myeclipse连接hadoop集群编程及问题解决
原以为搭建一个本地编程测试hadoop程序的环境很简单,没想到还是做得焦头烂额,在此分享步骤和遇到的问题,希望大家顺利.
一.要实现连接hadoop集群并能够编码的目的需要做如下准备:
1.远程hadoop集群(我的master地址为192.168.85.2)
2.本地myeclipse及myeclipse连接hadoop的插件
3.本地hadoop(我用的是hadoop-2.7.2)
先下载插件hadoop-eclipse-plugin,我用的是hadoop-eclipse-plugin-2.6.0.jar,下载之后放在"MyEclipse Professional 2014\dropins"目录下,重启myeclipse会在perspective和views发现一个map/reduce的选项


切换到hadoop试图,然后打开MapReduce Tools
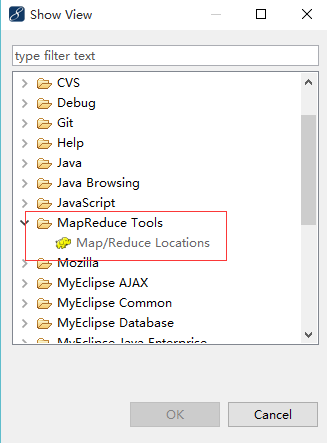
二.接下来新增hadoop服务,要开始配置连接,需要查看hadoop配置
1.hadoop/etc/hadoop/mapred-site.xml配置,查看mapred.job.tracker里面的ip和port,用以配置Map/Reduce Master
2.hadoop/etc/hadoop/core-site.xml配置,查看fs.default.name里面的ip和port,用以配置DFS Master
3.用户名直接写hadoop操作用户即可
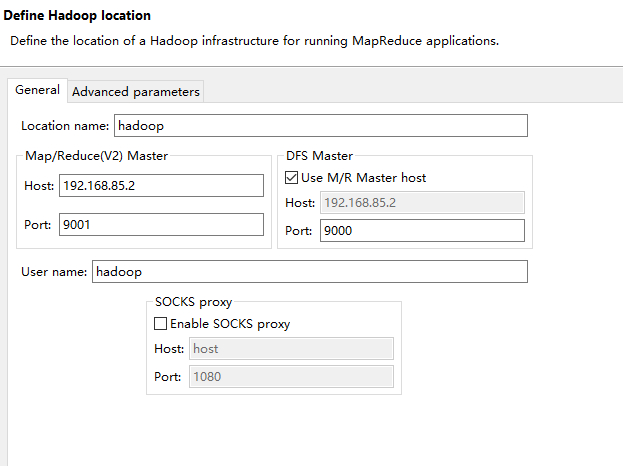
到此配置就完成了,顺利的话可以看到:
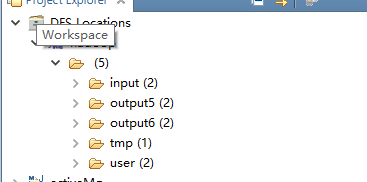
新建hadoop工程.
File】->【New】->【Project...】->【Map/Reduce】->【Map/Reduce Project】->【Project name: WordCount】->【Configure Hadoop install directory...】->【Hadoop installation directory: D:\nlsoftware\hadoop\hadoop-2.7.2】->【Apply】->【OK】->【Next】->【Allow output folders for source folders】->【Finish】
工程下建立三个类,分别是Mapper,Reduce,和main
TestMapper
package bb; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context; public class TestMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
TestReducer
package bb; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context; public class TestReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
WordCount
package bb; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TestMapper.class); job.setCombinerClass(TestReducer.class); job.setReducerClass(TestReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
我在hdfs的input里面新建了两个tex文件,这时候可以用来测试,也可以用其他的文件测试.所以我的参数如图:
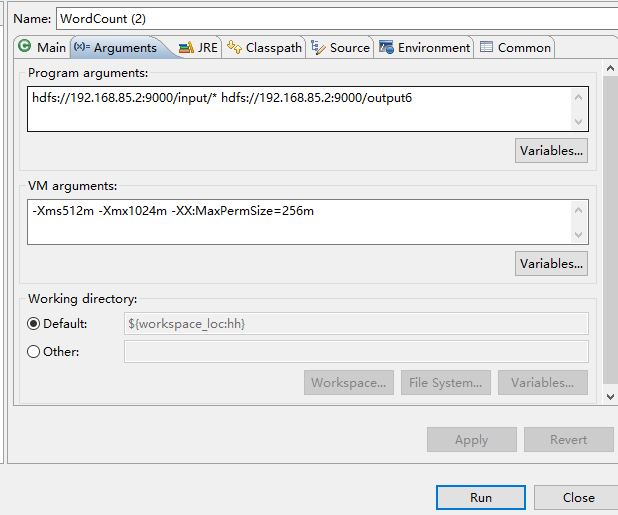
hdfs://192.168.85.2:9000/input/* hdfs://192.168.85.2:9000/output6
-Xms512m -Xmx1024m -XX:MaxPermSize=256m
稍作解释,参入的两个参数,一个是输入文件,一个是输出结果文件.指定正确目录即可. output6文件夹的名字是我随便写的.会自动创建
那么到了最后也是最关键的一步.我run as hadoop时遇到了
Server IPC version 9 cannot communicate with client version 4
报错.这是提示版本不对,我一看.远程hadoop版本与jar包版本不同导致的.远程是2.7.2的.所以我把hadoop相关jar包改为该版本即可(2.*版本的应该都可以,没有的话相近的也可以用)
然后错误换了一个
Exception in thread "main" ExitCodeException exitCode=-1073741515:
经过查阅资料发现这是因为window本地的hadoop没有winutils.exe导致的.原来本地hadoop的机理要去调用这个程序.我们先要去下载2.7的winutils.exe然后使得其运行没错才可以.
下载之后发现需要hadoop.dll文件.晕.再次下载并放在c:\windows\System32目录下.
然而我的winutils.exe还是无法启动,这个虽然是我的电脑问题.但是想来有些人还是会遇到(简单说一下).
报错缺少msvcr120.dll.下载之后再去启动提示,"应用程序无法正常启动0xc000007b".
这是内存错误引起的.下载DirectX_Repair修复directx终于解决了问题,最后成功启动了hadoop程序.
有同学可能能够启动winutils.exe但还是不能正常跑应用程序,依然报错,可以尝试修改权限验证.
修改hadoop/etc/hadoop/hdfs-site.xml
添加内容
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
取消权限验证.
myeclipse连接hadoop集群编程及问题解决的更多相关文章
- Eclipse/MyEclipse连接Hadoop集群出现:Unable to ... ... org.apache.hadoop.security.AccessControlExceptiom:Permission denied问题
问题详细如下: 解决办法: <property> <name>dfs.premissions</name> <value>false</value ...
- windows下eclipse远程连接hadoop集群开发mapreduce
转载请注明出处,谢谢 2017-10-22 17:14:09 之前都是用python开发maprduce程序的,今天试了在windows下通过eclipse java开发,在开发前先搭建开发环境.在 ...
- 【hadoop】——window下elicpse连接hadoop集群基础超详细版
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
- Eclipse连接Hadoop集群及WordCount实践
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.环境准备 1.JDK安装与配置 2.Eclipse下载 下载解压即可,下载地址:https://pan.baidu.com/s/1i51UsVN ...
- windows下在eclipse上远程连接hadoop集群调试mapreduce错误记录
第一次跑mapreduce,记录遇到的几个问题,hadoop集群是CDH版本的,但我windows本地的jar包是直接用hadoop2.6.0的版本,并没有特意找CDH版本的 1.Exception ...
- eclipse 连接 hadoop集群
1 网上找插件 或者 自己编译 放到eclipse plugin里面 2 重启eclipse 配置MapReduceLocation 通吃端口为9001 9000 看你自己的配置 3 新建mapRed ...
- CentOS7 安装Hadoop集群环境
先按照上一篇安装与配置好CentOS以及zookeeper http://www.cnblogs.com/dopeter/p/4609276.html 本章介绍在CentOS搭建Hadoop集群环境 ...
- eclipse链接Hadoop集群时报错Error:Call From xxx/xxx.xxx.xxx.xxx to hostname1:9000 failed on connection exception
今天用eclipse连接Hadoop集群的时候突然给我报了这样一个错误:Error:Call From xxx/xxx.xxx.xxx.xxx to hostname1:9000 failed on ...
- eclipse连接远程hadoop集群开发时权限不足问题解决方案
转自:http://blog.csdn.net/shan9liang/article/details/9734693 eclipse连接远程hadoop集群开发时报错 Exception in t ...
随机推荐
- c语言-键盘扫描码
定义: 键盘上的每一个键都有两个唯一的数值进行标志.为什么要用两个数值而不是一个数值呢?这是因为一个键可以被按下,也可以被释放.当一个键按下时,它们产生一个唯一的数值,当一个键被释放时,它也会产生一个 ...
- 用jQuery写的最简单的表单验证
近几天完成了关于我们项目的最简单的表单验证,是用jQuery写的,由于之前也一直没学过jQuery,所以自己也是一直处于边摸索边学习的阶段,经过这一段时间的学习,通过查资料啥的,也发现了学习jQuer ...
- hdu_5795_A Simple Nim(打表找规律的博弈)
题目链接:hdu_5795_A Simple Nim 题意: 有N堆石子,你可以取每堆的1-m个,也可以将这堆石子分成3堆,问你先手输还是赢 题解: 打表找规律可得: sg[0]=0 当x=8k+7时 ...
- Git合并分支出现的冲突解决
人生不如意之事十有八九,合并分支往往也不是一帆风顺的. 我们准备新的分支newbranch. LV@LV-PC MINGW32 /c/gitskill (master)$ git checkout - ...
- 谈CSS模块化【封装-继承-多态】
第一次听到“CSS模块化”这个词是在WebReBuild的第四届“重构人生”年会上,当时我还想,“哈,CSS也有模块化,我没听错吧?”事实上,我没听错,你也没看错,早就有CSS模块化这个概念了.之所以 ...
- javascript模糊查询一个数组
/* * 模糊查询一个数组 */ com.ty.repairtech.JsonOperation.searchList = function(str, container) { var newList ...
- Activity竟然有两个onCreate方法,可别用错了
public class HomeDetailActivity { @Override protected void onCreate(@Nullable Bundle savedInstanceSt ...
- think in uml 2.1
业务建模
- Enum 枚举基础
1 定义一个枚举 enum Weekend { Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday } 2 得到每个枚举值 f ...
- Object-C 自学笔记 - 1
1.基本变量类型 类型 标示符 输出格式 整形 int %i 浮点 float %f 双精度 double %g 单字符 char %c 以上是基本类型,除此之外还有long, long long i ...