spark 先groupby 再从每个group里面选top n
import spark.implicits._
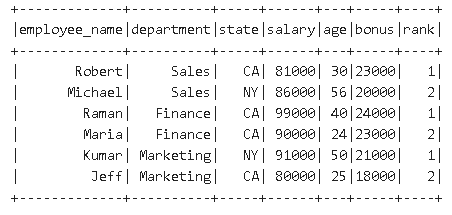
val simpleData = Seq(("James","Sales","NY",90000,34,10000),
("Michael","Sales","NY",86000,56,20000),
("Robert","Sales","CA",81000,30,23000),
("Maria","Finance","CA",90000,24,23000),
("Raman","Finance","CA",99000,40,24000),
("Scott","Finance","NY",83000,36,19000),
("Jen","Finance","NY",79000,53,15000),
("Jeff","Marketing","CA",80000,25,18000),
("Kumar","Marketing","NY",91000,50,21000)
)
val df = simpleData.toDF("employee_name","department","state","salary","age","bonus")
df.show()
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions.Window // Window definition
val w = Window.partitionBy($"department").orderBy(desc("bonus")) // Filter
var df_1 = df.withColumn("rank", rank.over(w)).where($"rank" <= 2) df_1.show()
spark 先groupby 再从每个group里面选top n的更多相关文章
- 点击div全选中再点击取消全选div里面的文字
想做一个就是点击一个div然后实现的功能是div里面的文字都成选中状态,然后就可以利用浏览器的自带的复制功能,任意复制在哪里去了 在网上百度了一下 然后网上的答案感觉很大的范围 然后一些搜索 然后就锁 ...
- radio点击一下选中,再点击恢复未选状态
radio点击一下选中,再点击恢复未选状态 实现方式1: <input type="radio" id="cat" name="ca ...
- Spark中groupBy groupByKey reduceByKey的区别
groupBy 和SQL中groupby一样,只是后面必须结合聚合函数使用才可以. 例如: hour.filter($"version".isin(version: _*)).gr ...
- Spark算子 - groupBy
释义 根据RDD中的某个属性进行分组,分组后形式为(k, [(k, v1), (k, v2), ...]),即groupBy 后组内元素会保留key值 方法签名如下: def groupBy[K](f ...
- spark 笔记 13: 再看DAGScheduler,stage状态更新流程
当某个task完成后,某个shuffle Stage X可能已完成,那么就可能会一些仅依赖Stage X的Stage现在可以执行了,所以要有响应task完成的状态更新流程. ============= ...
- flex 4 写皮肤
皮肤容器:s:SparkSkin 主机组件: [HostComponent("spark.components.Panel")] 绘制: <s:Group left=&qu ...
- Spark在处理数据的时候,会将数据都加载到内存再做处理吗?
对于Spark的初学者,往往会有一个疑问:Spark(如SparkRDD.SparkSQL)在处理数据的时候,会将数据都加载到内存再做处理吗? 很显然,答案是否定的! 对该问题产生疑问的根源还是对Sp ...
- 使用Apache Spark 对 mysql 调优 查询速度提升10倍以上
在这篇文章中我们将讨论如何利用 Apache Spark 来提升 MySQL 的查询性能. 介绍 在我的前一篇文章Apache Spark with MySQL 中介绍了如何利用 Apache Spa ...
- Spark迷思
眼下在媒体上有非常大的关于Apache Spark框架的声音,渐渐的它成为了大数据领域的下一个大的东西. 证明这件事的最简单的方式就是看google的趋势图: 上图展示的过去两年Hadoop和Spar ...
- spark HelloWorld程序(scala版)
使用本地模式,不需要安装spark,引入相关JAR包即可: <dependency> <groupId>org.apache.spark</groupId> < ...
随机推荐
- SpringBoot实现RequestBodyAdvice和ResponseBodyAdvice接口
Spring Boot 提供了一种机制,允许开发者在请求体(RequestBody)和响应体(ResponseBody)被处理之前和之后执行自定义逻辑.这通过 RequestBodyAdvice 和 ...
- AI生成前端组件的价值思考
想法来源 这个想法来源于我自己的需求,我自己首先就是最精准的目标用户,在这个AI时代,我希望AI可以帮我尽量多地干活. 结合自己的日常独立开发情况,发现花在调前端组件样式上的时间很多,因此思考能不能让 ...
- JS原生实现html转pdf / html转图片 (html2canvas.js + jspdf.js )
<button onclick="HtmlToPdf()"> 转储pdf </button> <button onclick="HtmlTo ...
- [oeasy]python0029_放入系统路径_PATH_chmod_程序路径_执行原理
放入路径 回忆上次内容 上次总算可以把 sleep.py 直接执行了 sleep.py文件头部要声明好打开方式 #!/usr/bin/python3 用的是 python3 解释 sleep.py ...
- C#全局键盘监听(Hook)的使用
一.为什么需要全局键盘监听? 在某些情况下应用程序需要实现快捷键执行特定功能,例如大家熟知的QQ截图功能Ctrl+Alt+A快捷键,只要QQ程序在运行(无论是拥有焦点还是处于后台运行状态),都可以按下 ...
- Docker 容器数据:持久化
Docker 容器数据:持久化 每当从镜像创建容器时,它都会创建一个新容器,除了镜像数据之外没有任何数据 意味着如果在提交更改之前删除容器,我们将丢失数据 Docker 应该存在一种将数据的文件系统与 ...
- ChatGPT的作用(附示例)
ChatGPT介绍(内容由ChatGPT生成) ChatGPT是一款基于GPT(生成式预测网络)的聊天机器人,它可以根据用户输入自动生成相应的回复. GPT是由OpenAI开发的一种预测网络模型,其中 ...
- 使用ventoy安装windows10
使用ventoy安装windows10 在ventoy中选择windows10镜像 进入Windows安装界面 下一步,选择现在安装 稍等片刻 选择我没有产品密钥 根据需求选择对应版本 下一步,接受许 ...
- 【C】Re04
一.类型限定符 extern 声明一个变量,extern声明的变量没有存储空间 const 定义一个常量,该常量必须赋值,之后且不允许更改 volatile 防止编译器优化代码??? register ...
- 关于vue按需引入ElMessage和ElMessageBox未被自动引入到auto-important的问题
相信关于按需引入大家应该都会了,不论是官网还是百度一大堆教程 我这边也是参照https://github.com/youlaitech/vue3-element-admin的写法去写的-----需要的 ...