图的深度优先遍历(DFS)和广度优先遍历(BFS)算法分析
1. 深度优先遍历
深度优先遍历(Depth First Search)的主要思想是:
1、首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点;
2、当没有未访问过的顶点时,则回到上一个顶点,继续试探别的顶点,直至所有的顶点都被访问过。
在此我想用一句话来形容 “不到南墙不回头”。
1.1 无向图的深度优先遍历图解
以下"无向图"为例:
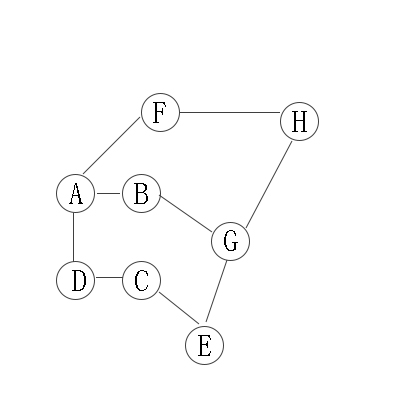
对上无向图进行深度优先遍历,从A开始:
第1步:访问A。
第2步:访问B(A的邻接点)。 在第1步访问A之后,接下来应该访问的是A的邻接点,即"B,D,F"中的一个。但在本文的实现中,顶点ABCDEFGH是按照顺序存储,B在"D和F"的前面,因此,先访问B。
第3步:访问G(B的邻接点)。 和B相连只有"G"(A已经访问过了)
第4步:访问E(G的邻接点)。 在第3步访问了B的邻接点G之后,接下来应该访问G的邻接点,即"E和H"中一个(B已经被访问过,就不算在内)。而由于E在H之前,先访问E。
第5步:访问C(E的邻接点)。 和E相连只有"C"(G已经访问过了)。
第6步:访问D(C的邻接点)。
第7步:访问H。因为D没有未被访问的邻接点;因此,一直回溯到访问G的另一个邻接点H。
第8步:访问(H的邻接点)F。
因此访问顺序是:A -> B -> G -> E -> C -> D -> H -> F
1.2 有向图的深度优先遍历
有向图的深度优先遍历图解:
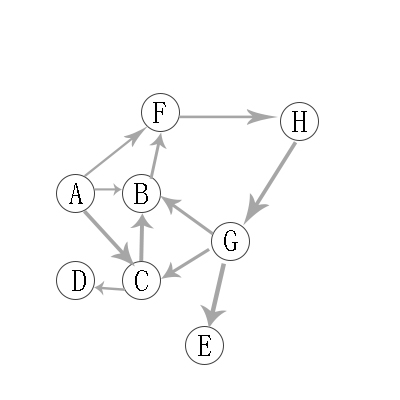
对上有向图进行深度优先遍历,从A开始:
第1步:访问A。
第2步:访问(A的出度对应的字母)B。 在第1步访问A之后,接下来应该访问的是A的出度对应字母,即"B,C,F"中的一个。但在本文的实现中,顶点ABCDEFGH是按照顺序存储,B在"C和F"的前面,因此,先访问B。
第3步:访问(B的出度对应的字母)F。 B的出度对应字母只有F。
第4步:访问H(F的出度对应的字母)。 F的出度对应字母只有H。
第5步:访问(H的出度对应的字母)G。
第6步:访问(G的出度对应字母)E。 在第5步访问G之后,接下来应该访问的是G的出度对应字母,即"B,C,E"中的一个。但在本文的实现中,顶点B已经访问了,由于C在E前面,所以先访问C。
第7步:访问(C的出度对应的字母)D。
第8步:访问(C的出度对应字母)D。 在第7步访问C之后,接下来应该访问的是C的出度对应字母,即"B,D"中的一个。但在本文的实现中,顶点B已经访问了,所以访问D。
第9步:访问E。D无出度,所以一直回溯到G对应的另一个出度E。
因此访问顺序是:A -> B -> F -> H -> G -> C -> D -> E
2.广度优先遍历
广度优先遍历(Depth First Search)的主要思想是:类似于树的层序遍历。
2.1 无向图的广度优先遍历图解:
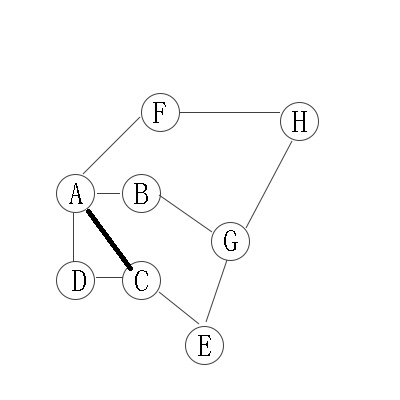
从A开始,有4个邻接点,“B,C,D,F”,这是第二层;
在分别从B,C,D,F开始找他们的邻接点,为第三层。以此类推。
因此访问顺序是:A -> B -> C -> D -> F -> G -> E -> H
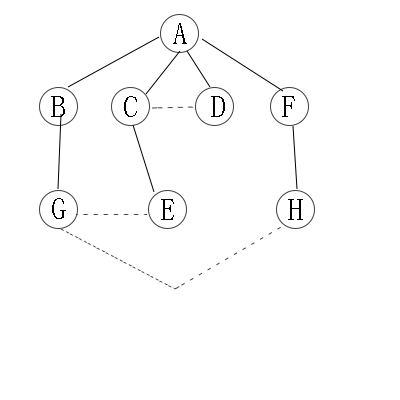
2.2 有向图的广度优先遍历图解:
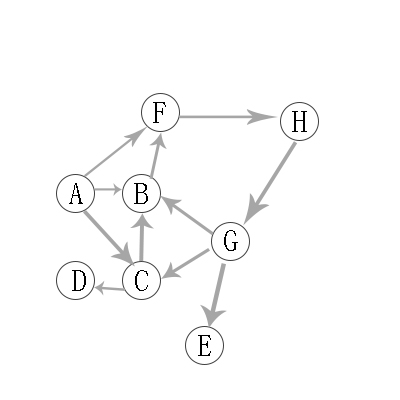
与无向图类似 。可以参考。
因此访问顺序是:A -> B -> C -> F -> D -> H -> E -> G
没有贴代码,需要可以给博主私哦。
PS:打字不易,转载请说明出处。
图的深度优先遍历(DFS)和广度优先遍历(BFS)算法分析的更多相关文章
- 图的深度优先搜索(DFS)和广度优先搜索(BFS)算法
深度优先(DFS) 深度优先遍历,从初始访问结点出发,我们知道初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接 ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析(新手向)
深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每个点仅被访问一次,这个过程就是图的遍历.图的遍历常用的有深度优先搜索和广度优先搜索,这两者对于有向图和无向图 ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析
转自:https://www.cnblogs.com/FZfangzheng/p/8529132.html 深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每 ...
- 图的 储存 深度优先(DFS)广度优先(BFS)遍历
图遍历的概念: 从图中某顶点出发访遍图中每个顶点,且每个顶点仅访问一次,此过程称为图的遍历(Traversing Graph).图的遍历算法是求解图的连通性问题.拓扑排序和求关键路径等算法的基础.图的 ...
- 图的深度优先遍历(DFS)和广度优先遍历(BFS)
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 深度优先搜索DFS和广度优先搜索BFS
DFS简介 深度优先搜索,一般会设置一个数组visited记录每个顶点的访问状态,初始状态图中所有顶点均未被访问,从某个未被访问过的顶点开始按照某个原则一直往深处访问,访问的过程中随时更新数组visi ...
- 图的遍历(搜索)算法(深度优先算法DFS和广度优先算法BFS)
图的遍历的定义: 从图的某个顶点出发访问遍图中所有顶点,且每个顶点仅被访问一次.(连通图与非连通图) 深度优先遍历(DFS): 1.访问指定的起始顶点: 2.若当前访问的顶点的邻接顶点有未被访问的,则 ...
- 【C++】基于邻接矩阵的图的深度优先遍历(DFS)和广度优先遍历(BFS)
写在前面:本博客为本人原创,严禁任何形式的转载!本博客只允许放在博客园(.cnblogs.com),如果您在其他网站看到这篇博文,请通过下面这个唯一的合法链接转到原文! 本博客全网唯一合法URL:ht ...
- 图的深度优先搜索dfs
图的深度优先搜索: 1.将最初访问的顶点压入栈: 2.只要栈中仍有顶点,就循环进行下述操作: (1)访问栈顶部的顶点u: (2)从当前访问的顶点u 移动至顶点v 时,将v 压入栈.如果当前顶点u 不存 ...
随机推荐
- CPCT精细化运营:客户、产品、渠道、时机
关键词:CPCT.精细化运营思维.客户.产品.渠道.时机.运营 电信运营商市场饱和,用户新增主要靠弃卡后重新入网以及异网用户策反. 用户新增已如此艰难,所以更加关注存量用户经营. 运营商营销资源不断收 ...
- Servlet实现图片文件上传
1.首先要导入以下两个jar包: commons-fileupload-1.2.1.jarcommons-io-1.4.jar 2.jsp文件:index.jsp <%@ page langua ...
- JS有关引用对象的拷贝问题
JS中有关引用对象的拷贝问题 问题描述:在开发过程中,拷贝一个对象数组给另一个数组的时候,改变新数组中对象的属性值,原数组中的对象属性值也跟着改变了. 例如新定义一个数组arr1,里面有两个对象,然后 ...
- [Vuex系列] - 细说state的几种用法
state 存放的是一个对象,存放了全部的应用层级的状态,主要是存放我们日常使用的组件之间传递的变量. 我们今天重点讲解下state的几种用法,至于如何从头开始创建Vuex项目,请看我写的第一个文章. ...
- iOS分类(category),类扩展(extension)—史上最全攻略
背景: 在大型项目,企业级开发中多人同时维护同一个类,此时程序员A因为某项需求只想给当前类currentClass添加一个方法newMethod,那该怎么办呢? 最简单粗暴的方式是把newMethod ...
- Java知识导航总图
1.系统构架 企业服务总线(ESB).微服务.面向服务的架构(SOA) 了解分布式文件存储系统,掌握集群化开发及部署 2.系统系统集成技术 Wsbservice.Socket 3.RPC远程调用的相关 ...
- graph Laplacian 拉普拉斯矩阵
转自:https://www.kechuang.org/t/84022?page=0&highlight=859356,感谢分享! 在机器学习.多维信号处理等领域,凡涉及到图论的地方,相信小伙 ...
- MySQL数字类型int与tinyint、float与decimal如何选择
最近在准备给开发做一个mysql数据库开发规范方面培训,一步一步来,结合在生产环境发现的数据库方面的问题,从几个常用的数据类型说起. int.tinyint与bigint 它们都是(精确)整型数据类型 ...
- v-solt插槽
https://www.jb51.net/article/157565.htm https://juejin.im/post/5c64e11151882562e4726d98
- [转载]Java进程物理内存远大于Xmx的问题分析
进程物理内存远大于Xmx的问题分析 问题描述 最近经常被问到一个问题,”为什么我们系统进程占用的物理内存(Res/Rss)会远远大于设置的Xmx值”,比如Xmx设置1.7G,但是top看到的Res的值 ...