MapReduce shuffle的过程分析
shuffle阶段其实就是多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。
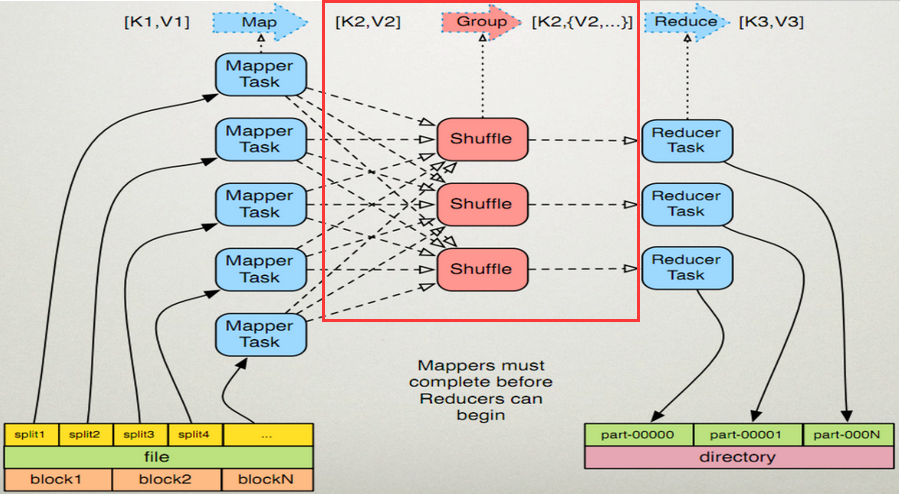

Map端:
1、在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生<K2,V2>的输出,这些输出先存放在缓存中,每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spil l.percent),一个后台线程就把内容写到(spill)Linux本地磁盘中的指定目录(mapred.local.dir)下的新建的一个溢出写文件。(注意:map过程的输出是写入本地磁盘而不是HDFS,但是一开始数据并不是直接写入磁盘而是缓冲在内存中,缓存的好处就是减少磁盘I/O的开销,提高合并和排序的速度。又因为默认的内存缓冲大小是100M(当然这个是可以配置的),所以在编写map函数的时候要尽量减少内存的使用,为shuffle过程预留更多的内存,因为该过程是最耗时的过程。)
2、写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。(注意:在写磁盘的时候采用压缩的方式将map的输出结果进行压缩是一个减少网络开销很有效的方法!)
3、最后将磁盘中的数据送到Reduce中,从图中可以看出Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入则来自其他节点的Map输出。
Reduce端:
1、Copy阶段:Reducer通过Http方式得到输出文件的分区。reduce端可能从n个map的结果中获取数据,而这些map的执行速度不尽相同,当其中一个map运行结束时,reduce就会从JobTracker中获取该信息。map运行结束后TaskTracker会得到消息,进而将消息汇报给JobTracker,reduce定时从JobTracker获取该信息,reduce端默认有5个数据复制线程从map端复制数据。
2、Merge阶段:如果形成多个磁盘文件会进行合并从map端复制来的数据首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中。
3、Reducer的参数:最后将合并后的结果作为输入传入Reduce任务中。(注意:当Reducer的输入文件确定后,整个Shuffle操作才最终结束。之后就是Reducer的执行了,最后Reducer会把结果存到HDFS上。)
MapReduce shuffle的过程分析的更多相关文章
- shuffle的过程分析
shuffle的过程分析 shuffle阶段其实就是之前<MapReduce的原理及执行过程>中的步骤2.1.多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点 ...
- MapReduce Shuffle过程
MapReduce Shuffle 过程详解 一.MapReduce Shuffle过程 1. Map Shuffle过程 2. Reduce Shuffle过程 二.Map Shuffle过程 1. ...
- hadoop2.0安装中遇到的错误:mapreduce.shuffle set in yarn.nodemanager.aux-services is invalid
转:http://blog.csdn.net/bamuta/article/details/12995139 解决办法 : 在1个网站上找到了解决方法,(网络忘了没记)urg, my copy/pas ...
- MapReduce Shuffle原理 与 Spark Shuffle原理
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
- MapReduce shuffle过程剖析及调优
MapReduce简介 在Hadoop MapReduce中,框架会确保reduce收到的输入数据是根据key排序过的.数据从Mapper输出到Reducer接收,是一个很复杂的过程,框架处理了所有问 ...
- 彻底理解MapReduce shuffle过程原理
彻底理解MapReduce shuffle过程原理 MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapR ...
- 大话Spark(4)-一文理解MapReduce Shuffle和Spark Shuffle
Shuffle本意是 混洗, 洗牌的意思, 在MapReduce过程中需要各节点上同一类数据汇集到某一节点进行计算,把这些分布在不同节点的数据按照一定的规则聚集到一起的过程成为Shuffle. 在Ha ...
- MapReduce Shuffle 和 Spark Shuffle 原理概述
Shuffle简介 Shuffle的本意是洗牌.混洗的意思,把一组有规则的数据尽量打乱成无规则的数据.而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规 ...
随机推荐
- IDEA 使用与总结
一.IDEA和常用软件下载1.IDEA激活码网站:http://idea.lanyus.com/常用软件网站 idea : https://www.jetbrains.com/idea/downloa ...
- 【翻译】--19C Oracle 安装指导
18C新功能 1.简化的基于镜像的Oracle数据库安装 从18C开始,Oracle可以作为镜像文件来下载和安装,必须解压缩镜像文件到ORACLE_HOME目录,然后执行runInst ...
- 315 · Istio1.1 功能预告,真的假不了
Istio 1.0版本发布到现在,已经过去8个月.Istio1.1的候选版本也到了rc5,预计近期会正式发布1.1.此版本包含了许多错误修复,在流量管理,安全,策略和遥测,多集群等领域添加了新的功能. ...
- webpack中环境变量的使用方法
这节课讲解一下,在webpack打包过程中,怎么去使用一些环境变量. 首先我有一个打包配置的三个文件 "scripts": { "dev-build": &qu ...
- mongodb的基本操作之数据删除
删除操作使用remove进行,数据的删除与查询类似,接受一个参数,与查询不同的是,为了防止误操作,删除操作不允许不传参数 比如 db.test_collection.remove() 会报错 Erro ...
- Window脚本学习笔记之定时关闭进程
定时关闭进程, 从字面上即可看出操作分为两个步骤,即: 1,结合“任务计划程序”,定时. “计算机->管理->计划任务程序”,作用是让系统定时启动脚本文件(bat脚本). 2,结合“nt ...
- Java集合--Set架构
前面,我们已经系统的对List和Map进行了学习.接下来,我们开始可以学习Set.相信经过Map的了解之后,学习Set会容易很多.毕竟,Set的实现类都是基于Map来实现的(HashSet是通过Has ...
- Property or method "openPageOffice" is not defined on the instance but referenced during render. Make sure that this property is reactive, either in the data option, or for class-based components, by
Property or method "openPageOffice" is not defined on the instance but referenced during r ...
- python中的数据类型(二)
一.列表(list) 列表是可变的,有序的(只要能索引的都是有序的) 列表的基本操作: 1.增 1.append 追加 例:lst.append(8) print (ls ...
- struts2之使用oracle分页(10)
ToolsUtil //每页显示的记录数 public static final int NUM_PER_PAGE=5; /* * java.util.Date转java.sql.Date */ pu ...