Spark中groupBy groupByKey reduceByKey的区别
groupBy
和SQL中groupby一样,只是后面必须结合聚合函数使用才可以。
例如:
hour.filter($"version".isin(version: _*)).groupBy($"version").agg(countDistinct($"id"), count($"id")).show()
groupByKey
对Key-Value形式的RDD的操作。
例如(取自link):
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "spider", "eagle"), 2)
val b = a.keyBy(_.length)//给value加上key,key为对应string的长度
b.groupByKey.collect
//结果 Array((4,ArrayBuffer(lion)), (6,ArrayBuffer(spider)), (3,ArrayBuffer(dog, cat)), (5,ArrayBuffer(tiger, eagle)))
reduceByKey
与groupByKey功能一样,只是实现不一样。本函数会先在每个分区聚合然后再进行总的统计,如图:
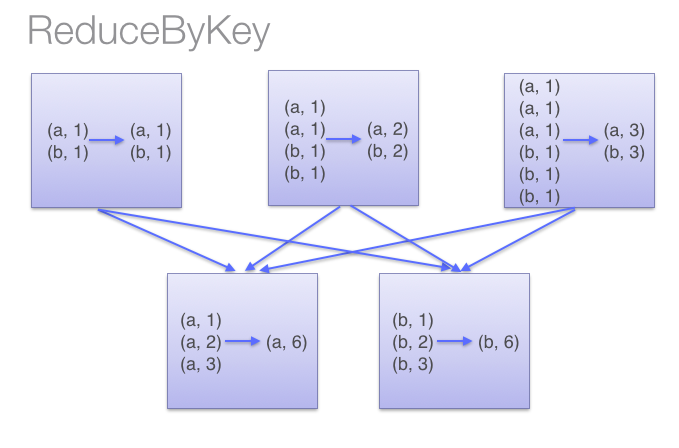
而groupByKey则是
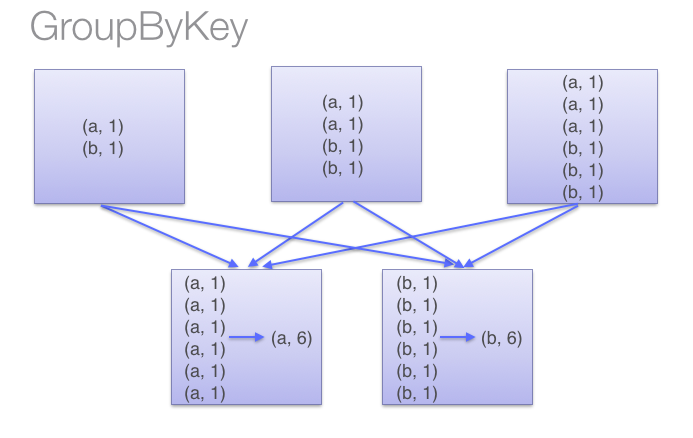
因此,本函数比groupByKey节省了传播的开销,尽量少用groupByKey
参考
- https://www.iteblog.com/archives/1357.html
- http://blog.csdn.net/guotong1988/article/details/50556871
- http://blog.cheyo.net/178.html
Spark中groupBy groupByKey reduceByKey的区别的更多相关文章
- [Spark RDD_add_1] groupByKey & reduceBykey 的区别
[groupByKey & reduceBykey 的区别] 在都能实现相同功能的情况下优先使用 reduceBykey Combine 是为了减少网络负载 1. groupByKey 是没有 ...
- Spark中ml和mllib的区别
转载自:https://vimsky.com/article/3403.html Spark中ml和mllib的主要区别和联系如下: ml和mllib都是Spark中的机器学习库,目前常用的机器学习功 ...
- 015 在Spark中关于groupByKey与reduceByKey的区别
1.groupByKey的源代码 2.groupByKey的使用缺点 不使用groupByKey的主要原因:在大规模的数据下,数据分布不均匀的情况下,可能导致OOM 3.reduceByKey的源代码 ...
- spark中map与flatMap的区别
作为spark初学者对,一直对map与flatMap两个函数比较难以理解,这几天看了和写了不少例子,终于把它们搞清楚了 两者的区别主要在于action后得到的值 例子: import org.apac ...
- Spark中cache和persist的区别
cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间. cache和persist的区别 基于Spark 1.6.1 的源码,可 ...
- Spark中repartition和partitionBy的区别
repartition 和 partitionBy 都是对数据进行重新分区,默认都是使用 HashPartitioner,区别在于partitionBy 只能用于 PairRDD,但是当它们同时都用于 ...
- spark中产生shuffle的算子
Spark中产生shuffle的算子 作用 算子名 能否替换,由谁替换 去重 distinct() 不能 聚合 reduceByKey() groupByKey groupBy() groupByKe ...
- Spark程序使用groupByKey后数据存入HBase出现重复的现象
最近在一个项目中做数据的分类存储,在spark中使用groupByKey后存入HBase,发现数据出现双份( 所有记录的 rowKey 是随机 唯一的 ) .经过不断的测试,发现是spark的运行参 ...
- Spark 中 GroupByKey 相对于 combineByKey, reduceByKey, foldByKey 的优缺点
避免使用GroupByKey 我们看一下两种计算word counts 的方法,一个使用reduceByKey,另一个使用 groupByKey: val words = Array("on ...
随机推荐
- Swift3 获取系统音量和监听系统音量
使用时: //定义滑动条用于显示音量 @IBOutlet weak var volumSlider: UISlider! //处理声音,获取当前音量,并添加监听 handleVolum() 方法内容: ...
- 给定数组a[1,2,3],用a里面的元素来生成一个长度为5的数组,打印出其排列组合
给定数组a[1,2,3],用a里面的元素来生成一个长度为5的数组,打印出其排列组合 ruby代码: def all_possible_arr arr, length = 5 ret = [] leng ...
- 如何使用Git上传项目代码到github
这是我第一次应用git,以下仅供git的初学者参考. github是一个基于git的代码托管平台,付费用户可以建私人仓库,我们一般的免费用户只能使用公共仓库,也就是代码要公开.这对于一般人来说 ...
- HSSFWorkbook 与 XSSFWorkbook
刚开始使用new HSSFWorkbook(new FileInputStream(excelFile))来读取Workbook,对Excel2003以前(包括2003)的版本没有问题,但读取Exce ...
- 【java】Java泛型
一. 泛型概念的提出(为什么需要泛型)? 首先,我们看下下面这段简短的代码: 1 public class GenericTest { 2 3 public static void main(Stri ...
- IDEA使用笔记(一)——使用前的基本设置
前言:记忆不好,有些东西需要的时候又需要找一找,那就不如让“纸和笔”来帮忙记录一下啦!到时候查找也方便,而且是自己的东西印象更加的深刻,说不定还能帮助到他人多好玩的事情! 软件的下载.安装就不记啦!自 ...
- span的赋值与取值
1.<span id="span_id">span的文本</span>的取值. js取<span>的值并不是用document.getEle ...
- 第3章 Python基础-文件操作&函数 文件操作 练习题
一.利用b模式,编写一个cp工具,要求如下: 1. 既可以拷贝文本又可以拷贝视频,图片等文件 2. 用户一旦参数错误,打印命令的正确使用方法,如usage: cp source_file target ...
- df -h和du -sh显示结果不一样的原因及解决
一.背景:一台2T硬盘的mysql服务器,保存电话的CDR信息.按照历史数据的水平,一个月能生成20+GB的文件.然而短短的半年时间,满了?! 登录服务器看谁占了这么大的空间?好吧,slow-quer ...
- 容错处理库Polly使用文档
Design For Failure1. 一个依赖服务的故障不会严重破坏用户的体验.2. 系统能自动或半自动处理故障,具备自我恢复能力. 以下是一些经验的服务容错模式 超时与重试(Timeout an ...