jsoup爬取图片到本地
因为项目需求,需要车辆品牌信息和车系信息,昨天用一天时间研究了jsoup爬取网站信息。项目是用maven+spring+springmvc+mybatis写的。
jsoup开发指南地址:http://www.open-open.com/jsoup/
这个是需要爬取网站的地址 https://car.autohome.com.cn/zhaoche/pinpai/
1.首先在pom.xml中添加依赖
因为需要把图片保存到本地所以又添加了commons-net包
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-net/commons-net -->
<dependency>
<groupId>commons-net</groupId>
<artifactId>commons-net</artifactId>
<version>3.3</version>
</dependency>
2.然后是爬虫代码的实现
@Controller
@RequestMapping("/car/")
public class CarController {
//图片保存路径
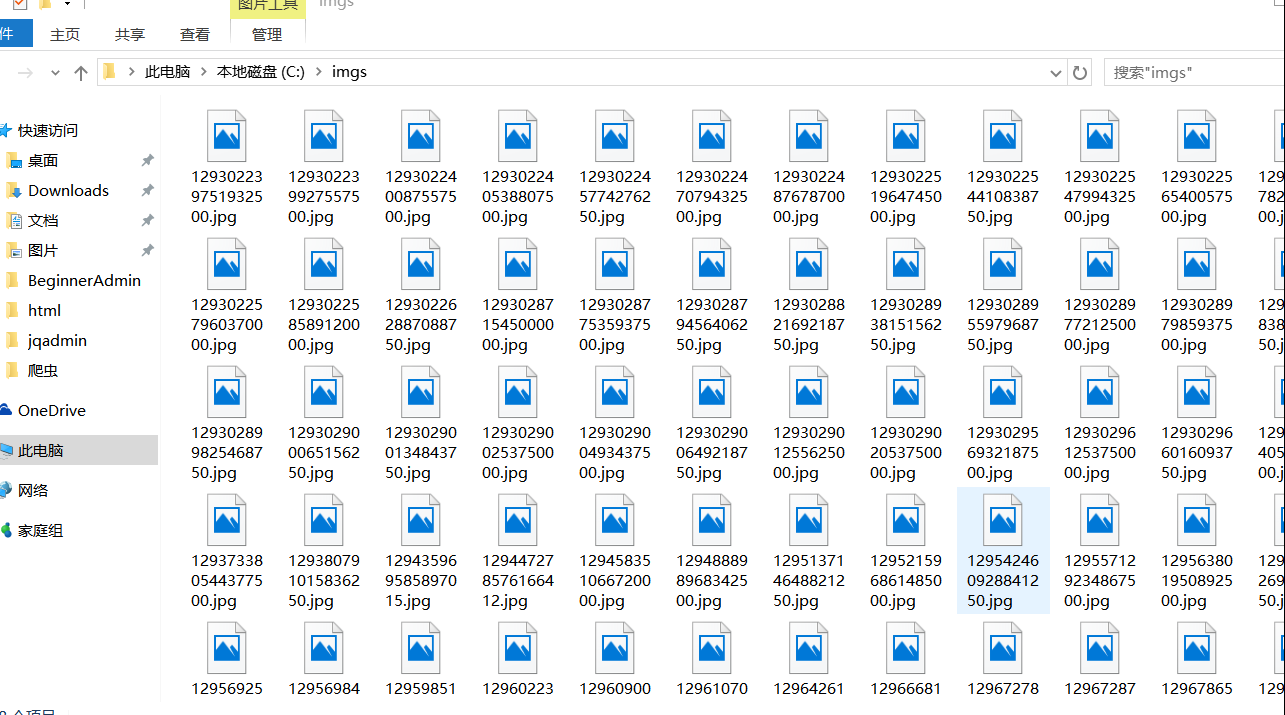
private static final String saveImgPath="C://imgs";
/**
* @Title: insert 品牌名称 和图片爬取和添加
* @Description:
* @param @throws IOException
* @return void
* @throws
* @date 2018年1月29日 下午4:42:57
*/
@RequestMapping("add")
public void insert() throws IOException {
//定义想要爬取数据的地址
String url = "https://car.autohome.com.cn/zhaoche/pinpai/";
//获取网页文本
Document doc = Jsoup.connect(url).get();
//根据类名获取文本内容
Elements elementsByClass = doc.getElementsByClass("uibox-con");
//遍历类的集合
for (Element element : elementsByClass) {
//获取类的子标签数量
int childNodeSize_1 = element.childNodeSize();
//循环获取子标签内的内容
for (int i = 0; i < childNodeSize_1; i++) {
//获取车标图片地址
String tupian = element.child(i).child(0).child(0).child(0).child(0).attr("src");
//获取品牌名称
String pinpai = element.child(i).child(0).child(1).text();
//输出获取内容看是否正确
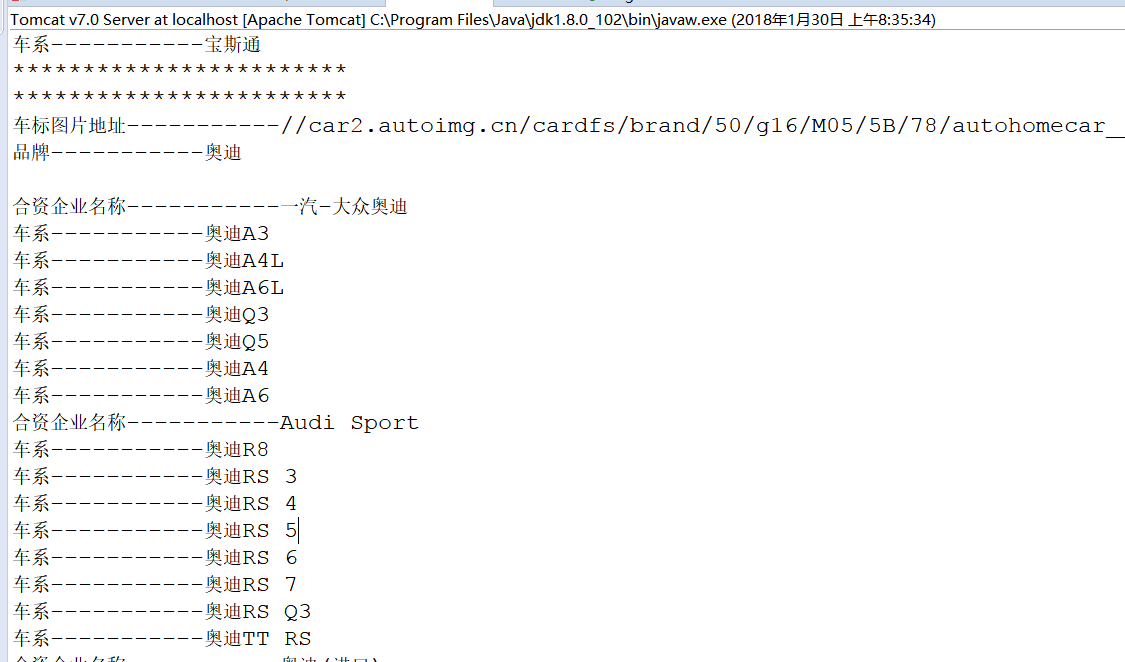
System.out.println("车标图片地址-----------" + tupian);
System.out.println("品牌-----------" + pinpai);
System.out.println();
//把车标图片保存到本地
String tupian_1 = "http:"+tupian;
//连接url
URL url1 = new URL(tupian_1);
URLConnection uri=url1.openConnection();
//获取数据流
InputStream is=uri.getInputStream();
//获取后缀名
String imageName = tupian.substring(tupian.lastIndexOf("/") + 1,tupian.length());
//写入数据流
OutputStream os = new FileOutputStream(new File(saveImgPath, imageName));
byte[] buf = new byte[1024];
int p=0;
while((p=is.read(buf))!=-1){
os.write(buf, 0, p);
}
/**
* 因为每个品牌下有多个合资工厂
* 比如一汽大众和上海大众还有进口大众
* 所有需要循环获取合资工厂名称和旗下
* 车系
*/ //获取车系数量
int childNodeSize_2 = element.child(i).child(1).child(0).childNodeSize();
/**
* 获取标签下子标签数量
* 如果等于1则没有其他合资工厂
*/
int childNodeSize_3 = element.child(i).child(1).childNodeSize();
if(childNodeSize_3==1){
//循环获取车系信息
for (int j = 0; j < childNodeSize_2; j++) {
String chexi = element.child(i).child(1).child(0).child(j).child(0).child(0).text();
System.out.println("车系-----------" + chexi);
}
}else{
/**
* 如果childNodeSize_3大于1
* 则有多个合资工厂
*/
//分别获取各个合资工厂旗下车系
for (int j = 0; j < childNodeSize_3; j++) { int childNodeSize_4 = element.child(i).child(1).child(j).childNodeSize();
/**
* 如果j是单数则是合资工厂名称
* 否则是车系信息
*/
int k = j%2; if(k==0){
//获取合资工厂信息
String hezipinpai = element.child(i).child(1).child(j).child(0).text();
System.out.println("合资企业名称-----------" + hezipinpai);
}else{
//int childNodeSize_5 = element.child(i).child(1).child(0).childNodeSize();
//循环获取合资工厂车系信息
for(int l = 0; l < childNodeSize_4; l++){
String chexi = element.child(i).child(1).child(j).child(l).child(0).child(0).text();
System.out.println("车系-----------" + chexi);
}
}
} } System.out.println("************************");
System.out.println("************************"); }
}
} }
3.运行结果

4.
jsoup爬取图片到本地的更多相关文章
- Java jsoup爬取图片
jsoup爬取百度瀑布流图片 是的,Java也可以做网络爬虫,不仅可以爬静态网页的图片,也可以爬动态网页的图片,比如采用Ajax技术进行异步加载的百度瀑布流. 以前有写过用Java进行百度图片的抓取, ...
- python实现scrapy爬取图片到本地时的sha1摘要算法文件名
2017-03-29 Scrapy爬图片到本地应该会给图片自动生成sha1摘要算法文件名,我第一次用scrapy也不清楚太多,就在程序里自己写了一段实现这一功能的代码.需import hashlib ...
- PHP 爬取图片 保存本地
public function getImage($url,$filename='') { if($url == ''){ return false; } if($filename == ''){ $ ...
- scrapy爬虫系列之三--爬取图片保存到本地
功能点:如何爬取图片,并保存到本地 爬取网站:斗鱼主播 完整代码:https://files.cnblogs.com/files/bookwed/Douyu.zip 主要代码: douyu.py im ...
- 使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地 上 篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy 目标: 爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地 好了不多说,让我们实 ...
- python +requests 爬虫-爬取图片并进行下载到本地
因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地 爬虫实现方式: 1.首先选取你需要的抓取的URL:2.将这些URL放入待抓 ...
- Jsoup爬取带登录验证码的网站
今天学完爬虫之后想的爬一下我们学校的教务系统,可是发现登录的时候有验证码.因此研究了Jsoup爬取带验证码的网站: 大体的思路是:(需要注意的是__VIEWSTATE一直变化,所以我们每个页面都需要重 ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- 孤荷凌寒自学python第八十二天学习爬取图片2
孤荷凌寒自学python第八十二天学习爬取图片2 (完整学习过程屏幕记录视频地址在文末) 今天在昨天基本尝试成功的基础上,继续完善了文字和图片的同时爬取并存放在word文档中. 一.我准备爬取一个有文 ...
随机推荐
- DBA 优化法则
硬件资源是根本,DBA是为了充分利用硬件资源:(更新中--) 统一SQL语句: 减少SQL嵌套: 执行计划返回结果集(决定计划走向): 合理使用临时表: tempdb分多文件: OLTP 条件使用变量 ...
- Tempdb总结
Tempdb 系统数据库是一个全局资源,可供连接到 SQL Server 实例的所有用户使用,并可用于保存下列各项: 显式创建的临时用户对象,例如全局或局部临时表.临时存储过程.表变量或游标. SQL ...
- Linux下查找文件的方法
在Linux环境下查找一个文件的方法:find 路径 -name 'filename',filename不清楚全名的话可以用*号进行匹配,如“tomcat.*”.如果不清楚路径的话可以用"/ ...
- JS中date日期初始化的5种方法
创建一个日期对象: 代码如下: var objDate=new Date([arguments list]); 参数形式有以下5种: 1)new Date("month dd,yyyy hh ...
- ul li自适应居中导航
<BODY> <div class="box"> <ul class="nav"> <li>邮箱管理</l ...
- 多行文字水平垂直居中在div
<BODY> <div class="box"> <h3>1.单行文字居中</h3> <!--设置行高来实现- ...
- sublime自动保存(失去焦点自动保存)
sublime是轻量的编辑器,经常用sublime编辑器来做一些小例子,使用起来很方便. 在使用sublime的时候需要不断的 ctrl + s 保存代码,才能看到效果. 这样的操作很繁琐,保存的多了 ...
- 什么是BIG?如何买BIG?
谈到BIG,就要谈到BIG ONE.BigONE号称"全民交易所",也称"云币国际站".是 INBlockchian(硬币资本)旗下全球区块链资产现货交易所,是 ...
- 前端学习:html基础学习四
7.HTML表格(主要内容<table><caption><tr><th><td>标记) <table>标记 基本格式 < ...
- 七牛php-sdk使用-在线打包
如果需要将空间中的多个文件,打包成一个压缩文件,该怎么做,不需要自己本地打包好再上传,七牛已经为我们提供了这项服务. 命令:mkzip/2/url/xx/alias/xxx; 不仅可以将文件打包,还可 ...