SpringCloud(七)之SpringCloud的链路追踪组件Sleuth实战,以及 zipkin 的部署和使用
一、前言
Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案 ,并且兼容了zipkin,提供了REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序 。
Sleuth 是个组件,没有提供我们可视化的界面,和一些相信的api信息,而zipkin 是个系统,他有可视化的界面,和对应接口调用详细的信息情况。
二、为什么要使用链路追踪
微服务架构上通过业务来划分服务的,通过REST调用,对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能,如果链路上任何一个服务出现问题或者网络超时,都会形成导致接口调用失败。随着业务的不断扩张,服务之间互相调用会越来越复杂。
,对调用链的分析会越来越复杂。如果那里出现了错误,我们是很排查的。所以我们引入了链路追踪,使用可视化的界面我们可以很容易的找到那一块耗时多,等等。
Sleuth 的使用:
1.在项目中加入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
2.然后在你想打印日志的地方输入
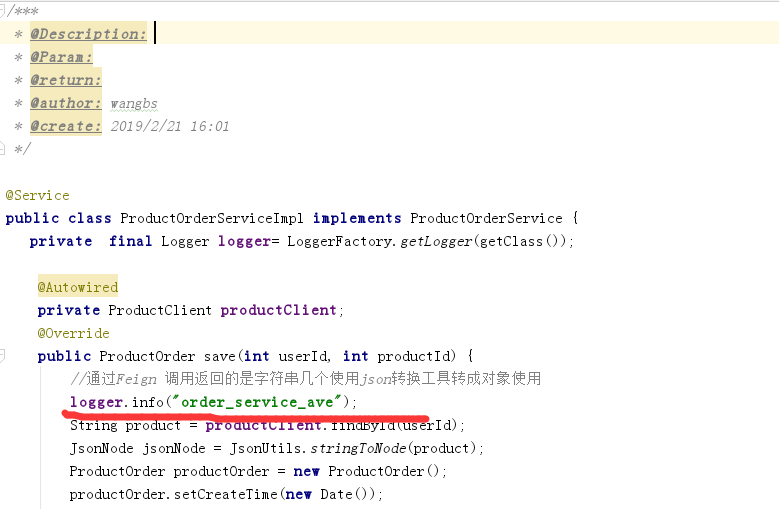
控制台会出现下面这个 (现在看起来是不是感觉使用起来也不怎方便,下面我会讲zipkin,他提供了可视化界面,看的就清楚多了。)
[order-service,96f95a0dd81fe3ab,852ef4cfcdecabf3,false]
1、第一个值,spring.application.name的值
2、第二个值,96f95a0dd81fe3ab ,sleuth生成的一个ID,叫Trace ID,用来标识一条请求链路,一条请求链路中包含一个Trace ID,多个Span ID
3、第三个值,852ef4cfcdecabf3、spanid 基本的工作单元,获取元数据,如发送一个http
4、第四个值:false,是否要将该信息输出到zipkin服务中来收集和展示。
3、可视化链路追踪系统Zipkin
大规模分布式系统的APM工具(Application Performance Management),基于Google Dapper的基础实现,和sleuth结合可以提供可视化web界面分析调用链路耗时情况
3.1 可视化链路追踪系统Zipkin部署。(我使用的是docker 我后面会讲下docker的部署,很简单的)
//阿里提供的部署Zipkin的方法,里面讲了好几种 包括java 部署 和docker 部署
docker部署:
docker run -d -p 9411:9411 openzipkin/zipkin
这样就搞定了 ,然后ip+端口就能访问:
3.2 代码中的使用。
那个项目想要链路追踪就都加入下面的两个配置
3.1.1 加入依赖
<!--里面包含 spring-cloud-starter-sleuth、spring-cloud-sleuth-zipkin ->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
3.1.1 配置文件添加
#服务的名称
spring:
application:
name: order-service
#zipkin服务所在地址
zipkin:
base-url: http://47.XX.XX.XX:9411/
#配置采样百分比,开发环境可以设置为1,表示全部,生产就用默认(0.1)
sleuth:
sampler:
probability: 1
3.2 测试
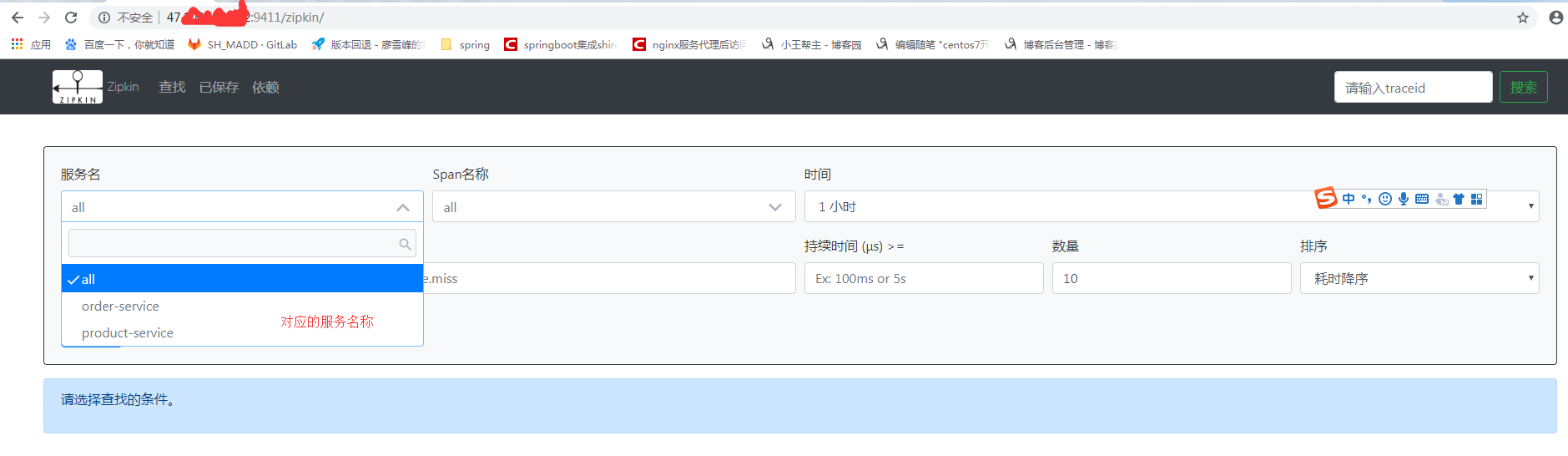
调用 api 接口

查看Zipkin 可视化系统
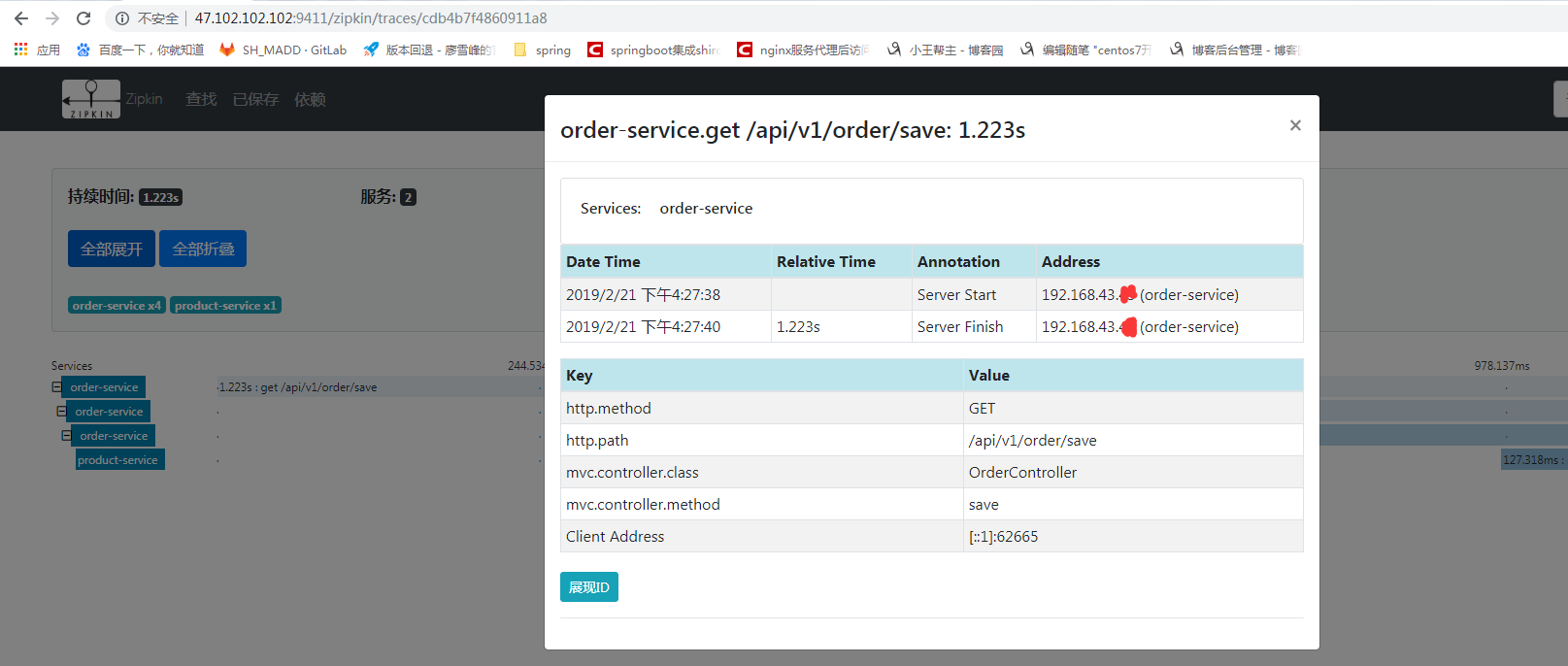
这样详细信息就全部追踪到了。
3.4 大致说下 Sleuth 和Zipkin 是怎么调用的.
sleuth收集跟踪信息通过http请求发送给zipkin server,zipkinserver进行跟踪信息的存储以及提供Rest API即可,Zipkin UI调用其API接口进行数据展示
默认存储是内存,可也用mysql、或者elasticsearch等存储。 所以说,Sleuth 才是根本,而Zipkin 这是进行了对数据的分析和展示。
SpringCloud(七)之SpringCloud的链路追踪组件Sleuth实战,以及 zipkin 的部署和使用的更多相关文章
- spring cloud链路追踪组件sleuth和zipkin
spring cloud链路追踪组件sleuth 主要作用就是日志埋点 操作方法 1.增加依赖 <dependency> <groupId& ...
- springCloud的使用08-----服务链路追踪(sleuth+zipkin)
sleuth主要功能是在分布式系统中提供追踪解决方案,并且兼容支持了zipkin(提供了链路追踪的可视化功能) zipkin原理:在服务调用的请求和响应中加入ID,表明上下游请求的关系. 利用这些信息 ...
- Spring Cloud 整合分布式链路追踪系统Sleuth和ZipKin实战,分析系统瓶颈
导读 微服务架构中,是否遇到过这种情况,服务间调用链过长,导致性能迟迟上不去,不知道哪里出问题了,巴拉巴拉....,回归正题,今天我们使用SpringCloud组件,来分析一下微服务架构中系统调用的瓶 ...
- 分布式链路追踪系统Sleuth和ZipKin
1.微服务下的链路追踪讲解和重要性 简介:讲解什么是分布式链路追踪系统,及使用好处 进行日志埋点,各微服务追踪. 2.SpringCloud的链路追踪组件Sleuth 1.官方文档 http://cl ...
- SpringCloud(7)服务链路追踪Spring Cloud Sleuth
1.简介 Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案,并且兼容支持了 zipkin,你只需要在pom文件中引入相应的依赖即可.本文主要讲述服务追踪组件zipki ...
- 史上最简单的SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)(Finchley版本)
转载请标明出处: 原文首发于:>https://www.fangzhipeng.com/springcloud/2018/08/30/sc-f9-sleuth/ 本文出自方志朋的博客 这篇文章主 ...
- 史上最简单的SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)
这篇文章主要讲述服务追踪组件zipkin,Spring Cloud Sleuth集成了zipkin组件. 注意情况: 该案例使用的spring-boot版本1.5.x,没使用2.0.x, 另外本文图3 ...
- SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)
版权声明:本文为博主原创文章,欢迎转载,转载请注明作者.原文超链接 ,博主地址:http://blog.csdn.net/forezp. http://blog.csdn.net/forezp/art ...
- Spring Boot + Spring Cloud 实现权限管理系统 后端篇(二十二):链路追踪(Sleuth、Zipkin)
在线演示 演示地址:http://139.196.87.48:9002/kitty 用户名:admin 密码:admin 技术背景 在微服务架构中,随着业务发展,系统拆分导致系统调用链路愈发复杂,一个 ...
随机推荐
- 文件的空间使用和IO统计
数据库占用的存储空间,从高层次来看,可以查看数据库文件(数据文件,日志文件)占用的存储空间,从较细的粒度上来看,分为数据表,索引,分区占用的存储空间.监控数据库对象占用的硬盘空间,包括已分配,未分配, ...
- 11.SpringMVC注解式开发-处理器方法的返回值
处理器方法的返回值 使用@Controller 注解的处理器的处理器方法,其返回值常用的有四种类型 1.ModelAndView 2.String 3.void 4.自定义类型对象 1.返回Model ...
- 【Java并发】线程安全和内存模型
一.概述 1.1 什么是线程安全? 1.2 案例 1.3 线程安全解决办法: 二.synchronized 2.1 概述 2.2 同步代码块 2.3 同步方法 2.4 静态同步函数 2.5 总结 三. ...
- 三、DQL语言
目录 一.基础查询 (一)语法 (二)特点 (三)示例 二.条件查询 (一)语法 (二)筛选条件的分类 三.排序查询 (一)语法 (二)特点 四.常见函数 (一)介绍 (二)分类 五.单行函数 (一) ...
- Python入门之第三方模块安装
Python入门之第三方模块安装 平台:Win10 x64 + Anaconda3-5.3.0 (+Python3.7.0) Issue说明:pip install line_profiler-2.1 ...
- vue-element-admin后台的安装
# 克隆项目 git clone https://github.com/PanJiaChen/vue-element-admin.git # 进入项目目录 cd vue-element-admin # ...
- C#信号量(Semaphore,SemaphoreSlim)
Object->MarshalByRefObject->WaitHandle->Semaphore 1.作用: 多线程环境下,可以控制线程的并发数量来限制对资源的访问 2.举例: S ...
- 好不容易当上技术管理者,却时常担心被下属diss技术水平,怎么办?
作者 | 刘建国出处 | 极客时间<技术管理实战 36 讲>专栏编辑 | Natalie 转型做管理后,你可以用在技术上的时间会越来越少,尤其是写代码的机会越来越少,手越来越生,但是要做的 ...
- 2018-2019 ACM-ICPC Nordic Collegiate Programming Contest (NCPC 2018) D. Delivery Delays (二分+最短路+DP)
题目链接:https://codeforc.es/gym/101933/problem/D 题意:地图上有 n 个位置和 m 条边,每条边连接 u.v 且有一个距离 w,一共有 k 个询问,每个询问表 ...
- ACM-ICPC 2018 青岛赛区网络预赛 J. Press the Button(数学)
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=4056 题意:有一个按钮,时间倒计器和计数器,在时间[0,t]内, ...