Python格式处理
一.CVS表格
import csv
villains = [
['Doctor', 'No'],
['Rosa', 'Klebb'],
['Mister', 'Big'],
['Auric', 'Goldfinger'],
['Ernst', 'Blofeld'],
]
with open('villains', 'wt') as fout: # 一个上下文管理器
csvout = csv.writer(fout)
csvout.writerows(villains)
#读取cvs
with open('villains', 'rt') as fin: # 一个上下文管理器
cin = csv.reader(fin)
villains = [row for row in cin] # 使用列表推导式
print(villains)
#读取成字典方式
with open('villains', 'rt') as fin:
cin = csv.DictReader(fin, fieldnames=['first', 'last'])
villains = [row for row in cin]
#将字典写入成标题在上面的方式
villains = [
{'first': 'Doctor', 'last': 'No'},
{'first': 'Rosa', 'last': 'Klebb'},
{'first': 'Mister', 'last': 'Big'},
{'first': 'Auric', 'last': 'Goldfinger'},
{'first': 'Ernst', 'last': 'Blofeld'},
]
with open('villains', 'wt') as fout:
cout = csv.DictWriter(fout, ['first', 'last'])
cout.writeheader()
cout.writerows(villains)
with open('villains', 'rt') as fin: #重头读取文件
cin = csv.DictReader(fin)
villains = [row for row in cin]
二.xml
menu.xml
<?xml version="1.0"?>
<menu>
<breakfast hours="7-11">
<item price="$6.00">breakfast burritos</item>
<item price="$4.00">pancakes</item>
</breakfast>
<lunch hours="11-3">
<item price="$5.00">hamburger</item>
</lunch>
<dinner hours="3-10">
<item price="8.00">spaghetti</item>
</dinner>
</menu>
import xml.etree.ElementTree as et
tree = et.ElementTree(file='menu.xml')
root = tree.getroot()
root.tag
#tag是标签字符串,attrib是属性的一个字典
for child in root:
print('tag:', child.tag, 'attributes:', child.attrib)
for grandchild in child:
print('\ttag:', grandchild.tag, 'attributes:', grandchild.attrib)
len(root) #菜单选择数目
len(roo[0]) #早餐项的数目
三.json
json字符串
menu = \
{
"breakfast": {
"hours": "7-11",
"items": {
"breakfast burritos": "$6.00",
"pancakes": "$4.00"
}
},
"lunch" : {
"hours": "11-3",
"items": {
"hamburger": "$5.00"
}
},
"dinner": {
"hours": "3-10",
"items": {
"spaghetti": "$8.00"
}
}
}
import json
menu_json = json.dumps(menu)
menu_json
menu2 = json.loads(menu_json) #解析成python结构
import datetime
now = datetime.datetime.utcnow()
json.dumps(now) #无法转换,因为标准json没有定义日期
#转换
now_str = str(now)
json.dumps(now_str) #可以转换了
from time import mktime
now_epoch = int(mktime(now.timetuple()))
json.dumps(now_epoch) #可以转换epoch值
class DTEncoder(json.JSONEncoder): #继承重载default方法
def default(self, obj):
# isinstance()检查obj的类型
if isinstance(obj, datetime.datetime):
return int(mktime(obj.timetuple()))
# 否则是普通解码器知道的东西:
return json.JSONEncoder.default(self, obj)
json.dumps(now, cls=DTEncoder)
四.yml
import yaml
with open('mcintyre.yaml', 'rt') as fin:
text = fin.read()
data = yaml.load(text)
data['details']
len(data['poems'])
data['poems'][1]['title'] #获得第二行
五.配置文件
[english]
greeting = Hello
[french]
greeting = Bonjour
[files]
home = /usr/local
# 简单的插入:
bin = %(home)s/bin
import configparser
cfg = configparser.ConfigParser()
cfg.read('settings.cfg')
cfg['french']
cfg['french']['greeting']
cfg['files']['bin']
#返回节点列表
config.sections()
#指定节点下的
config.options(section)
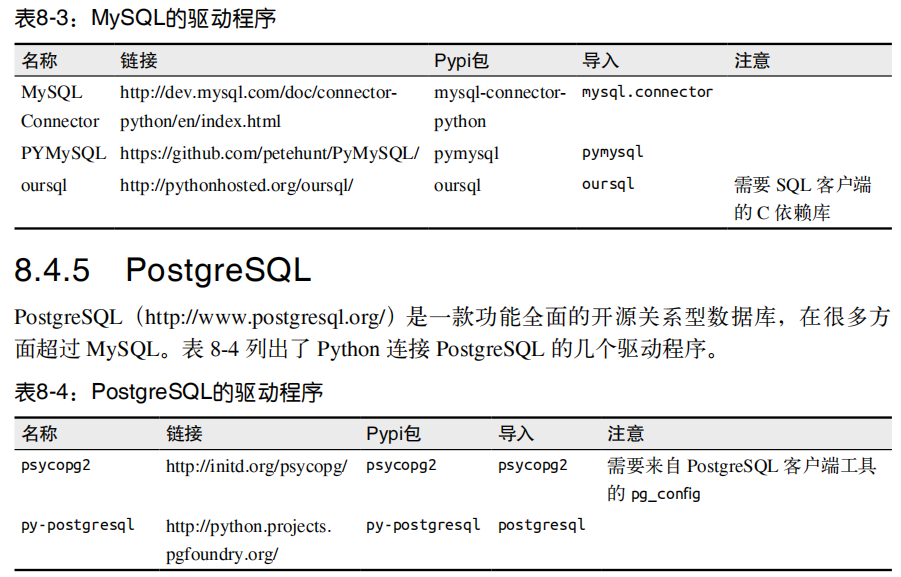
六.数据库
连接数据库,包含参数用户名、密码、服务器地址
connect()
创建一个cursor对象来管理查询
cursor()
对数据库执行一个或多个SQL命令
execute() 和 executemany()
得到execute之后的结果
fetchone()、fetchmany() 和 fetchall()
import sqlite3
conn = sqlite3.connect('enterprise.db')
curs = conn.cursor()
curs.execute('''CREATE TABLE zoo
(critter VARCHAR(20) PRIMARY KEY,
count INT,
damages FLOAT)''')
curs.execute('INSERT INTO zoo VALUES("duck", 5, 0.0)') #新增动物
curs.execute('INSERT INTO zoo VALUES("bear", 2, 1000.0)')
ins = 'INSERT INTO zoo (critter, count, damages) VALUES(?, ?, ?)'
curs.execute(ins, ('weasel', 1, 2000.0)) #更安全的插入数据方法
curs.execute('SELECT * FROM zoo') #获取数据
curs.fetchall()
curs.execute('SELECT * from zoo ORDER BY count') #按照count排序
curs.fetchall()
curs.execute('''SELECT * FROM zoo WHERE #哪种动物花费最多
damages = (SELECT MAX(damages) FROM zoo)''')
curs.close() #打开后要关闭
Python格式处理的更多相关文章
- python格式转换的记录
Python的格式转换太难了. 与其说是难,具体来说应该是"每次都会忘记该怎么处理".所以于此记录,总的来说是编码+格式转换的记录. 本文记录环境:python3.6 经常见到的格 ...
- PYTHON 格式字符串中的填充符
使用 %类型 来填充 常用的有:%s 填充字符串类型:%d 填充 int 类型:这里是沿用了 C语言中 printf() 函数中的格式,更多的信息请查看:完整列表 name = 'tommy' mes ...
- Python格式符说明
格式化输出 例如我想输出 我的名字是xxxx 年龄是xxxx name = "Lucy"age = 17print("我的名字是%s,年龄是%d"%(name, ...
- f-Strings:一种改进Python格式字符串的新方法
好消息是,F字符串在这里可以节省很多的时间.他们确实使格式化更容易.他们自Python 3.6开始加入标准库.您可以在PEP 498中阅读所有内容. 也称为“格式化字符串文字”,F字符串是开头有一个f ...
- Python——格式输出,基本数据
一.问题点(有待解决) 1.Python中只有浮点数,20和20.0是否一样? from decimal import Decimal a = Decimal('1.3') round() 参考文章 ...
- python 格式话-占位符
格式化输出:name = qjage = 30job = itsalary = 6000例1:字符串拼接方法,不建议,因为会在内存中开辟多块内存空间. info = '''---------- inf ...
- Python格式输出汇总
print ('%10s'%('test')) print ('{:<10}'.format('test'))#left-aligned print ('{:>10}'.format('t ...
- python格式字符
- Python web后端接收到的json数据有前端格式的布尔值 true false
最近在后端处理前端传过来的json数据,发现,因为数据是各种数据格式的嵌套,使用json.loads(),无法将内层的数据转换为原来格式的数据,所以需要使用eval( )函数进行转换,但是如果数据含有 ...
随机推荐
- python中jsonpath模块,解析多层嵌套的json数据
1. jsonpath介绍用来解析多层嵌套的json数据;JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, ...
- HashSet 如何保证元素不重复——hash码
HashSet 不重复主要add 方法实现,使用 add 方法找到是否存在元素,存在就不添加,不存在就添加.HashSet 主要是基于HashMap 实现的,HashMap 的key就是 HashSe ...
- 性能压测-压力测试-Apache JMeter安装使用
http://jmeter.apache.org/download_jmeter.cgi 下载win10得zip文件 在有java环境后进入项目得bin->jmeter.bat 启动 自带国际化 ...
- Abp Vnext Blazor替换UI组件 集成BootstrapBlazor(详细过程)
Abp Vnext自带的blazor项目使用的是 Blazorise,但是试用后发现不支持多标签.于是想替换为BootstrapBlazor. 过程比较复杂,本人已经把模块写好了只需要替换掉即可. 点 ...
- .net core 3.1 WebAPi 使用 AutoMapper 9.0、10.0
AutoMapper 可以很方便完成数据对象之间的转换. Dto -> Entity Entity -> ViewModel Step 1:通过 NuGet 安装 AutoMapper 的 ...
- Node.js实现前后端交互——用户注册
我之前写过一篇关于使用Node.js作为后端实现用户登陆的功能,现在再写一下node.js做后端实现简单的用户注册实例吧.另外需要说的是,上次有大佬提醒需要加密数据传输,不应该使用明文传输用户信息.在 ...
- WC2021 云划水记
Day -38 - 2459208(2020.12.24) CCF 发公告了,线上举办 hopping. 刚看到还纠结了一会儿,但想想还是报了.虽说是去摸鱼,打打暴力分就走人.但毕竟有牌和没牌也是不一 ...
- CF1202E You Are Given Some Strings...
题目传送门. 题意简述:给出 \(t\) 与 \(s_{1,2,\cdots,n}\).求对于所有 \(i,j\in[1,n]\),\(s_i+s_j\) 在 \(t\) 中出现次数之和. 如果只有 ...
- RNA-seq 生物学重复相关性验证
根据拿到的表达矩阵设为exprSet 1.用scale 进行标准化 数据中心化:数据集中的各个数字减去数据集的均值 数据标准化:中心化之后的数据在除以数据集的标准差. 在R中利用scale方法来对数据 ...
- 一款真正可以拿的出手的本土嵌入式RTOS-SylixOS
由 winniewei 提交于 周四, 12/20/2018 作者:张国斌 在参加工信部人才交流中心和南京浦口区开发区管委会联合举办的第三届集成电路产业紧缺人才创新发展高级研修班暨产业促进交流会期间, ...