08-Redis系列之-Redis布隆过滤器,MySQL主从,Django读写分离
Redis实现布隆过滤器
前言
布隆过滤器使用场景
比如有如下几个需求:
- 原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中?
解决办法一:将10亿个号码存入数据库中,进行数据库查询,准确性有了,但是速度会比较慢。
解决办法二:将10亿号码放入内存中,比如Redis缓存中,这里我们算一下占用内存大小:10亿*8字节=8GB,通过内存查询,准确性和速度都有了,但是大约8gb的内存空间,挺浪费内存空间的。
接触过爬虫的,应该有这么一个需求,需要爬虫的网站千千万万,对于一个新的网站url,我们如何判断这个url我们是否已经爬过了?
解决办法还是上面的两种,很显然,都不太好。
同理还有垃圾邮箱的过滤。
那么对于类似这种,大数据量集合,如何准确快速的判断某个数据是否在大数据量集合中,并且不占用内存,布隆过滤器应运而生了。
布隆过滤器简介
一种数据结构,是由一串很长的二进制向量组成,可以将其看成一个二进制数组。既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。
它是一种 space efficient 的概率型数据结构,用于判断一个元素是否在集合中。
当布隆过滤器说,某个数据存在时,这个数据可能不存在;当布隆过滤器说,某个数据不存在时,那么这个数据一定不存在。
大致数据结构图

布隆过滤器优缺点
优点很明显,二进制组成的数组,占用内存极少(节省内存),并且插入和查询速度都足够快。
随着数据的增加,误判率会增加;还有无法判断数据一定存在;另外还有一个重要缺点,无法删除数据。(布隆过滤器是不支持删除数据的,如果需要删除数据则需要重建缓存信息。)
布隆过滤器使用多次hash计算,也会存在hash冲突情况。这会导致一个问题,当检测过滤器是否存在数据时,检测到存在,实际不一定存在。相同的检测到不存在,则缓存中一定不存在。
布隆过滤器原理
BloomFilter的算法是,首先分配一块内存空间做 bit 数组,数组的 bit 位初始值全部设为 0。
加入元素时,采用 k 个相互独立的 Hash 函数计算,然后将元素 Hash 映射的 K 个位置全部设置为 1。
检测 key 是否存在,仍然用这 k 个 Hash 函数计算出 k 个位置,如果位置全部为 1,则表明 key 存在,否则不存在。
如下图所示
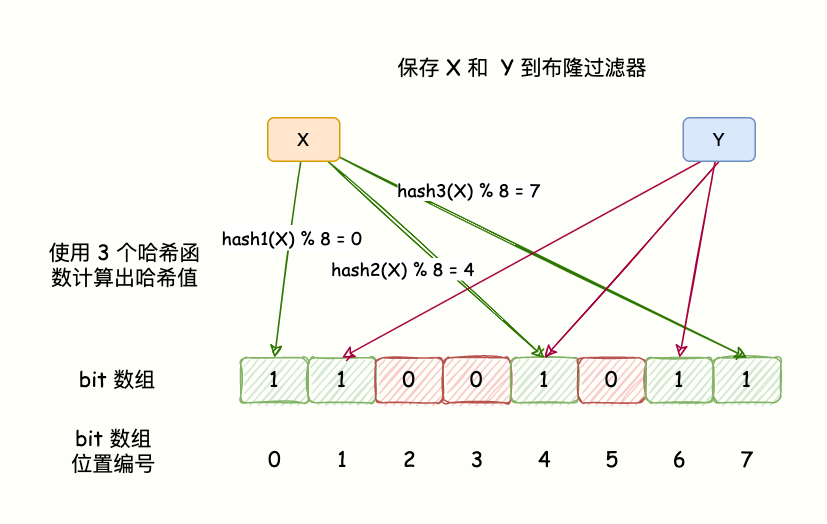
哈希函数会出现碰撞,所以布隆过滤器会存在误判。
这里的误判率是指,BloomFilter 判断某个 key 存在,但它实际不存在的概率,因为它存的是 key 的 Hash 值,而非 key 的值。
所以有概率存在这样的 key,它们内容不同,但多次 Hash 后的 Hash 值都相同。
对于 BloomFilter 判断不存在的 key ,则是 100% 不存在的,反证法,如果这个 key 存在,那它每次 Hash 后对应的 Hash 值位置肯定是 1,而不会是 0。布隆过滤器判断存在不一定真的存在。
为什么不允许删除元素呢?
删除意味着需要将对应的 k 个 bits 位置设置为 0,其中有可能是其他元素对应的位。
因此 remove 会引入 false negative,这是绝对不被允许的。
文档
https://redis.io/docs/stack/bloom/
https://github.com/RedisBloom/RedisBloom/
扩展
布谷鸟过滤器(为了解决布隆过滤器不能删除元素的问题)
操作
docker安装
docker详解:https://www.cnblogs.com/hkwJsxl/p/17164139.html
RedisBloom需要先进行安装,推荐使用Docker进行安装,简单方便(或使用直接编译安装)
1.拉取镜像
docker pull redislabs/rebloom:latest
1.1或使用阿里云上的(速度会快点)
docker pull registry.cn-hangzhou.aliyuncs.com/hankewei/hkwimage:redisbloom2.4.5
docker tag registry.cn-hangzhou.aliyuncs.com/hankewei/hkwimage:redisbloom2.4.5 redislabs/rebloom:2.4.5
docker rmi registry.cn-hangzhou.aliyuncs.com/hankewei/hkwimage:redisbloom2.4.5
2.运行
docker run -di -p 6666:6379 --name redis-redisbloom redislabs/rebloom:2.4.5
3.进入
docker exec -it redis-redisbloom /bin/bash
4.登录到Redis
redis-cli
# 查看Redis模块
127.0.0.1:6379> info Modules
# Modules
module:name=bf,ver=20206,api=1,filters=0,usedby=[],using=[],options=[]
第二种安装方式(编译安装)
当然也可以直接编译进行安装
1.git克隆
git clone https://github.com/RedisBloom/RedisBloom.git
2.解压缩
tar -zxf RedisBloom-2.4.5.tar
3.进入文件
cd RedisBloom-2.4.5
4.编译,会生成一个rebloom.so文件
make
5.安装集成
需要修改 redis.conf 文件,新增 loadmodule配置,并重启 Redis。
loadmodule /home/RedisBloom-2.4.5/redisbloom.so
如果是集群,则每个实例的配置文件都需要加入配置。
6.启动
redis-server /home/redis/conf/redis.conf
如果没有更改配置文件,需要指定参数
redis-server --loadmodule /home/RedisBloom-2.4.5/redisbloom.so
redis-cli -h 127.0.0.1 -p 6379
此模块不仅仅实现了布隆过滤器,还实现了 CuckooFilter(布谷鸟过滤器),以及 TopK 功能。CuckooFilter 是在 BloomFilter 的基础上主要解决了BloomFilter不能删除的缺点。先来看看 BloomFilter,后面介绍一下 CuckooFilter。
基本命令
bf.add 添加元素到布隆过滤器
bf.madd 添加多个元素到布隆过滤器,bf.add只能添加一个
bf.exists 判断元素是否在布隆过滤器
bf.mexists 判断多个元素是否在布隆过滤器
添加数据
# 单个添加
127.0.0.1:6379> bf.add bfkey 1
(integer) 1
127.0.0.1:6379> bf.add bfkey 2
(integer) 1
127.0.0.1:6379> bf.add bfkey 3
(integer) 1
127.0.0.1:6379> bf.add bfkey 3
(integer) 0
# 批量添加
127.0.0.1:6379> bf.madd bfkey 4 5 6
1) (integer) 1
2) (integer) 1
3) (integer) 1
# 通过添加会发现,如果元素已经存在,则返回的是0值。
检测数据
# 检测单个值
127.0.0.1:6379> bf.exists bfkey 1
(integer) 1
127.0.0.1:6379> bf.exists bfkey 2
(integer) 1
127.0.0.1:6379> bf.exists bfkey 10
(integer) 0
# 批量检测
127.0.0.1:6379> bf.mexists bfkey 1 2 3 10
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 0
# 通过检测会发现,如果元素不存在,则返回的是0值。
误判率
布隆过滤器在第一次add的时候自动创建基于默认参数的过滤器,Redis还提供了自定义参数的布隆过滤器。
在add之前使用bf.reserve指令显式创建,其有3个参数,key,error_rate, initial_size,错误率越低,需要的空间越大,error_rate表示预计错误率,initial_size参数表示预计放入的元素数量,当实际数量超过这个值时,误判率会上升,所以需要提前设置一个较大的数值来避免超出。
默认的error_rate是0.01,initial_size是100。
利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
# 误判率测试
import redis
client = redis.Redis(host='10.0.0.10', port=6666)
size = 100000
count = 0
client.execute_command("bf.reserve", "hkw", 0.001, size) # 如果没有这一行,误判率会高很多(error rate: 1.096%)
for i in range(size):
client.execute_command("bf.add", "hkw", "xxx%d" % i)
result = client.execute_command("bf.exists", "hkw", "xxx%d" % (i + 1))
if result == 1:
print(i)
count += 1
print("size: {} , error rate: {}%".format(size, round(count / size * 100, 5)))
"""
结果:
85547
91103
93019
size: 100000 , error rate: 0.003%
"""
MySQL主从搭建(Docker实现)
docker详解:https://www.cnblogs.com/hkwJsxl/p/17164139.html
主从同步的流程或原理
- master会将变动记录到二进制日志里面
- master有一个I/O线程将二进制日志发送到slave
- slave有一个I/O线程把master发送的二进制写入到relay日志里面
- slave有一个SQL线程,按照relay日志处理slave的数据
开始搭建
0.创建目录
mkdir -p /home/mysql11/data/ /home/mysql11/conf /home/mysql11/logs/ /home/mysql22/data/ /home/mysql22/conf /home/mysql22/logs/
配置文件
主库的配置文件
1.主库的配置(主从server-id不能相同)
vim /home/mysql11/conf/my.cnf
[mysqld]
# 主服务器唯一ID
server-id=1
# 启用二进制日志
log-bin=mysql-bin
# 设置需要复制的数据库,需要复制的主数据库名字(默认同步所有数据库)
# binlog-do-db=testdb
# 设置logbin格式
binlog_format=STATEMENT
从库的配置文件
2.从库的配置
vim /home/mysql22/conf/my.cnf
[mysqld]
#从服务器唯一ID
server-id=2
#日志
log-bin=mysql-slave-bin
#启用中继日志
relay-log=mysql-relay
启动两个mysql容器
启动主库容器
3.启动主库容器(挂载外部目录,端口映射成33306,密码设置为root123456)
docker run -di -v /home/mysql11/data/:/var/lib/mysql -v /home/mysql11/conf:/etc/mysql/conf.d -v /home/mysql11/logs/:/var/log/mysql -p 7777:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=root123456 mysql:mysql8.0.32
启动从库容器
4.启动从库容器(挂载外部目录,端口映射成33307,密码设置为root123456)
docker run -di -v /home/mysql22/data/:/var/lib/mysql -v /home/mysql22/conf:/etc/mysql/conf.d -v /home/mysql22/logs/:/var/log/mysql -p 7778:3306 --name mysql-slave -e MYSQL_ROOT_PASSWORD=root123456 mysql:mysql8.0.32
报错处理
# 错误信息
1.
2023-03-04 13:48:56+00:00 [ERROR] [Entrypoint]: mysqld failed while attempting to check config
command was: mysqld --privileged=true --verbose --help --log-bin-index=/tmp/tmp.Biw5OQ23f8
mysqld: Can't read dir of '/etc/mysql/conf.d/' (OS errno 2 - No such file or directory)
mysqld: [ERROR] Stopped processing the 'includedir' directive in file /etc/my.cnf at line 36.
mysqld: [ERROR] Fatal error in defaults handling. Program aborted!
2.
2023-03-04T14:33:20.604801Z 1 [ERROR] [MY-012956] [InnoDB] Cannot allocate memory for the buffer pool
2023-03-04T14:33:20.628786Z 1 [ERROR] [MY-012930] [InnoDB] Plugin initialization aborted with error Generic error.
2023-03-04T14:33:20.637344Z 1 [ERROR] [MY-010334] [Server] Failed to initialize DD Storage Engine
2023-03-04T14:33:20.669372Z 0 [ERROR] [MY-010020] [Server] Data Dictionary initialization failed.
2023-03-04T14:33:20.670085Z 0 [ERROR] [MY-010119] [Server] Aborting
# 注意点
1.mysql一直起不来,原因是不同的mysql版本可能目录结构不同,原先挂载的/home/mysql11/conf:/etc/mysql报错,后改为了/home/mysql11/conf:/etc/mysql/conf.d
2.log-bin=mysql-bin 这个配置不要随便更改
3.第二个报错解决:主要是Cannot allocate memory for the buffer pool
这是因为MySQL内存不足导致启动失败
查询内存的命令:free -h
解决方法:
增加swap交换空间解决问题:
dd if=/dev/zero of=/swapfile bs=1M count=1024
mkswap /swapfile
swapon /swapfile
增加自动挂载:
sudo vim /etc/fstab
在下面添加:
/swapfile swap swap defaults 0 0
重启mysql问题解决
创建用户并授权
5.创建用户并授权
5.0进入主库中
docker exec -ti mysql-master /bin/bash
mysql -uroot -p
root123456
5.1创建用户
CREATE USER 'hkw'@'localhost' IDENTIFIED BY 'root123456';
CREATE USER 'hkw'@'%' IDENTIFIED BY 'root123456';
5.2设定权限
grant all privileges on *.* to 'hkw'@'localhost';
grant all privileges on *.* to 'hkw'@'%';
5.3刷新权限
flush privileges;
5.4查看主服务器状态,可以看到日志文件的名字,和现在处在哪个位置
show master status;
主从配置
6.0配置详解
/*
change master to
master_host='MySQL主服务器IP地址',
master_port=端口号,
master_user='之前在MySQL主服务器上面创建的用户名',
master_password='之前创建的密码',
master_log_file='MySQL主服务器状态中的二进制文件名'(上条命令中有),
master_log_pos='MySQL主服务器状态中的position值';
*/
6.1连接从库,配置连接主库
docker exec -ti mysql-slave /bin/bash
mysql
6.2输入命令
change master to master_host='10.0.0.10',master_port=7777,master_user='hkw',master_password='root123456',master_log_file='mysql-bin.000003',master_log_pos=0;
6.3启用从库
start slave;
6.4查看从库状态
show slave status\G;
这两个是yes表示配成功(可能要等待一会查看)
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
测试
7.0测试(可有可无)
navicat连一连
7.1在主库上创建数据库t1
create database t1;
use t1;
7.2创建表
create table t1 (id int not null PRIMARY KEY AUTO_INCREMENT, name varchar(100)not null, age tinyint);
7.3插入数据
insert t1 (id,name,age) values(1,'xxx',20),(2,'yyy',21),(3,'zzz',22);
Django实现读写分离
0.上面的主从搭建好
1.在setting中配置
DATABASES = {
# 主库
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 't1',
'USER': 'hkw',
'PASSWORD': 'root123456',
'HOST': '10.0.0.10',
'PORT': 7777,
},
# 从库
'mysql_slave': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 't1',
'USER': 'hkw',
'PASSWORD': 'root123456',
'HOST': '10.0.0.10',
'PORT': 7778,
},
}
2.手动指定使用的主库还是从库(默认不写就是default)
写库(主)
res=models.Book.objects.using('default').create(name='mysql_test', age=22)
读库(从)
res=models.Book.objects.using('mysql_slave').all()
3.自动指定(写router和配置setting)
3.0写个类
class Router:
def db_for_read(self, model, **hints):
print('read', model, hints)
return 'mysql_slave'
def db_for_write(self, model, **hints):
# model, hints:model对象,表创建的实例对象
print('write', model, hints)
return 'default'
3.1在setting中注册(类的导入路径)
DATABASE_ROUTERS = ['extension.models.master_and_slave.Router', ]
4.以后只要是写操作,就会用主库default,只要是读操作自动去从库mysql_slave
5.更细粒度(分库分表,只有大数据量大并发的时候会用到)
class Router:
def db_for_read(self, model, **hints):
if model._meta.model_name == 'book':
return 'mysql_slave'
else:
return 'default'
def db_for_write(self, model, **hints):
return 'default'
# Django migrate报错处理:
django.db.utils.OperationalError: (1665, 'Cannot execute statement: impossible to write to binary log since BINLOG_FORMAT = STATEMENT and at least one table uses a storage engine limited to row-based logging. InnoDB is limited to row-logging when transaction isolation level is READ COMMITTED or READ UNCOMMITTED.')
解决:
mysql> SET GLOBAL binlog_format = 'ROW';
mysql> show variables like 'binlog_format';
08-Redis系列之-Redis布隆过滤器,MySQL主从,Django读写分离的更多相关文章
- Mysql主从配置+读写分离
Mysql主从配置+读写分离 MySQL从5.5版本开始,通过./configure进行编译配置方式已经被取消,取而代之的是cmake工具.因此,我们首先要在系统中源码编译安装cmake工具. ...
- Mysql主从配置+读写分离(转)
MySQL从5.5版本开始,通过./configure进行编译配置方式已经被取消,取而代之的是cmake工具.因此,我们首先要在系统中源码编译安装cmake工具. 注:安装前须查看是否已经安装了 ...
- 使用docker 实现MySQL主从同步/读写分离
1. 利用 docker 实现 mysql 主从同步 / 读写分离 为了保证数据的完整和安全,mysql 设计了主从同步,一个挂掉还可以用另个.最近重构论坛,想来改成主从吧.担心失误,就先拿 dock ...
- 聊聊Mysql主从同步读写分离配置实现
Hi,各位热爱技术的小伙伴您们好,好久没有写点东西了,今天写点关于mysql主从同步配置的操作日志同大家一起分享.最近自己在全新搭建一个mysql主从同步读写分离数据库简单集群,我讲实际操作步骤整理分 ...
- Docker容器启动Mysql,Docker实现Mysql主从,读写分离
Docker容器启动Mysql,Docker实现Mysql主从,读写分离 一.Docker文件编排 二.配置主从复制 2.1 配置master 2.2 配置slave 三.验证主从复制 3.1 mas ...
- docker-compose.yml样例(mysql主从+mycat读写分离)
Docker-compose.yml文件示例 1.mysql主从复制的docker-compose.yml文件 # cat docker-compose.yml version: '2' # 这个ve ...
- mysql 主从同步-读写分离
主从同步与读写分离测试 一. 实验环境(主从同步) Master centos 7.3 192.168.138.13 Slave ...
- mysql主从同步--读写分离。
1.mysql 安装参考 https://www.cnblogs.com/ttzzyy/p/9063737.html 2. 主mysql,从mysql 指定配置文件启动 mysqld --defaul ...
- 关系型数据库MySQL主从同步-读写分离
1.环境准备 我的数据库版本是MySQL 5.6 MySQL主机至少两个实例,可以是多实例,可以是多台主机 关闭selinux,关闭防火墙等基础优化 2.安装 yum -y install make ...
- MySQL主从及读写分离配置
<<MySQL主从又叫做Replication.AB复制.简单讲就是A和B两台机器做主从后,在A上写数据,B也会跟着写数据,两者数据实时同步>> MySQL主从是基于binlo ...
随机推荐
- [转帖]Sosreport:收集系统日志和诊断信息的工具
https://zhuanlan.zhihu.com/p/39259107 如果你是 RHEL 管理员,你可能肯定听说过 Sosreport :一个可扩展.可移植的支持数据收集工具.它是一个从类 Un ...
- Oracle的awr的学习与整理
Oracle的awr的学习与整理 背景 本来想上周末进行一下总结和汇总 因为周末两天进行了一次长时间的培训.所以没有成行. 只能在工作之余找时间进行总结. 数据库部分自己一个不是很强. 其实也比较抗拒 ...
- 【JS 逆向百例】Ether Rock 空投接口 AES256 加密分析
关注微信公众号:K哥爬虫,持续分享爬虫进阶.JS/安卓逆向等技术干货! 声明 本文章中所有内容仅供学习交流,抓包内容.敏感网址.数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后 ...
- py 学习(c++ to py)
py1: print 2024-01-27 23:18:57 星期六 #这里是注释 # py1 : 基础print总结 ''' aaa 有时候也用三个单引号当注释 但其实是字符串 交互式会输出 ''' ...
- 使用svn.externals(外链)提升美术多个svn目录的svn up速度
svn up多个目录耗时大 svn上的美术资源项目,在打包机上对一个很久没有变化的目录进行svn up也是需要消耗不少时间的,特别打包时需要对多个目录进行svn up,比如空跑54个目录的svn up ...
- clion运行单个c和c++文件(.c.cpp)
运行方法 在clion中安装插件:C/C++Single File Execution 在要执行的cpp文件中添加main函数 在cpp文件的编辑器界面中点右键会出现[Add executable f ...
- NLP文本匹配任务Text Matching [无监督训练]:SimCSE、ESimCSE、DiffCSE 项目实践
NLP文本匹配任务Text Matching [无监督训练]:SimCSE.ESimCSE.DiffCSE 项目实践 文本匹配多用于计算两个文本之间的相似度,该示例会基于 ESimCSE 实现一个无监 ...
- 中文多模态医学大模型智能分析X光片,实现影像诊断,完成医生问诊多轮对话
中文多模态医学大模型智能分析X光片,实现影像诊断,完成医生问诊多轮对话 1.背景介绍介绍 最近,通用领域的大语言模型 (LLM),例如 ChatGPT,在遵循指令和产生类似人类响应方面取得了显著的成功 ...
- conda创建虚拟环境后文件夹中只有conda-meta文件夹,无法将环境添加到IDE中
1.问题描述:anaconda的envs的其中一个环境目录下,没有python.exe文件,只有conda-meta和scripts 平时创建虚拟环境都是: conda create -n test ...
- 在K8S中,节点故障驱逐pod过程时间怎么定义?
在Kubernetes中,节点故障驱逐Pod的过程涉及多个参数和组件的相互作用.以下是该过程的简要概述: 默认设置:在默认配置下,节点故障时,工作负载的调度周期约为6分钟. 关键参数: node-mo ...