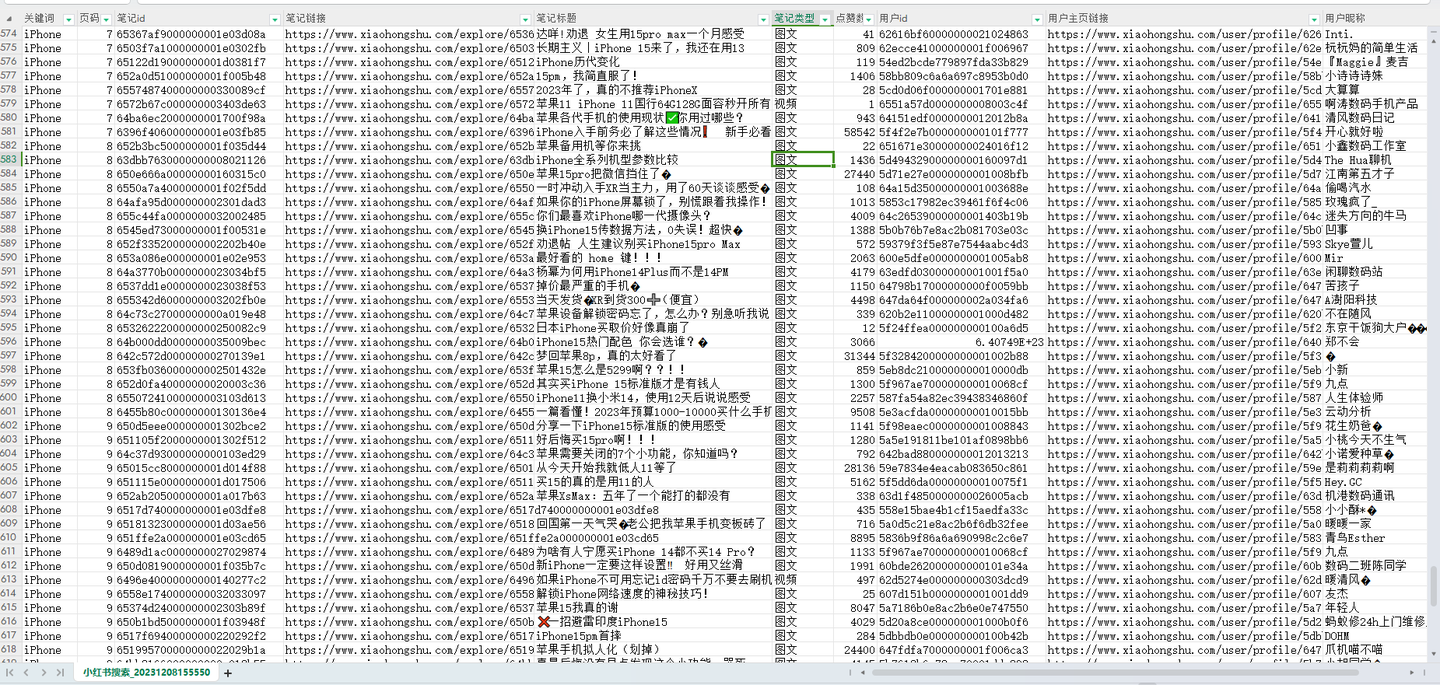
爬取结果截图:
结果截图1:

结果截图2:

结果截图3:
以上。
1.2 演示视频
软件运行演示:
【软件演示】小红书搜索采集工具,可同时多个关键词,并支持筛选笔记类型、排序等
1.3 软件说明
几点重要说明:
- Windows用户可直接双击打开使用,无需Python运行环境,非常方便!
- 需要填入cookie中的a1值和web_session值
- 支持按笔记类型(综合/视频/图文)和排序方式(综合/最新/最热)爬取
- 支持同时爬多个关键词
- 每个关键词最多可采集220条左右的笔记,与网页端数量一致
- 爬取过程中,有log文件详细记录运行过程,方便回溯
- 爬取完成后,自动导出结果到csv文件
- 爬取字段含:关键词, 页码, 笔记id, 笔记链接, 笔记标题, 笔记类型, 点赞数, 用户id, 用户主页链接, 用户昵称。
以上。
二、代码讲解
2.1 爬虫采集模块
首先,定义接口地址作为请求地址:
# 请求地址
url = 'https://edith.xiaohongshu.com/api/sns/web/v1/search/notes'
定义一个请求头,用于伪造浏览器:
# 请求头
h1 = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Content-Type': 'application/json;charset=UTF-8',
'Cookie': '换成自己的cookie值',
'Origin': 'https://www.xiaohongshu.com',
'Referer': 'https://www.xiaohongshu.com/',
'Sec-Ch-Ua': '"Microsoft Edge";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"macOS"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0',
}
说明一下,cookie是个关键参数。
其中,cookie里的a1和web_session获取方法,如下:
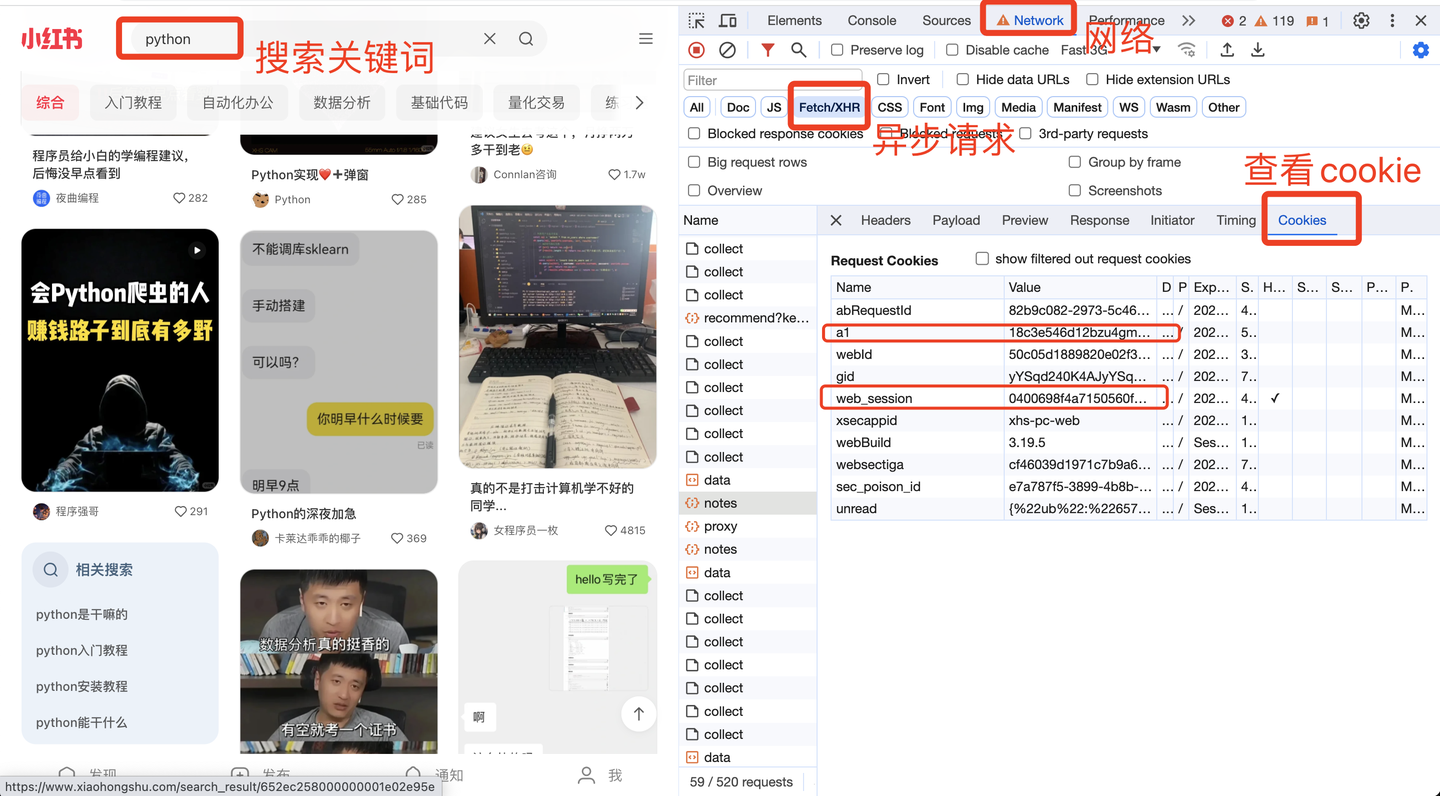
这两个值非常重要,软件界面需要填写!!
加上请求参数,告诉程序你的爬取条件是什么:
# 请求参数
post_data = {
"keyword": search_keyword,
"page": page,
"page_size": 20,
"search_id": v_search_id,
"sort": v_sort,
"note_type": v_note_type,
"image_scenes": "FD_PRV_WEBP,FD_WM_WEBP",
}
下面就是发送请求和接收数据:
# 发送请求
r = requests.post(url, headers=h1, data=data_json.encode('utf8'))
print(r.status_code)
# 以json格式接收返回数据
json_data = r.json()
定义一些空列表,用于存放解析后字段数据:
# 定义空列表
note_id_list = [] # 笔记id
note_title_list = [] # 笔记标题
note_type_list = [] # 笔记类型
like_count_list = [] # 点赞数
user_id_list = [] # 用户id
user_name_list = [] # 用户昵称
循环解析字段数据,以"笔记标题"为例:
# 循环解析
for data in json_data['data']['items']:
# 笔记标题
try:
note_title = data['note_card']['display_title']
except:
note_title = ''
print('note_title:', note_title)
note_title_list.append(note_title)
其他字段同理,不再赘述。
最后,是把数据保存到csv文件:
# 把数据保存到Dataframe
df = pd.DataFrame(
{
'关键词': search_keyword,
'页码': page,
'笔记id': note_id_list,
'笔记链接': ['https://www.xiaohongshu.com/explore/' + i for i in note_id_list],
'笔记标题': note_title_list,
'笔记类型': note_type_list,
'点赞数': like_count_list,
'用户id': user_id_list,
'用户主页链接': ['https://www.xiaohongshu.com/user/profile/' + i for i in user_id_list],
'用户昵称': user_name_list,
}
)
if os.path.exists(result_file):
header = False
else:
header = True
# 把数据保存到csv文件
df.to_csv(result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
完整代码中,还含有:判断循环结束条件、js逆向解密、笔记类型(综合/视频图文)筛选、排序方式筛选(综合/最新/最热)等关键实现逻辑。
2.2 软件界面模块
主窗口部分:
# 创建主窗口
root = tk.Tk()
root.title('小红书搜索采集软件v1 | 马哥python说 |')
# 设置窗口大小
root.minsize(width=850, height=650)
输入控件部分:
# 搜索关键词
tk.Label(root, justify='left', text='搜索关键词:').place(x=30, y=160)
entry_kw = tk.Text(root, bg='#ffffff', width=60, height=2, )
entry_kw.place(x=125, y=160, anchor='nw') # 摆放位置
底部版权部分:
# 版权信息
copyright = tk.Label(root, text='@马哥python说 All rights reserved.', font=('仿宋', 10), fg='grey')
copyright.place(x=290, y=625)
以上。
2.3 日志模块
好的日志功能,方便软件运行出问题后快速定位原因,修复bug。
核心代码:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 将其保存到特定目录,ap方法就是寻找项目根目录,该方法博主前期已经写好。
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
日志文件截图:
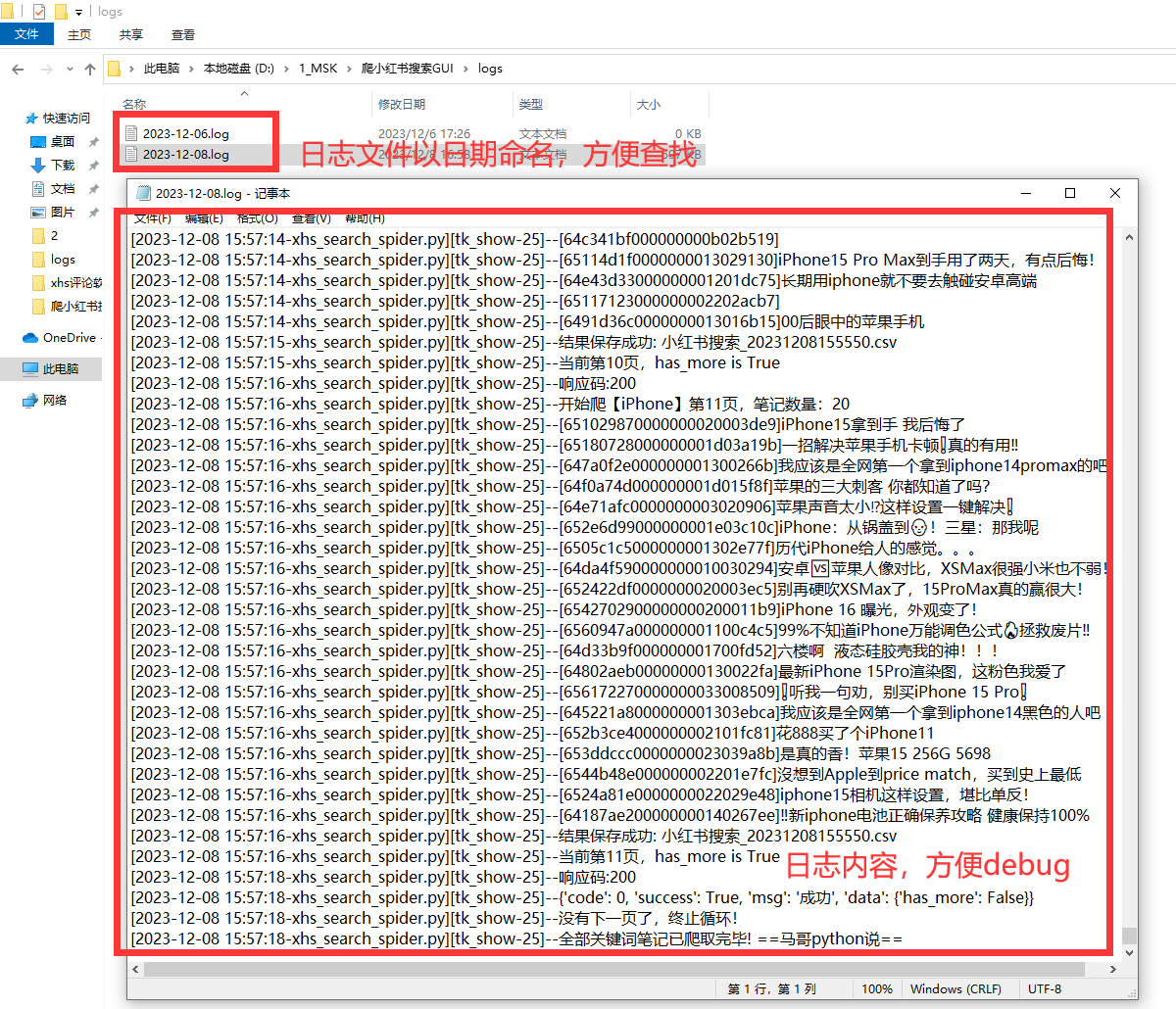
以上。
三、获取源码及软件
get完整源码:【GUI软件】小红书搜索结果批量采集,支持多个关键词同时抓取
by 马哥python说
【GUI软件】小红书搜索结果批量采集,支持多个关键词同时抓取!的更多相关文章
- 6.简单提取小红书app数据(简单初步试采集与分析)-1
采集小红书数据爬虫:1.本来是要通过app端的接口去直接采集数据,但是app接口手机端设置本地代理这边开启抓包后就不能正常访问数据.所以就采用了微信小程序里的小红书app接口去采集数据. 2.通过 f ...
- 2月第3周业务风控关注|上海网信办复测23个被约谈APP 涉及1号店、小红书等
易盾业务风控周报每周呈报值得关注的安全技术和事件,包括但不限于内容安全.移动安全.业务安全和网络安全,帮助企业提高警惕,规避这些似小实大.影响业务健康发展的安全风险. 1.上海网信办复测23个被约谈A ...
- 从字节跳动离职后,拿到探探、趣头条、爱奇艺、小红书、15家公司的 offer【转】
前言 博主目前从事Android开发3年,前两年一直在抖音工作.我这篇文章并不是简单的描述一些面试中的题,或者总结一些Android的知识,而是想记录我整个的想法和准备的过程,以及一些心得体会,让大家 ...
- 剑指Offer——小米+小红书笔试题+知识点总结
剑指Offer--小米+小红书笔试题+知识点总结 情景回顾 时间:2016.9.23 19:00-21:00 2016.9.24 15:00-17:00 地点:山东省网络环境智能计算技术重点实验室 事 ...
- 最新 小红书java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.小红书等10家互联网公司的校招Offer,因为某些自身原因最终选择了小红书.6.7月主要是做系统复习.项目复盘.LeetCo ...
- Keep、小红书、美图…独角兽App能拿到新一轮救命钱吗?
大多数人热爱手机,不是因为时尚的外观或者结实的零部件,而是因琳琅满目的App赋予其太多的功能.智能手机最先是清理掉人类的零碎时间,现如今又开始肢解我们大块的时间,或者说,智能手机本身就是生活.在如此背 ...
- 【PyHacker编写指南】打造URL批量采集器
这节课是巡安似海PyHacker编写指南的<打造URL批量采集器> 喜欢用Python写脚本的小伙伴可以跟着一起写一写呀. 编写环境:Python2.x 00x1: 需要用到的模块如下: ...
- Android -- 仿小红书欢迎界面
1,觉得小红书的欢迎界面感觉很漂亮,就像来学习学习一下来实现类似于这种效果 原效果图如下: 2,根据效果我们来一点点分析 第一步:首先看一下我们的主界面布局文件视图效果如下: main_activi ...
- 使用Vue2完成“小红书” app
小红书项目说明 整体页面格调.功能和原版 app 无限接近.具体页面细节可以下载 “小红书” app查看. 图片素材:https://pan.baidu.com/s/1qYOcx7e 整体要求: · ...
- 超实用教程,教你用墨刀做出小红书app原型
一个新手怎么用1小时快速学会APP原型设计? 1小时很短,这意味着学习时必须把握APP原型设计中的重点.难点,而非面面俱到. 要在短时间内理解.掌握一个工具的使用,最有效的方式莫过于临摹: 看实例视频 ...
随机推荐
- 冒泡排序【Java】
1 public class Paixu { 2 public static void main(String args[]) { 3 int myNum[] = {2,6,4,1,5}; 4 //从 ...
- 【已解决】初始化 Hive 元数据库报错slf4j-log4j12-1.7.25.jar包冲突
错误log描述 [root@hadoop102 hive]# schematool -initSchema -dbType mysql -verboseSLF4J: Class path contai ...
- nginx使用入门的笔记
本文于2016年4月底完成,发布在个人博客网站. 考虑个人博客因某种原因无法修复,于是在博客园安家,之前发布的文章逐步搬迁过来. 从源码安装nginx 下载软件 编译nginx,必备pcre,zlib ...
- ABA问题的本质及其解决办法
目录 简介 第一类问题 第二类问题 第一类问题的解决 第二类问题的解决 总结 简介 CAS的全称是compare and swap,它是java同步类的基础,java.util.concurrent中 ...
- 1.NCC算法实现及其优化[基础实现篇]
NCC算法实现及其优化 本文将集中探讨一种实现相对简单,效果较好的模板匹配算法(NCC) \[R(x,y)= \frac{ \sum_{x',y'} (T'(x',y') \cdot I'(x+x', ...
- SQL 查询优化指南:SELECT、SELECT DISTINCT、WHERE 和 ORDER BY 详解
SELECT 关键字 SQL的SELECT语句用于从数据库中选择数据.SELECT语句的基本语法如下: SELECT column1, column2, ... FROM table_name; 其中 ...
- openGauss3.1.0 版本的gs_stack功能解密
openGauss3.1.0 版本的 gs_stack 功能解密 不管是测试还是研发,工作中总有遇到各种各样的问题.比如,你有没有遇到过在数据库中执行某个 SQL,却一直不返回结果,这时候的你是不是非 ...
- Bash下切换conda环境
背景:很多时候实验命令都是基于Linux系统的,但是很多人的电脑是window系统的. 使用git自带的Bash可以运行linux命令,不过有时候在bash中想使用conda环境的时候比较麻烦,具体做 ...
- 一、Unity调用Xcode封装方法(工程引用文件)
1.Xcode新建Static Library 工程 (我起的名字是UnityExtend 可以在接下来的图中看到) 2.打包unity ios工程 unity打包ios 打出Xcode工程 3.打开 ...
- Android Studio制作简单登录界面
实现目标 应用线性布局设计登录界面,要求点击输入学号时弹出数字键盘界面,点击输入密码时弹出字母键盘,出现的文字.数字.尺寸等全部在values文件夹下相应.xml文件中设置好,使用时直接引用.当用户名 ...