<数据结构>hash进阶
hash函数构建
采取26进制
对于字符串str,令**H[i] = H[i-1]*26 + index(str[i]) **,最后H[i-1]就是str的hash值
问题:hash值过大,无法表式
取模
在上述基础上取模:H[i] = (H[i-1]*26 + index(str[i]))%mod
问题:丧失了一定的唯一性
权衡:一个冲突概率极小的hash函数
H[i] = (H[i-1]*p + index(str[i]))%mod
其中p=107 数量级的素数(10000019),mod=109 数量级的素数(1000000007)
例1:判断不同的字符串个数
问题描述
给出N个只有小写字母的字符串,判断其中不同的字符串的个数
代码实现
#include<iostream>
#include<string>
#include<vector>
#include<algorithm>
using namespace std;
const int MOD = 1000000007;
const int P = 10000019;
vector<int> ans;
//字符串hash
long long hashFunc(string str){
long long H = 0;
for(int i = 0; i < str.length(); i++){
H = (H*P + str[i] - 'a') % MOD;
}
return H;
}
int main(){
string str;
while(getline(cin, str), str != "#"){
long long id = hashFunc(str);
ans.push_back(id);
}
sort(ans.begin(), ans.end());
int count = 0;
for(int i = 0; i < ans.size(); i++){
if(i == 0 || ans[i] != ans[i-1])
count++;
}
cout<< count << endl;
return 0;
}
例2: 最长公共子串
前置:求解子串str[i…j]的hash值H[i…j]
符号含义:
- H[i..j] : str[i]~str[j]这一子串对应的hash值,即该子串对应的p进制数
- H[i] : H[0…i]
H[i…j] = index(str[i]) * pj-i + index(str[i-1]) * pj-i-1 + … + index(str[j]) * p0
H[i] = H[i-1] * p + index(str[i])
于是 :
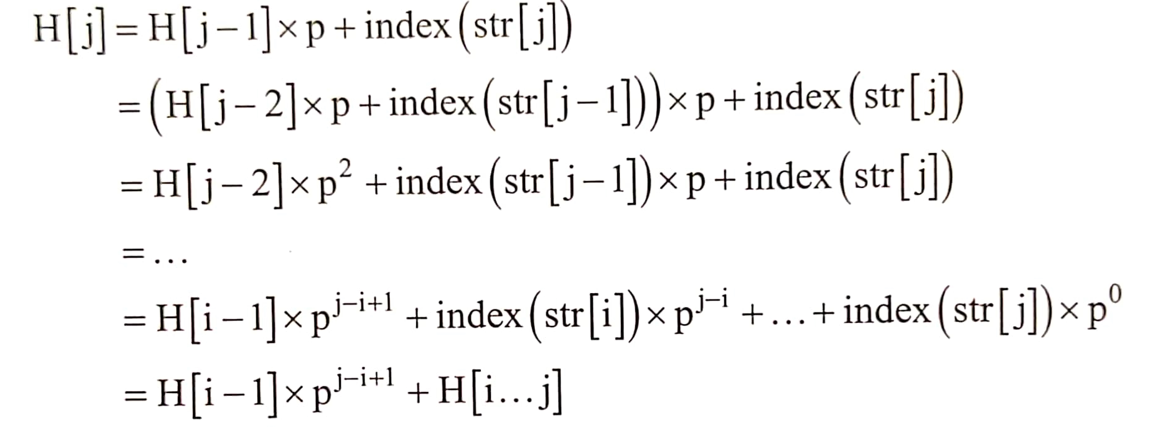
所以:
H[i…j] = H[j] - H[i - 1] * pj-i+1求完str的H数组后,直接调取下标j 和 i-1 即可求得
取模:
H[i…j] = (H[j] - H[i - 1] * pj-i+1)%mod
非负处理:(括号内可能为负值)加模再取模
H[i…j] = ((H[j] - H[i - 1] * pj-i+1)%mod + mod)%mod
步骤
- 计算H[]数组
- 求出两个字符串所有子串的hash值以及对应的长度
- 子串两两比较,得出长度最大值
代码
#include<iostream>
#include<cstdio>
#include<string>
#include<vector>
#include<map>
#include<algorithm>
using namespace std;
typedef long long LL;
const LL MOD = 1000000007;
const LL P = 10000019;
const int MAXN = 1010; //MAXN为字符串的最大长度
//powP[i]存放p^i%MOD, H1,H2分别存放str1,str2的hash值
LL powP[MAXN], H1[MAXN] = {0}, H2[MAXN] = {0};
//pr1存放所有<子串hash值,子串长度>, pr2同理
vector<pair<int,int>> pr1,pr2;
//init函数初始化powP
void init(int len){
powP[0] = 1;
for(int i = 1; i <= len; i++){
powP[i] = (powP[i-1]*P)%MOD;
}
}
//calH函数计算字符串str的hash值
void calH(LL H[], string &str){
H[0] = str[0];
for(int i = 1; i < str.length(); i++){
H[i] = (H[i-1]*P + str[i])%MOD;
}
}
//calSingleSubH 计算 H[i...j]
int calSingleSubH(LL H[], int i, int j){
if(i == 0) return H[j];
return ((H[j] - H[i-1] * powP[j - i + 1])%MOD + MOD)%MOD;
}
//calSubH 计算 所有子串的hash值,并将<子串hash值,子串长度>存入pr
void calSubH(LL H[], int len, vector<pair<int,int>> &pr){
for(int i = 0; i < len; i++){
for(int j = i; j < len; j++){
int hashValue = calSingleSubH(H, i, j);
pr.push_back(make_pair(hashValue, j - i + 1));
}
}
}
//计算 pr1 和 pr2中相同的 hash值, 维护最大长度
int getMax(){
int ans = 0;
for(int i = 0; i < pr1.size(); i++){
for(int j = 0; j < pr2.size(); j++){
if(pr1[i].first == pr2[j].first)
ans = max(ans, pr1[i].second);
}
}
return ans;
}
int main(){
string str1, str2;
getline(cin, str1);
getline(cin, str2);
init(max(str1.length(), str2.length())); //初始化powP数组
calH(H1,str1); //分别计算 str1 和 str2 的hash值
calH(H2,str2);
calSubH(H1,str1.length(),pr1); //分别计算所有H1[i...j] 和 H2[i...j]
calSubH(H2,str2.length(),pr2);
printf("ans = %d", getMax()); //输出最大公共子串长度
return 0;
}
<数据结构>hash进阶的更多相关文章
- 《算法竞赛进阶指南》0x10 基本数据结构 Hash
Hash的基本知识 字符串hash算法将字符串看成p进制数字,再将结果mod q例如:abcabcdefg 将字母转换位数字(1231234567)=(1*p9+2*p8+3*p7+1*p6+2*p5 ...
- 数据结构 : Hash Table
http://www.cnblogs.com/lucifer1982/archive/2008/06/18/1224319.html 作者:Angel Lucifer 引子 这篇仍然不讲并行/并发. ...
- php 数据结构 hash表
hash表 定义 hash表定义了一种将字符组成的字符串转换为固定长度(一般是更短长度)的数值或索引值的方法,称为散列法,也叫哈希法.由于通过更短的哈希值比用原始值进行数据库搜索更快,这种方法一般用来 ...
- hash进阶:使用字符串hash乱搞的姿势
前言 此文主要介绍hash的各种乱搞方法,hash入门请参照我之前这篇文章 不好意思hash真的可以为所欲为 在开头先放一下题表(其实就是我题解中的hash题目qwq) 查询子串hash值 必备的入门 ...
- Redis系列(九):数据结构Hash源码解析和HSET、HGET命令
2.源码解析 1.相关命令如下: {"hset",hsetCommand,,"wmF",,NULL,,,,,}, {"hsetnx",hse ...
- 数据结构-Hash表
实现: #ifndef SEPARATE_CHAINING_H #define SEPARATE_CHAINING_H #include <vector> #include <lis ...
- MySQL源码 数据结构hash
MySQL源码自定义了hash表,因为hash表具有O(1)的查询效率,所以,源码中大量使用了hash结构.下面就来看下hash表的定义: [源代码文件include/hash.h mysys/has ...
- 字符串转hash进阶版
#include<bits/stdc++.h> using namespace std; ,mod=; vector<unsigned> H[mod]; void Add(un ...
- Redis系列(九):数据结构Hash之HDEL、HEXISTS、HGETALL、HKEYS、HLEN、HVALS命令
1.HDEL 从 key 指定的哈希集中移除指定的域.在哈希集中不存在的域将被忽略. 如果 key 指定的哈希集不存在,它将被认为是一个空的哈希集,该命令将返回0. 时间复杂度:O(N) N是被删除的 ...
随机推荐
- LeetCode382-链表随机节点
原题链接:[382. 链表随机节点]:https://leetcode-cn.com/problems/linked-list-random-node/ 题目描述: 给定一个单链表,随机选择链表的一个 ...
- 100个Shell脚本——【脚本1】打印形状
[脚本1]打印形状 一.脚本 打印等腰三角形.直角三角形.倒直角三角形.菱形 #!/bin/bash #等腰三角形 read -p "Please input the length:&quo ...
- Linux基础命令---wget下载工具
wget wget是一个免费的文件下载工具,可以从指定的URL下载文件到本地主机.它支持HTTP和FTP协议,经常用来抓取大量的网页文件. 此命令的适用范围:RedHat.RHEL.Ubuntu.Ce ...
- 第7章 使用性能利器——Redis
在现今互联网应用中,NoSQL已经广为应用,在互联网中起到加速系统的作用.有两种NoSQL使用最为广泛,那就是Redis和MongoDB.本章将介绍Redis和Spring Boot的结合.Redis ...
- 11.Vue.js-事件处理器
事件监听可以使用 v-on 指令: <div id="app"> <button v-on:click="counter += 1">增 ...
- 【Git】【Gitee】通过git远程删除仓库文件
安装Git Git安装配置-菜鸟教程 没有安装下载的,请读者自行安装下载. 启动与初步配置 配置用户名与邮箱 git config --global user.name "用户名" ...
- vue在某页面监听键盘输入事件
需求:在某一网页,通过上下左右键控制一些操作 实现: 1.基本代码: 因为没有绑定特定的元素.所以我们将事件绑定到document上. //当前页面监视键盘输入 document.onkeydown ...
- Windows 任务计划部署 .Net 控制台程序
Windows 搜索:任务计划程序 创建任务 添加任务名称 设置触发器:这里设置每10分钟执行一次 保存之后显示 此任务会从每天的 0:10:00 执行第一次后一直循环下去. 在操作选项卡下,选择启动 ...
- LuoguP7222 [RC-04] 信息学竞赛 题解
Content 给定一个角 \(\alpha\),求 \(\beta=90^\circ-\alpha\). 数据范围:\(\alpha\in[-2^{31},2^{31}-1]\). Solution ...
- ORM-数据库命令操作包装实例对象学习
http://www.cnblogs.com/alex3714/articles/5978329.html python 之路,Day11 - sqlalchemy ORM 本节内容 ORM介绍 ...