Redis稳定性之战:AOF日志支撑数据持久化
1 介绍
AOF(Append Only File)持久化:以独立日志的方式存储了 Redis 服务器的顺序指令序列,并只记录对内存进行修改的指令。
当Redis服务发生雪崩等故障时,可以重启服务并重新执行AOF文件中的指令达到恢复数据的目的。也就是说,通过重放(replay),来重新建立 Redis 当前实例的内存数据结构。这种模式有没有很熟悉,可以联想到MySQL主从同步时的relay log。
相对于咱们上一篇介绍的《RDB内存快照提供持久化能力》定点快照的做法,AOF的主要作用是解决了数据持久化的实时性,目前已经是Redis持久化的主流方式。
2 AOF实现日志记录
2.1 开启AOF日志记录
1、 开启AOF日志记录:在redis.conf文件中,找到 APPEND ONLY MODE 设置
appendonly yes # 默认不开启, 为 no
2、配置默认文件名:在redis.conf文件中设置
appendfilename “appendonly.aof”
2.2 执行流程
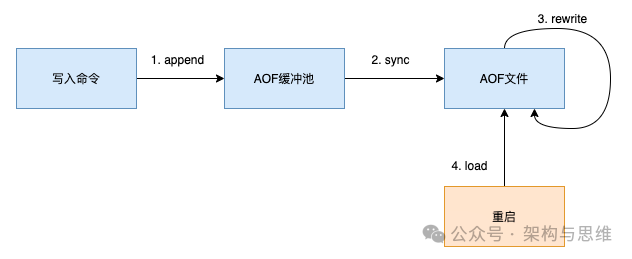
流程如上图所示,我们解析如下:
2.2.1 将所有的写命令(set、hset)Append 到aof_buf缓冲区中
Redis 接收到 set keyName someValue 命令的时候,会先将数据写到内存,Redis 会按照如下格式写入 AOF 文件。
*3:表示当前指令分为三个部分,每个部分都是$ +数字开头,后面是3部分的具体内容:指令、键、值。- 数字:表示这部分的命令、键、值多占用的字节大小。比如
$3表示这部分包含 3 个字符,也就是 set 的长度。
我们看看一个典型的aof文件示例,为了清晰表示,下面的注释都是手动加的:
[root@localhost bin]#vim appendonly.aof
# 执行 set key value
*3
$3 # 这边代表set命令,长度为3
set
$9
user_name # 这边代表keyName,长度为9
$5
brand # 这边代表keyValue,长度为5
# 执行 mset key1 1 ,key2 2 ,key33 3
# aof日志如下:
*7 # 本批命令需要往下读7行非 $ 开始的命令
$4 #接着读取4个字节宽度,‘mset’长度为4,记为 $4
mset
$4 #接着读取4个字节宽度,‘key1’长度为4,记为 $4
key1
$1 #接着读取1个字节宽度,‘1’长度为1,记为 $1
1
$4
key2
$1
2
$5 #接着读取的字节宽度,‘$key33’长度为5,记为 $5
key33
$1
3
2.2.2 AOF缓冲区根据策略向硬盘做sync同步
AOF为什么把命令append到aof_buf中,然后再进行同步?
这是因为Redis使用单进程响应命令(参考笔者这篇《深刻理解高性能Redis的本质》),如果每次写AOF文件命令都直接持久化到硬盘,那么操作会是不是被间断,且性能完全取决于硬盘I/O负载。这个跟 MySQL 就没啥区别了。
先写入缓冲区aof_buf中,Redis可以提供多种缓冲区同步硬盘的策略,在性能、安全、数据可靠性方面做出平衡。
同步策略需关注以下几个配置:
1、 appendfsync 模式
appendfsync always # 接受写命令后立即写入磁盘,强持久化但执行慢,不推荐
appendfsync everysec # 每秒写入磁盘一次, 性能和持久化方面做了折中, 推荐
appendfsync no # 依赖操作系统自身同步的配置和策略,性能较佳,但是没法保证实时和完全持久化
2、no-appendfsync-on-rewrite
在 AOF 重写期间是否禁用 fsync。这可以提高重写性能,但可能会增加数据丢失的风险。
# 默认值:no
# 可选值:yes 或 no
no-appendfsync-on-rewrite yes
2.2.3 AOF文件Rewrite实现压缩
随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩减负的目的,避免AOF文件过大导致性能和数据可靠性问题。
重写后的AOF文件变小的原因主要有以下几点:
1、进程内已超时的数据不再写入:在重写过程中,Redis不会将已经超时的数据写入新的AOF文件,这有助于减少不必要的数据记录。
2、删除无效命令:旧的AOF文件中可能包含无效的命令,如del key1、hdel key2、srem keys、set a111等。重写过程会识别并删除这些无效命令,只保留最终数据的写入命令,从而减小了文件大小。
3、合并多条写命令:为了进一步优化AOF文件的大小,重写过程会将多条写命令合并为一个。例如,lpush list a、lpush list b、lpush list c可以合并为lpush list a b c。这种合并减少了命令的数量,进而减小了AOF文件的大小。
4、防止单条命令过大:对于某些操作类型(如list、set、hash、zset),为了防止单条命令过大造成客户端缓冲区溢出,重写过程会以64个元素为界拆分多条命令。虽然这在一定程度上可能增加了命令的数量,但它确保了每条命令的大小都在可控范围内,有助于维持整体文件大小的合理性。
总之AOF重写降低了文件占用空间,同时提升加载性能,因为更小的AOF 文件可以更快地被Redis加载。
AOF重写关注以下配置:
1、auto-aof-rewrite-percentage
触发 AOF 重写的增长百分比。例如,如果当前 AOF 文件大小是 100MB,并且这个值设置为 100,那么当 AOF 文件增长到 200MB 时,说明增长了100%,Redis 会尝试重写 AOF。
# 默认值:`100`
`auto-aof-rewrite-percentage 100`
2、auto-aof-rewrite-min-size
AOF 文件的最小大小,以便触发重写。即使 AOF 文件的增长百分比超过了 auto-aof-rewrite-percentage 设置的值,但如果文件大小小于这个值,Redis 也不会触发重写。
# 默认值:`64mb`
auto-aof-rewrite-min-size 64mb
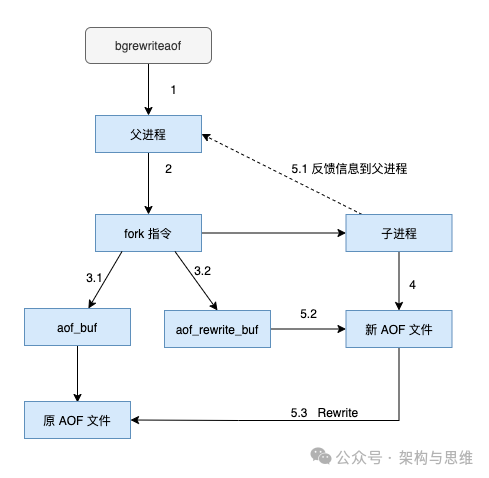
2.2.4 故障重启时的数据恢复
当Redis服务器重启时,可以加载AOF文件进行数据恢复。
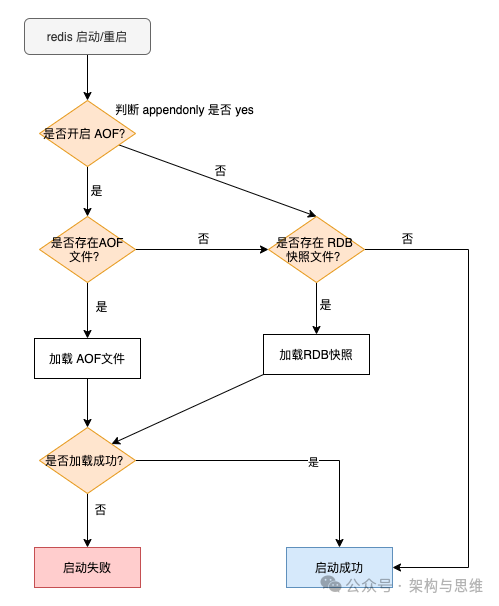
流程如下:
- 当AOF和RDB文件同时存在时,优先加载AOF
- 若关闭了AOF(apendonly no),则加载RDB文件
- 加载AOF/RDB成功之后,redis重启成功。如果无相关的持久化,则直接启动成功。
- 如果AOF/RDB 数据恢复存在错误,则启动失败,并打印输出错误信息
2.3 RDB和AOF的比较和混合持久化
咱们上一篇介绍了《RDB内存快照提供持久化能力》定点快照的用户,那RDB跟AOF究竟孰优孰虑?
现实情况下,无论使用RDB或者AOF都差点意思。使用 rdb 来恢复内存状态,势必会丢失一部分数据。使用 AOF 日志重放,重放对性能有一定的影响,而且在 Redis 实例很大的情况下,需要花费很长的时间。
Redis 4.0 解决了这个问题,才用了一个新的持久化模式——混合持久化,该 混合模式 默认是关闭状态的。
将 RDB 文件的内容和 rdb快照时间点之后的增量的 AOF 日志文件存在一起。这时候 AOF 日志不需要再是全量的日志,而是最近一次快照时间点之后到当下发生的增量 AOF 日志,通常这部分 AOF 日志很小。
所以执行有如下顺序:
- 查找rdb内容,如果存在先加载 rdb内容再 重放剩余的 aof。
- 没有rdb内容,直接以aof格式重放整个文件。
这样快照就不用频繁的执行,同时由于 AOF 只需要记录最近一次快照之后的数据,不需要记录所有的操作,避免了出现单次重放文件过大的问题。
开启混合持久化模式:
aof-use-rdb-preamble yes
这个设置告诉Redis在AOF重写时使用混合持久化模式。当这个选项设置为yes时,重写后的AOF文件将包含RDB格式的数据前缀和AOF格式的增量修改操作。
总结
- RDB提供了快照模式,记录某个时间的Redis内存状态。RDB设计了 bgsave 和写时复制,尽可能避免执行快照期间对读写指令的影响,但是频繁快照会给磁盘带来压力以及 fork 阻塞主线程。需把握频率。
- AOF 日志存储了 Redis 服务的顺序指令序列,通过重放(replay)指令来写入日志文件,并通过写回策略来避免高频读写给Redis带来压力。
- RDB快照的照片时间间隔,必然会带来数据缺失,如果允许分钟级别的数据丢失,可以只使用 RDB。
- 如果只用 AOF,写回策略优先使用 everysec 的配置选项,因为它在可靠性和性能之间取了一个平衡。
- 数据不能丢失时,内存快照和 AOF 的混合使用是一个很好的选择。
Redis稳定性之战:AOF日志支撑数据持久化的更多相关文章
- 八十六:redis之RDB和AOF两种数据持久化机制
详见:http://redisdoc.com/persistence/index.html redis.conf RDB机制 改为5秒内1次 文件已生成 关闭RDB,注释掉3个save,重启redis ...
- redis RDB快照和AOF日志持久化配置
Redis持久化配置 Redis的持久化有2种方式 1快照 2是日志 Rdb快照的配置选项: save 900 1 // 900内,有1条写入,则产生快照 save 300 1000 ...
- Redis设计与实现2.2:数据持久化
数据持久化 这是<Redis设计与实现>系列的文章,系列导航:Redis设计与实现笔记 RDB持久化 RDB 持久化功能所生成的 RDB 文件是一个经过压缩的二进制文件,通过该文件可以还原 ...
- Redis之RDB与AOF 笔记
AOF定义:以日志的形式记录每个操作,将Redis执行过的所有指令全部记录下来(读操作不记录),只许追加文件但不可以修改文件,Redis启动时会读取AOF配置文件重构数据 换句话说,就是Redis重启 ...
- Redis之RDB与AOF
AOF定义:以日志的形式记录每个操作,将Redis执行过的所有指令全部记录下来(读操作不记录),只许追加文件但不可以修改文件,Redis启动时会读取AOF配置文件重构数据 换句话说,就是Redis重启 ...
- Redis基础—了解Redis是如何做数据持久化的
之前的文章介绍了Redis的简单数据结构的相关使用和底层原理,这篇文章我们就来聊一下Redis应该如何保证高可用. 数据持久化 我们知道虽然单机的Redis虽然性能十分的出色, 单机能够扛住10w的Q ...
- redis启动加载过程、数据持久化
背景 公司一年的部分业务数据放在redis服务器上,但数据量比较大,单纯的string类型数据一年就将近32G,而且是经过压缩后的. 所以我在想能否通过获取string数据的时间改为保存list数据类 ...
- 【Azure Redis 缓存】Windows和Linux系统本地安装Redis, 加载dump.rdb中数据以及通过AOF日志文件追加数据
任务描述 本次集中介绍使用Windows和Linux()搭建本地Redis服务器的步骤,从备份的RDB文件中加载数据,以及如何生成AOF文件和通过AOF文件想已经运行的Redis追加数据. 操作步骤 ...
- Redis 中的数据持久化策略(AOF)
上一篇文章,我们讲的是 Redis 的一种基于内存快照的持久化存储策略 RDB,本质上他就是让 redis fork 出一个子进程遍历我们所有数据库中的字典,进行磁盘文件的写入. 但其实这种方式是有缺 ...
- Redis的持久化的两种方式drbd以及aof日志方式
redis的持久化配置: 主要包括两种方式:1.快照 2 日志 来看一下redis的rdb的配置选项和它的工作原理: save 900 1 // 表示的是900s内,有1条写入,则产生快照 save ...
随机推荐
- python快速入门【三】-----For 循环、While 循环
python入门合集: python快速入门[一]-----基础语法 python快速入门[二]----常见的数据结构 python快速入门[三]-----For 循环.While 循环 python ...
- LyScript 实现绕过反调试保护
LyScript插件中内置的方法可实现各类反调试以及屏蔽特定API函数的功能,这类功能在应对病毒等恶意程序时非常有效,例如当程序调用特定API函数时我们可以将其拦截,从而实现保护系统在调试时不被破坏的 ...
- 在K8s中,提供的DNS组件是什么?有什么特性?
在Kubernetes (K8s)集群中,用于内部DNS服务的组件已经从早期的kube-dns过渡到了coredns. kube-dns(已弃用): 在Kubernetes 1.10版本之前,kube ...
- 7.函数的使用--《Python编程:从入门到实践》
7.1 python 中函数的定义 python 中函数使用 def 定义: def greet_user(): 7.2 传参的传递 普通实参的传毒,可以与 C++ 相同,即按顺序传递. 7. ...
- MySQL 报错:ERROR 2002 (HY000): Can't connect to local MySQL server through socket
MySQL 报错:ERROR 2002 (HY000): Can't connect to local MySQL server through socket 一.错误现场还原: 下面我们通过三种方式 ...
- [Spring 6.0源码解析] @Configuration注解源码解析
Spring 6.0源码解析之@Configuration 首先写一个启动代码: public class ConfigurationAnnotationTest { private static f ...
- [JVM]逃逸分析
逃逸分析 JVM的内存分配策略 首先回顾一下JVM的内存分配策略. JVM的内存包括方法区.堆.虚拟机栈.本地方法栈.程序计数器.一般情况下JVM运行时的数据都是存在栈和堆上的.栈用来存放一些基本变量 ...
- CF1886
A 分类讨论. B 二分. C 题意:给定一个字符串 \(s\).记 \(s_i\) 为将 \(s\) 删去 \(i\) 个字符,使得剩余字符串字典序最小得到的字符串.令 \(S=s_0+s_1+\d ...
- NC14545 经商
题目链接 题目 题目描述 小d是一个搞房地产的土豪.每个人经商都有每个人经商的手段,当然人际关系是需要放在首位的. 小d每一个月都需要列出来一个人际关系表,表示他们搞房地产的人的一个人际关系网,但是他 ...
- Swoole从入门到入土(24)——多进程[进程管理器Process\Manager]
Swoole提供的进程管理器Process\Manage,基于 Process\Pool 实现.可以管理多个进程.相比与 Process\Pool,可以非常方便的创建多个执行不同任务的进程,并且可以控 ...