jsoup爬取图片到本地
因为项目需求,需要车辆品牌信息和车系信息,昨天用一天时间研究了jsoup爬取网站信息。项目是用maven+spring+springmvc+mybatis写的。
jsoup开发指南地址:http://www.open-open.com/jsoup/
这个是需要爬取网站的地址 https://car.autohome.com.cn/zhaoche/pinpai/
1.首先在pom.xml中添加依赖
因为需要把图片保存到本地所以又添加了commons-net包
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-net/commons-net -->
<dependency>
<groupId>commons-net</groupId>
<artifactId>commons-net</artifactId>
<version>3.3</version>
</dependency>
2.然后是爬虫代码的实现
@Controller
@RequestMapping("/car/")
public class CarController {
//图片保存路径
private static final String saveImgPath="C://imgs";
/**
* @Title: insert 品牌名称 和图片爬取和添加
* @Description:
* @param @throws IOException
* @return void
* @throws
* @date 2018年1月29日 下午4:42:57
*/
@RequestMapping("add")
public void insert() throws IOException {
//定义想要爬取数据的地址
String url = "https://car.autohome.com.cn/zhaoche/pinpai/";
//获取网页文本
Document doc = Jsoup.connect(url).get();
//根据类名获取文本内容
Elements elementsByClass = doc.getElementsByClass("uibox-con");
//遍历类的集合
for (Element element : elementsByClass) {
//获取类的子标签数量
int childNodeSize_1 = element.childNodeSize();
//循环获取子标签内的内容
for (int i = 0; i < childNodeSize_1; i++) {
//获取车标图片地址
String tupian = element.child(i).child(0).child(0).child(0).child(0).attr("src");
//获取品牌名称
String pinpai = element.child(i).child(0).child(1).text();
//输出获取内容看是否正确
System.out.println("车标图片地址-----------" + tupian);
System.out.println("品牌-----------" + pinpai);
System.out.println();
//把车标图片保存到本地
String tupian_1 = "http:"+tupian;
//连接url
URL url1 = new URL(tupian_1);
URLConnection uri=url1.openConnection();
//获取数据流
InputStream is=uri.getInputStream();
//获取后缀名
String imageName = tupian.substring(tupian.lastIndexOf("/") + 1,tupian.length());
//写入数据流
OutputStream os = new FileOutputStream(new File(saveImgPath, imageName));
byte[] buf = new byte[1024];
int p=0;
while((p=is.read(buf))!=-1){
os.write(buf, 0, p);
}
/**
* 因为每个品牌下有多个合资工厂
* 比如一汽大众和上海大众还有进口大众
* 所有需要循环获取合资工厂名称和旗下
* 车系
*/ //获取车系数量
int childNodeSize_2 = element.child(i).child(1).child(0).childNodeSize();
/**
* 获取标签下子标签数量
* 如果等于1则没有其他合资工厂
*/
int childNodeSize_3 = element.child(i).child(1).childNodeSize();
if(childNodeSize_3==1){
//循环获取车系信息
for (int j = 0; j < childNodeSize_2; j++) {
String chexi = element.child(i).child(1).child(0).child(j).child(0).child(0).text();
System.out.println("车系-----------" + chexi);
}
}else{
/**
* 如果childNodeSize_3大于1
* 则有多个合资工厂
*/
//分别获取各个合资工厂旗下车系
for (int j = 0; j < childNodeSize_3; j++) { int childNodeSize_4 = element.child(i).child(1).child(j).childNodeSize();
/**
* 如果j是单数则是合资工厂名称
* 否则是车系信息
*/
int k = j%2; if(k==0){
//获取合资工厂信息
String hezipinpai = element.child(i).child(1).child(j).child(0).text();
System.out.println("合资企业名称-----------" + hezipinpai);
}else{
//int childNodeSize_5 = element.child(i).child(1).child(0).childNodeSize();
//循环获取合资工厂车系信息
for(int l = 0; l < childNodeSize_4; l++){
String chexi = element.child(i).child(1).child(j).child(l).child(0).child(0).text();
System.out.println("车系-----------" + chexi);
}
}
} } System.out.println("************************");
System.out.println("************************"); }
}
} }
3.运行结果
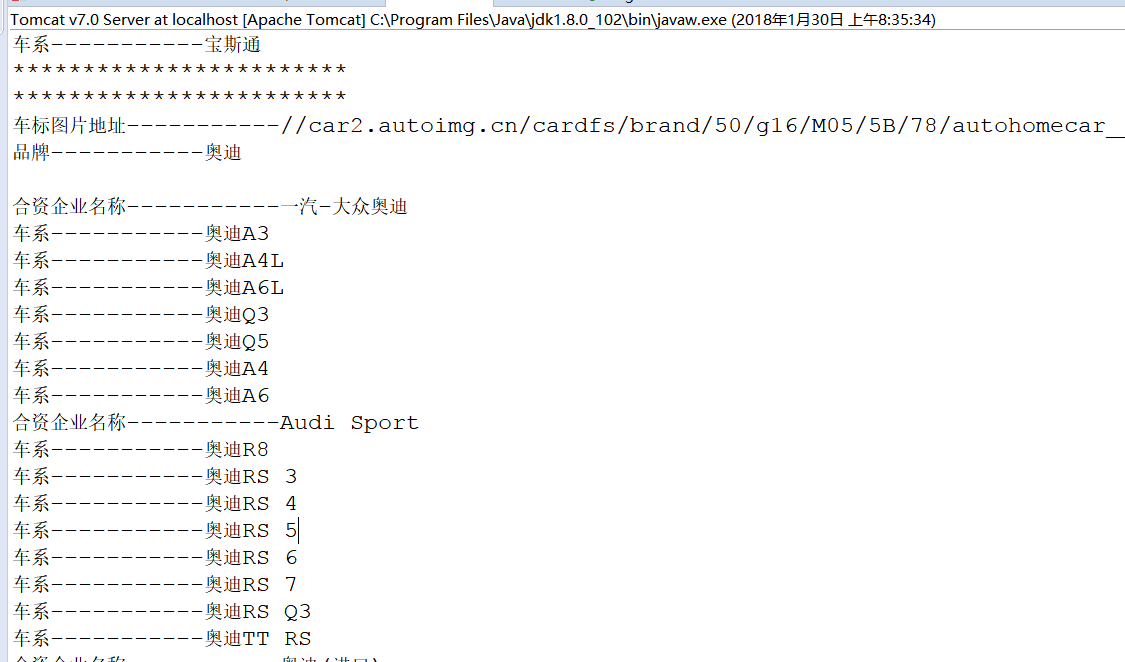

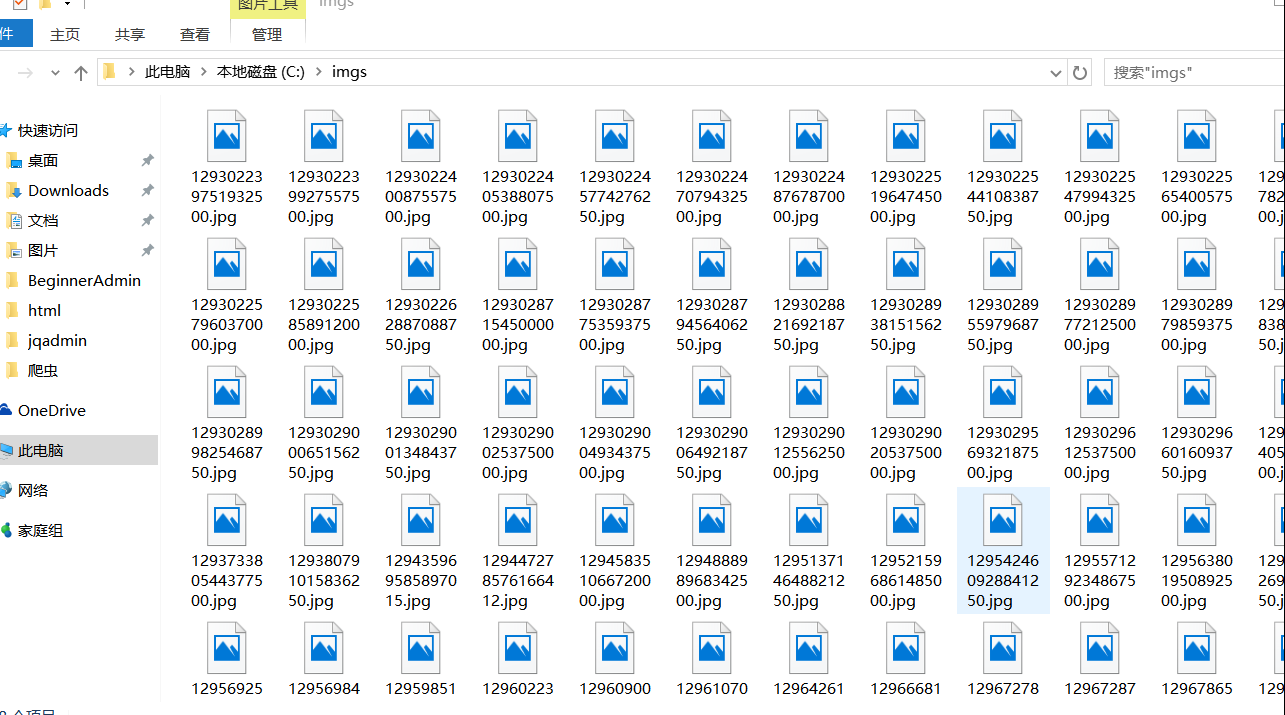
4.
jsoup爬取图片到本地的更多相关文章
- Java jsoup爬取图片
jsoup爬取百度瀑布流图片 是的,Java也可以做网络爬虫,不仅可以爬静态网页的图片,也可以爬动态网页的图片,比如采用Ajax技术进行异步加载的百度瀑布流. 以前有写过用Java进行百度图片的抓取, ...
- python实现scrapy爬取图片到本地时的sha1摘要算法文件名
2017-03-29 Scrapy爬图片到本地应该会给图片自动生成sha1摘要算法文件名,我第一次用scrapy也不清楚太多,就在程序里自己写了一段实现这一功能的代码.需import hashlib ...
- PHP 爬取图片 保存本地
public function getImage($url,$filename='') { if($url == ''){ return false; } if($filename == ''){ $ ...
- scrapy爬虫系列之三--爬取图片保存到本地
功能点:如何爬取图片,并保存到本地 爬取网站:斗鱼主播 完整代码:https://files.cnblogs.com/files/bookwed/Douyu.zip 主要代码: douyu.py im ...
- 使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地 上 篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy 目标: 爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地 好了不多说,让我们实 ...
- python +requests 爬虫-爬取图片并进行下载到本地
因为写12306抢票脚本需要用到爬虫技术下载验证码并进行定位点击所以这章主要讲解,爬虫,从网页上爬取图片并进行下载到本地 爬虫实现方式: 1.首先选取你需要的抓取的URL:2.将这些URL放入待抓 ...
- Jsoup爬取带登录验证码的网站
今天学完爬虫之后想的爬一下我们学校的教务系统,可是发现登录的时候有验证码.因此研究了Jsoup爬取带验证码的网站: 大体的思路是:(需要注意的是__VIEWSTATE一直变化,所以我们每个页面都需要重 ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- 孤荷凌寒自学python第八十二天学习爬取图片2
孤荷凌寒自学python第八十二天学习爬取图片2 (完整学习过程屏幕记录视频地址在文末) 今天在昨天基本尝试成功的基础上,继续完善了文字和图片的同时爬取并存放在word文档中. 一.我准备爬取一个有文 ...
随机推荐
- 转: 谈JAVA_OPTS环境变量不起作用
谈JAVA_OPTS环境变量不起作用 2016-6-14 11:12 最近在处理运行一个java应用时,老是出现java.lang.OutOfMemoryError: Java heap space. ...
- .NET Core+MySql+Nginx 容器化部署
.NET Core容器化@Docker .NET Core容器化之多容器应用部署@Docker-Compose .NET Core+MySql+Nginx 容器化部署 GitHub-Demo:Dock ...
- android开发遇到的问题
1.虚拟机运行出下面的错Failed to allocate memory: 8 Failed to allocate memory: 8This application has requested ...
- docker:(5)利用docker -v 和 Publish over SSH插件实现war包自动部署到docker
在 docker:(3)docker容器挂载宿主主机目录 中介绍了运行docker时的一个重要命令 -v sudo docker run -p : --name tomcat_xiao_volume ...
- Mac appium apk覆盖性安装的问题
/Applications/Appium.app/Contents/Resources/node_modules/appium/node_modules/appium-android-driver/n ...
- 阿里mysql同步工具otter的docker镜像
https://github.com/dearplain/otter_manager https://github.com/dearplain/otter_node 本人开发的小巧docker镜像,根 ...
- 虚拟机迁移(QEMU动态迁移,Libvirt动(静)态迁移)
动静态迁移的原理 静态迁移是指在虚拟机关闭或暂停的情况下,将源宿主机上虚拟机的磁盘文件和配置文件拷贝到目标宿主机上.这种方式需要显式的停止虚拟机运行,对服务可用性要求高的需求不合适. *** 动态迁移 ...
- python实现单例模式
有这么一种场景,我们把数据封装到类体或类的某个方法里,然而我们new出这个类只是为了拿到这部分数据,那么当多次这样调用的时候,每次都来拿数据并放到内存中大大浪费了内存. 那我们就可以想,我们拿到一次数 ...
- 【Java】Java中BigDecimal的基本运算
BigDecimal一共有4个够造方法,让来看看其中比较常用的两种用法: 第一种:BigDecimal(double val)Translates a double into a BigDecimal ...
- 七牛php-sdk使用-在线打包
如果需要将空间中的多个文件,打包成一个压缩文件,该怎么做,不需要自己本地打包好再上传,七牛已经为我们提供了这项服务. 命令:mkzip/2/url/xx/alias/xxx; 不仅可以将文件打包,还可 ...