大数据学习(05)——MapReduce/Yarn架构
Hadoop1.x中的MapReduce
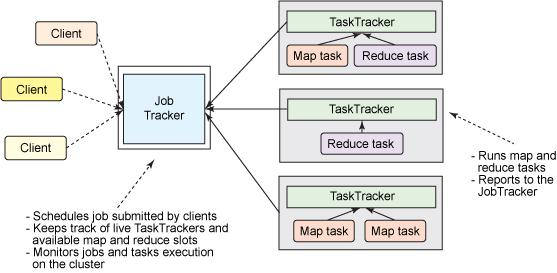
MapReduce作为Hadoop最核心的两个组件之一,在1.0版本中就已经存在了。它包含这么几个角色:
- Client
- 多数情况下Client的作用就是向服务端发送请求并返回结果。但是在MapReduce里,Client的作用可不小。
- Client根据传入的数据参数,向HDFS的NameNode获取元数据信息,计算出Map任务的split切片信息。split跟Block有映射关系,Client可以计算出split在文件中的偏移量,再根据计算向数据移动的原则,建议JobTracker将计算程序移动到哪些主机节点。
- Client生成计算程序的配置文件。
- Client将程序jar包、split清单、xml配置文件上传到HDFS的目录中(10副本,避免多个Map任务读取程序文件造成瓶颈)。
- Client调用JobTracker启动计算程序,告知计算需要的文件放在哪里。
- JobTracker
- 主从架构中的主节点,像HDFS中的NameNode。它有两个作用:资源管理和任务调度。
- 从HDFS获取split清单。
- JobTracker收到TaskTracker心跳时,记录下TaskTracker当前的资源情况,为任务调度做准备。
- 按照计算向数据移动的原则,根据资源使用情况为任务分配离数据最近的TaskTracker。
- TaskTracker
- 主从架构中的从节点,像HDFS中的DataNode,相同的架构会出现在大数据技术的多个地方。
- 为尽量实现本地计算而不需要网络传输,通常TaskTracker和HDFS的DataNode在相同主机上。
- 与JobTracker的每次心跳时,汇报自身的资源状况。
- 心跳时从JobTracker获取MapReduce任务。
- 从HDFS下载计算程序相关的文件,启动MapTask/ReduceTask。
在上面的架构中,JobTracker要为所有的计算任务做调度,而且全局只有一个进程不利于水平扩展。这个架构最大的缺点是单点故障风险,另外资源和调度耦合太高,资源管理难以扩展到其他计算框架。为了解决上述问题,在Hadoop2.x中,MapReduce的资源管理被切割出来,成为一个独立的资源管理模块Yarn。
MapReduce on Yarn
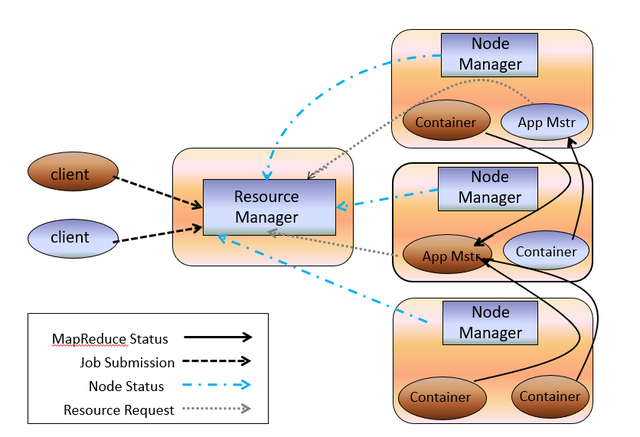
为了解决MapReduce1.x中存在的问题,Hadoop2.x中增加了Yarn模块,专门用来做资源管理。
Yarn包含角色:
- Resource Manager
- 负责整体资源的管理
- 在客户端发起计算任务时,选择空闲资源多的节点,通知Node Manager启动Container
- Node Manager
- 与Resource Manager心跳时,报告自身主机节点的资源情况
- 接收Resource Manager的指令,启动Container
- ApplicationMaster
- 相当于JobTracker不带资源管理功能,只负责任务调度
- Container
- 可用资源的集合,执行具体的计算任务
- 反射生成计算任务的实例
MapReduce包含角色:
- MRClient
- 将split切片清单、xml配置、程序jar上传到HDFS
- 向Resource Manager发请求,申请创建AppMaster
- MRAppMaster
- 在Container中反射生成MRAppMaster
- 从HDFS下载split切片清单
- 向Resource Manager申请执行计算任务的资源
- 向Name Manager分配的Container中调度计算任务并监控其运行状态
- Task
- Container反射生成计算任务的实例,执行Map/Reduce计算任务
新架构解决了MapReduce1.x中的痛点。它的任务调度进程MRAppMaster是每个客户端作业对应一个,单点故障不再是全局性的,并且MRAppMaster和Container都有失败重试的功能,分别由ResourceManager和MRAppMaster来完成重试的动作。任务调度压力也分散到不同的进程里。不同的计算框架可以共用Yarn的资源管理功能。
Yarn本身也是高可用架构,通过Zookeeper选主,架构如下图
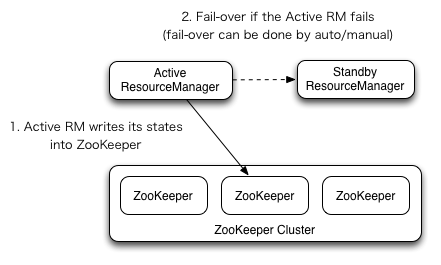
这个架构图是不是跟HDFS里的NameNode高可用非常像?可以看到主备高可用的方案都是相似的,可以说是形成了一种设计模式。
这个图比NameNode少了ZKFS这个角色,不是说它不需要了,而是它更方便地集成到ResourceManager中去了。
大数据学习(05)——MapReduce/Yarn架构的更多相关文章
- 大数据学习笔记1-大数据处理架构Hadoop
Hadoop:一个开源的.可运行于大规模集群上的分布式计算平台.实现了MapReduce计算模型和分布式文件系统HDFS等功能,方便用户轻松编写分布式并行程序. Hadoop生态系统: HDFS:Ha ...
- 大数据学习--day16(集合总体架构--ArrayList--LinkedList)
集合总体架构--ArrayList--LinkedList Collection接口的实现类用法上都有相似的方法.Map同理. List: 特性 : 1. 有索引 2. 有序 ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
随机推荐
- [Azure DevOps] 如何使用任务组
1. 使用 PowerShell 脚本 在上一篇文章中我们学会了怎么使用扩展在编译前实时更改版本号.有些情况下我们希望不适用扩展,例如喜欢发明轮子,或者根本没有安装扩展的权限.这时候我们可以自己写 P ...
- C#《大话设计模式》之原型模式学习日记
class Program { static void Main(string[] args) { Resume a = new Resume("大鸟"); a.SetPerson ...
- Jenkins之搭建部署
一.部署环境 操作系统:Centos7 软件: apache-tomcat-9.0.48--地址:https://tomcat.apache.org/download-90.cgi jdk-8u291 ...
- 《计算机组成与体系结构:性能设计》读后小记 12、CPU的结构和功能
一.CPU组成 1.组成: ALU:算术逻辑单元,完成数据的实际计算或处理 控制器:控制数据的移入移出CPU 寄存器:由一组存储位置极小的内部存储器组成 CPU内部总线:在各寄存器和ALU之间传送数据 ...
- redis广播/订阅模式演示
参考博客 http://www.pianshen.com/article/7183315879/ 1.首先在本地启动redis服务 2.启动4个客户端 redis-cli 3.将其中三个客户端设置监听 ...
- java.io.CharConversionException: Not an ISO 8859-1 character: [留]
笔记一下 问题代码如下: response.setContentType("text/html;charset=utf-8");ServletOutputStream out = ...
- 输出 time 命令的结果到文件中
译至:http://unicus.jp/skmk/archives/338 由于输出 time 命令的结果到文件时使用的错误的方式,所以将其记录下来. 环境是bash. 目标 将运行的a.out程序的 ...
- Adaptive AUTOSAR 学习笔记 4 - 架构
本系列学习笔记基于 AUTOSAR Adaptive Platform 官方文档 R20-11 版本 AUTOSAR_EXP_PlatformDesign.pdf 缩写 AP:AUTOSAR Adap ...
- yoyogo v1.7.5 发布, 独立依赖注入DI
YoyoGo v1.7.5 YoyoGo (Go语言框架) 一个简单.轻量.快速.基于依赖注入的微服务框架( web .grpc ),支持Nacos/Consoul/Etcd/Eureka/k8s / ...
- 腾讯云短信详细教程(C#,WinForm)
1.申请一个微信公众号(申请公众号是准备工作的第一步,必须先完成)(那为什么要用公众号呢?是因为这个条件对于学生党来说比较简单实现,不需要本人有上市的APP或是网站等) 2.百度搜索"腾讯云 ...