Spring Cloud 整合分布式链路追踪系统Sleuth和ZipKin实战,分析系统瓶颈
导读
微服务架构中,是否遇到过这种情况,服务间调用链过长,导致性能迟迟上不去,不知道哪里出问题了,巴拉巴拉....,回归正题,今天我们使用SpringCloud组件,来分析一下微服务架构中系统调用的瓶颈问题~
SpringCloud链路追踪组件Sleuth实战
官网

主要功能:做日志埋点
什么是Sleuth
专门用于追踪每个请求的完整调用链路。
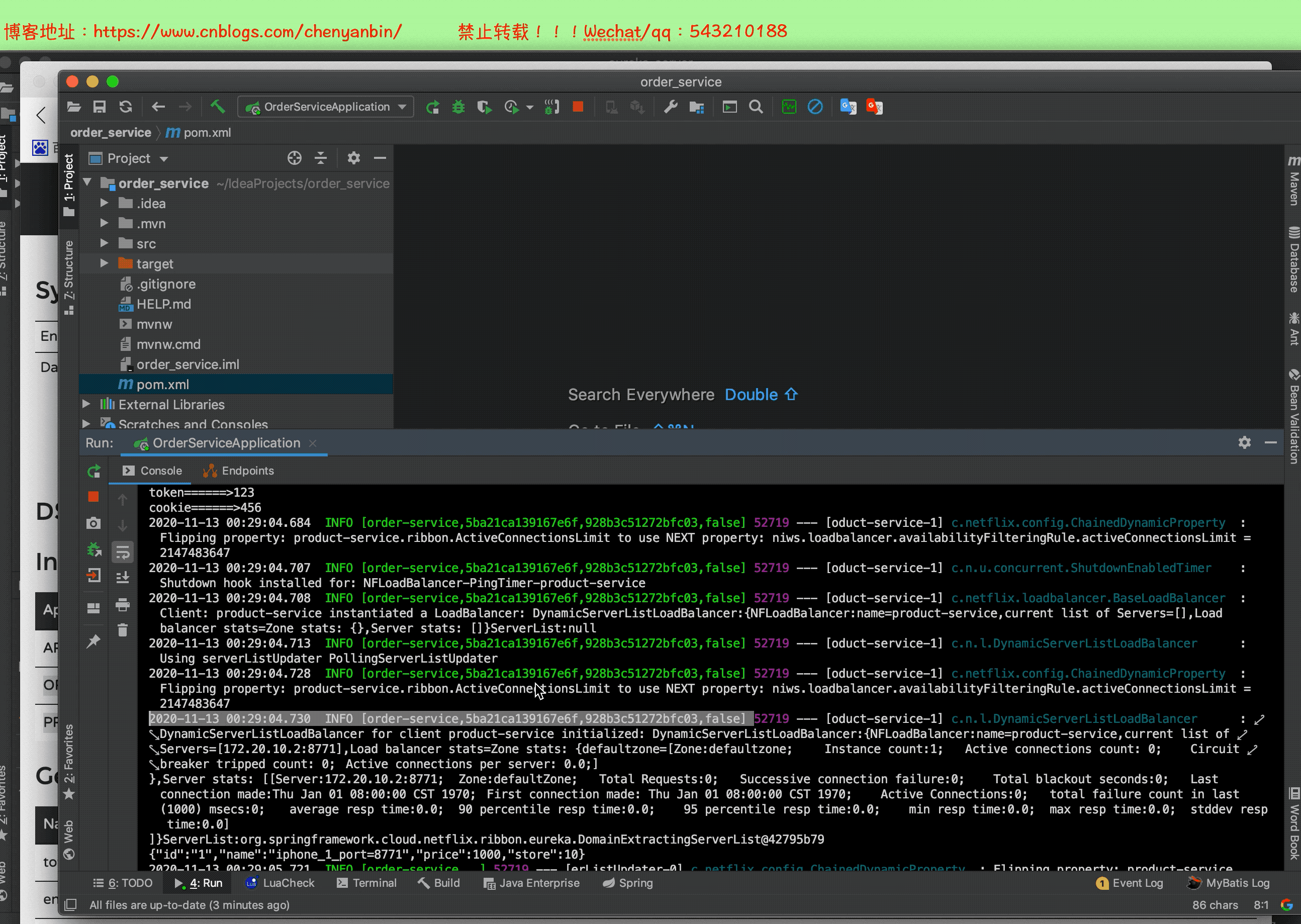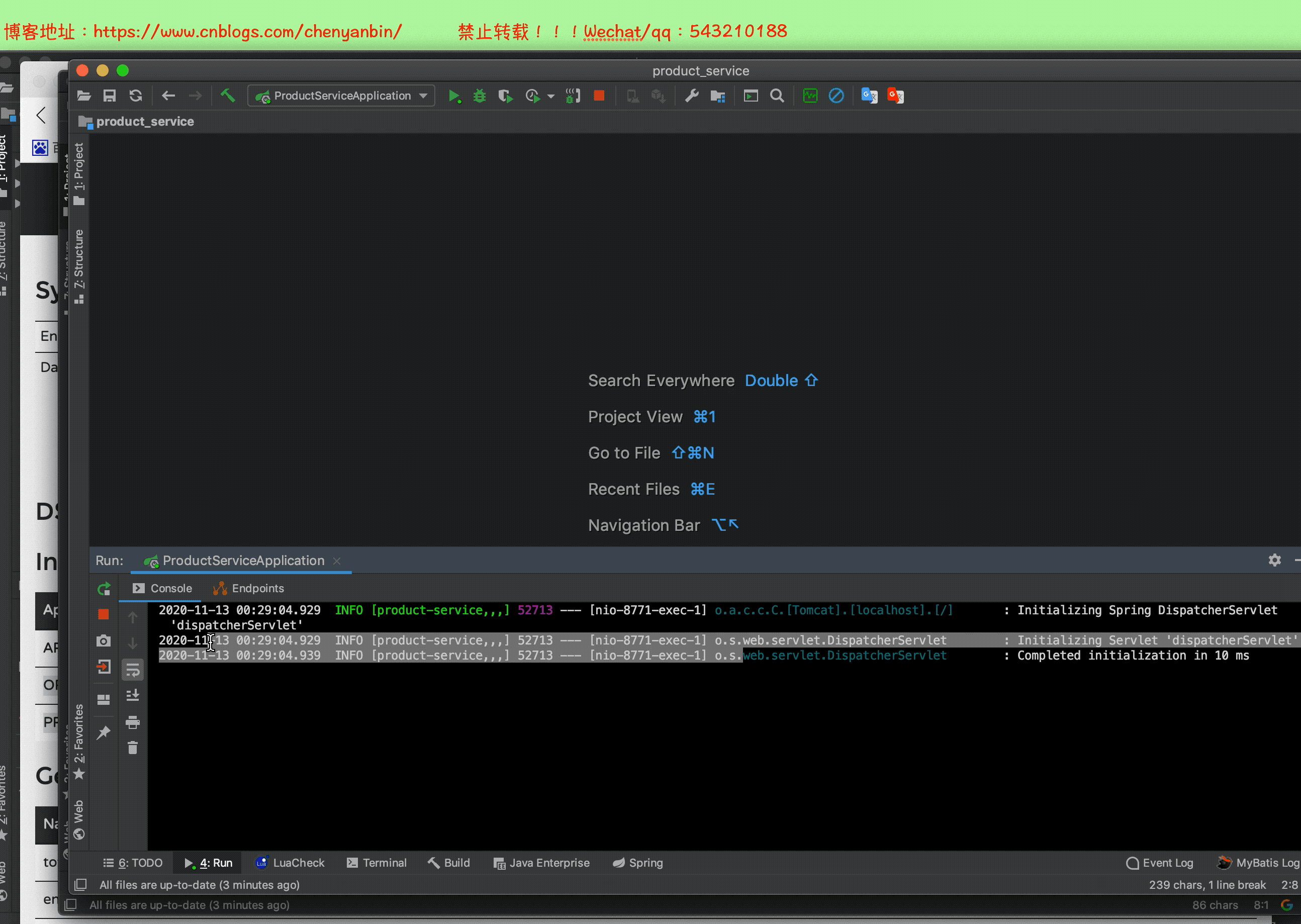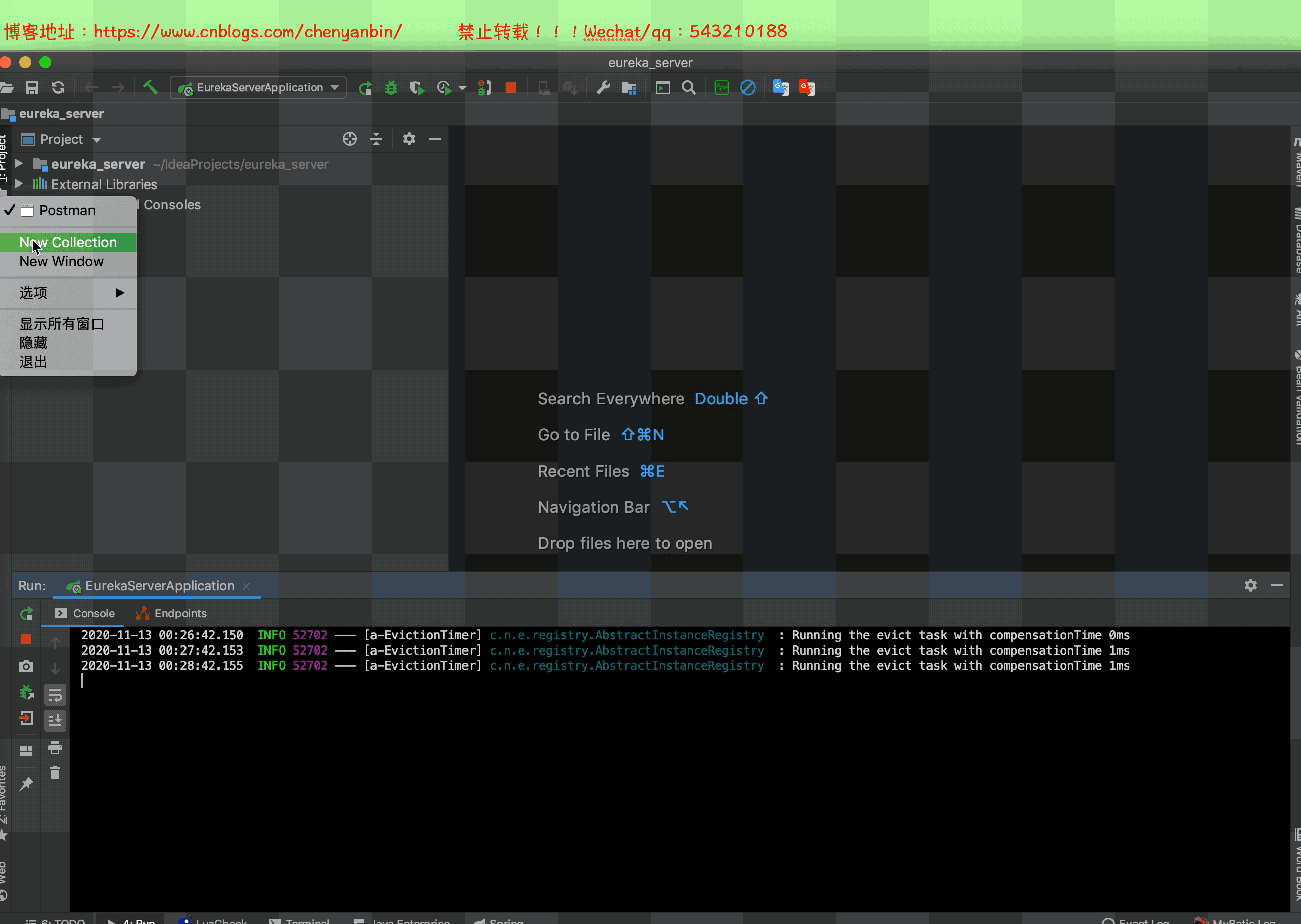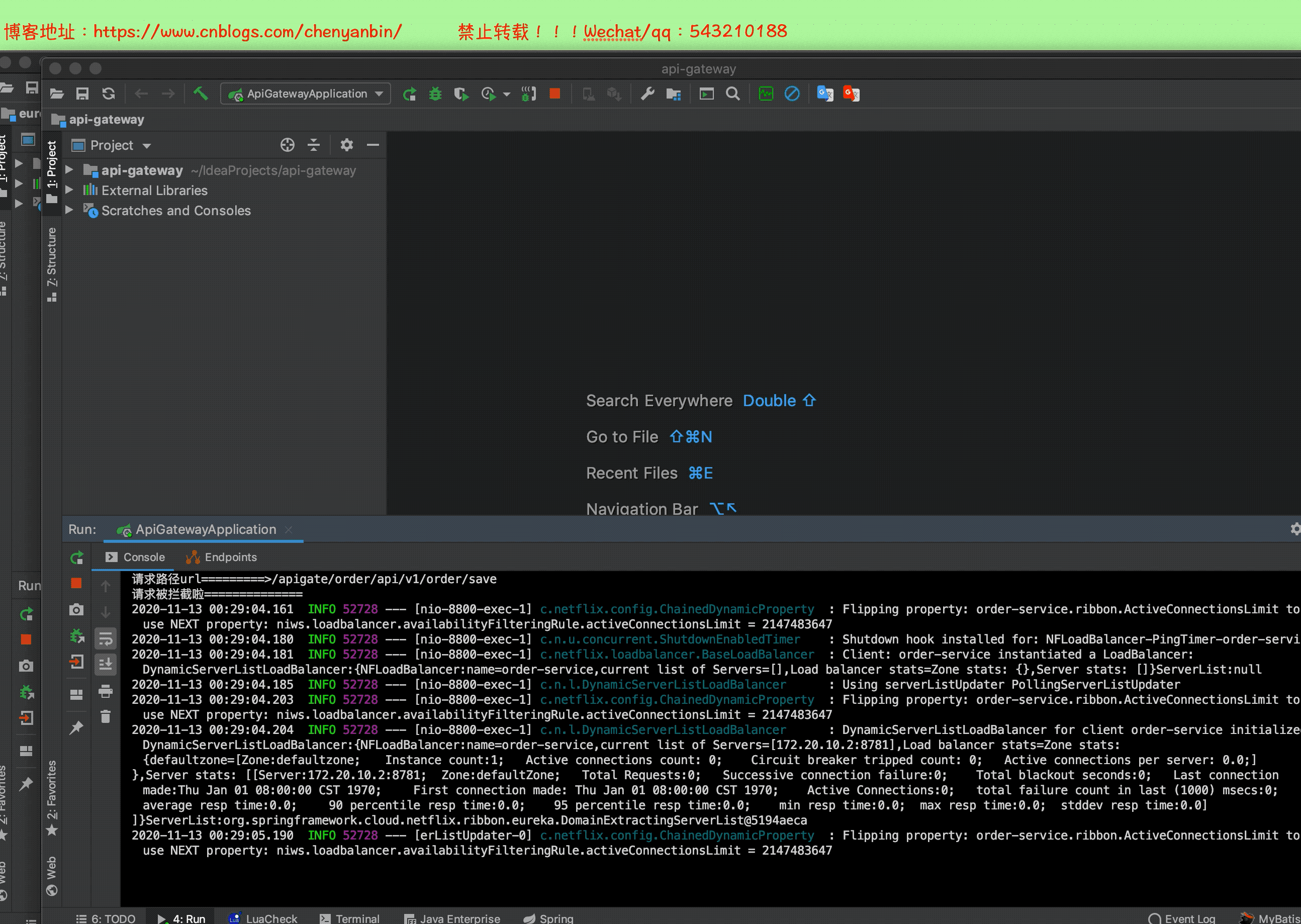
例如:【order-service,f674cc8202579a50,4727309367e0b514,false】
- 第一个值:spring.application.name
- 第二个值,sleuth生成的一个ID,交Trace ID,用来标识一条请求链路,一条请求链路中包含一个Trace ID,多个Span ID
- 第三个值:spanid基本的工作单元,获取元数据,如发送一个http请求
- 第四个值:false,是否要将该信息输出到zipkin服务中来收集和展示
添加依赖
牵扯到的服务都得加这个依赖!(我这里是在order-service、product-service加的依赖)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
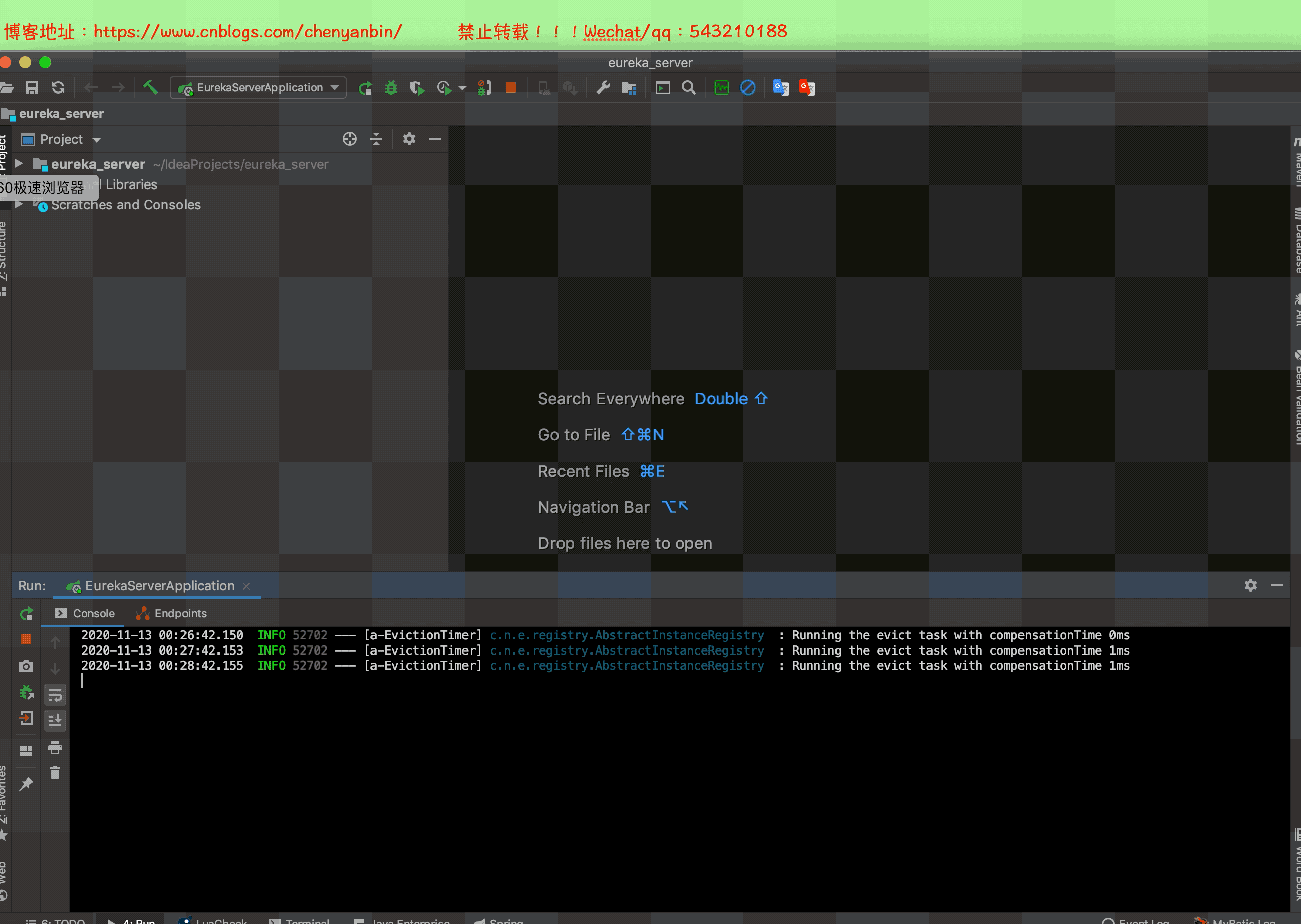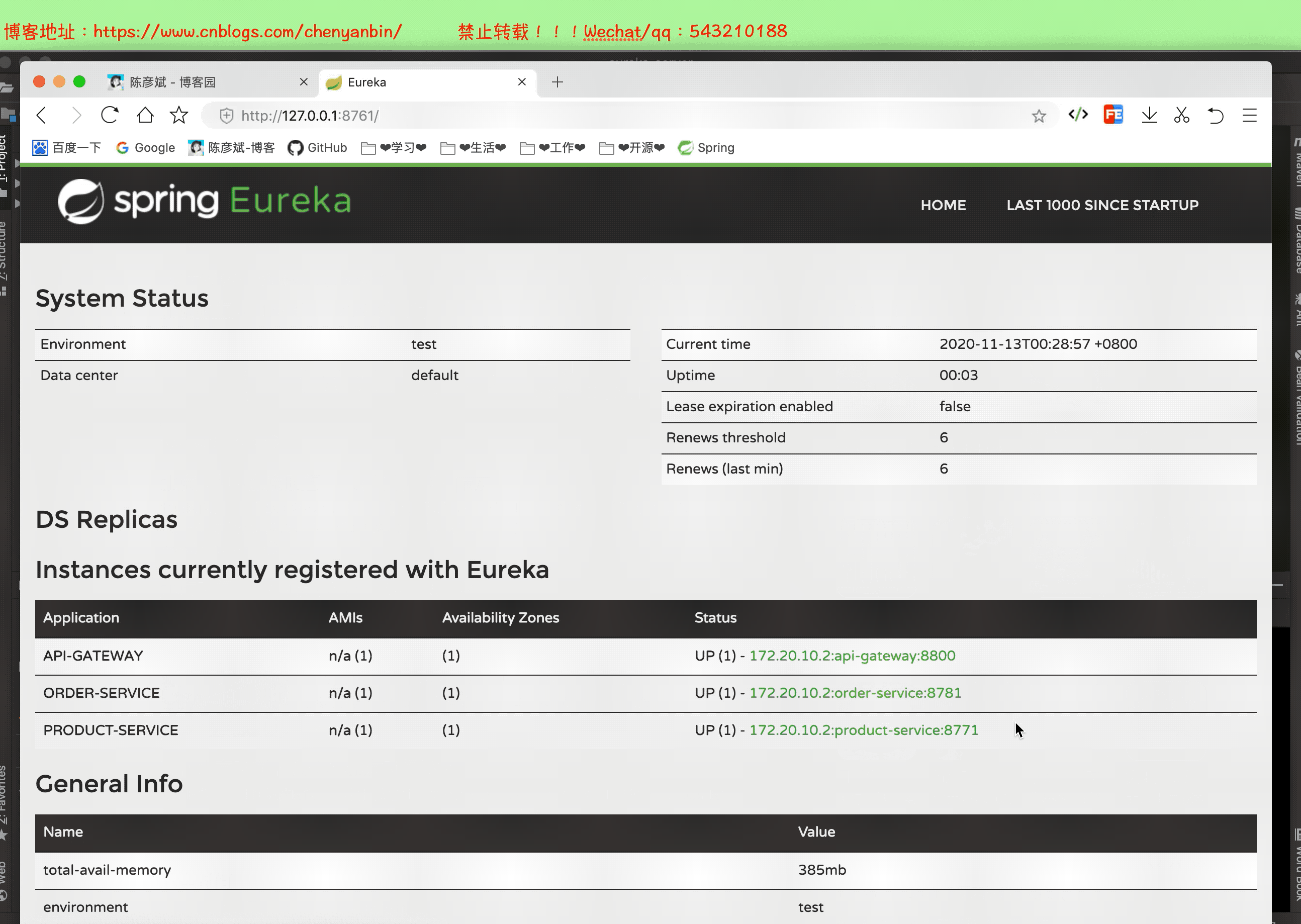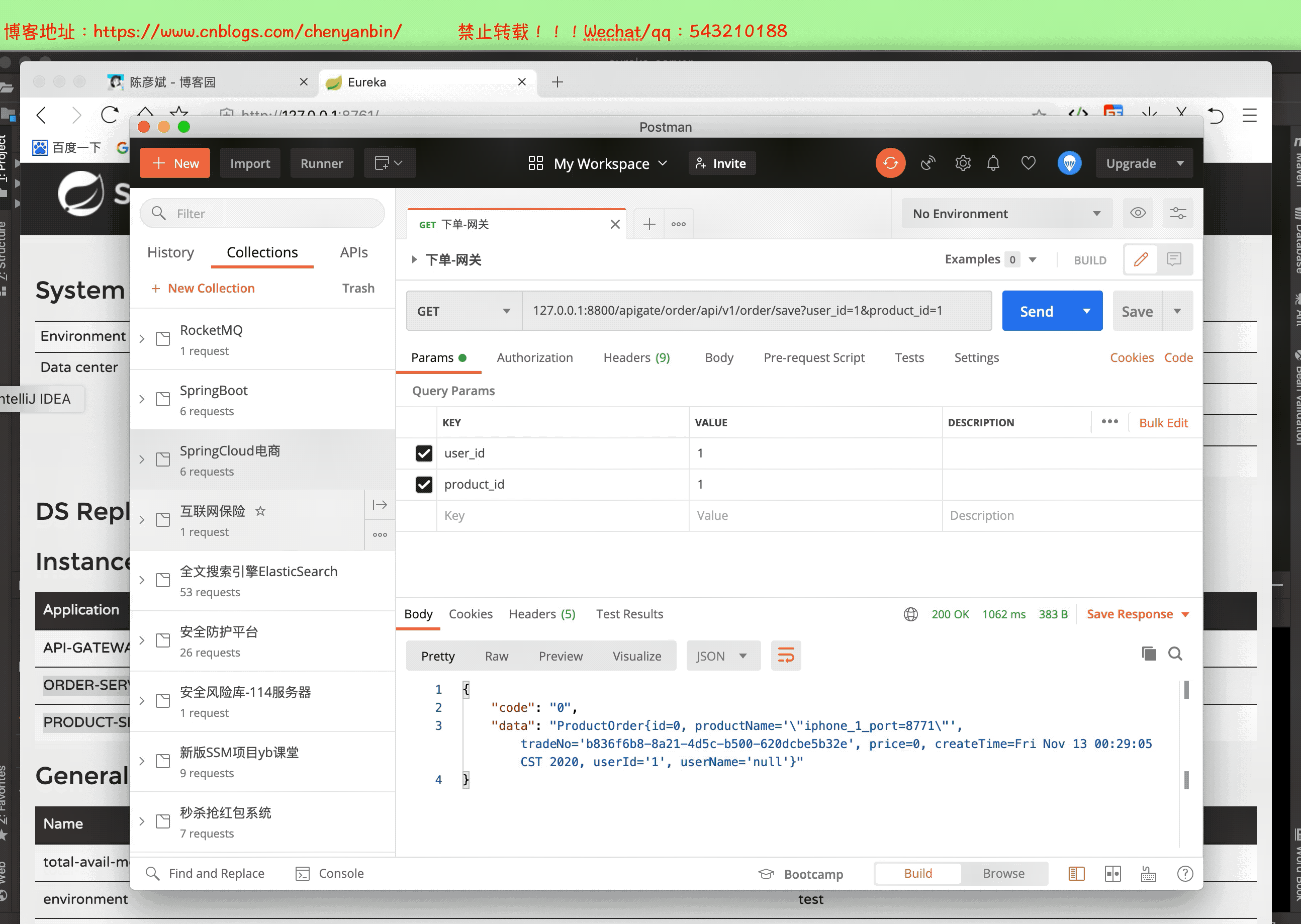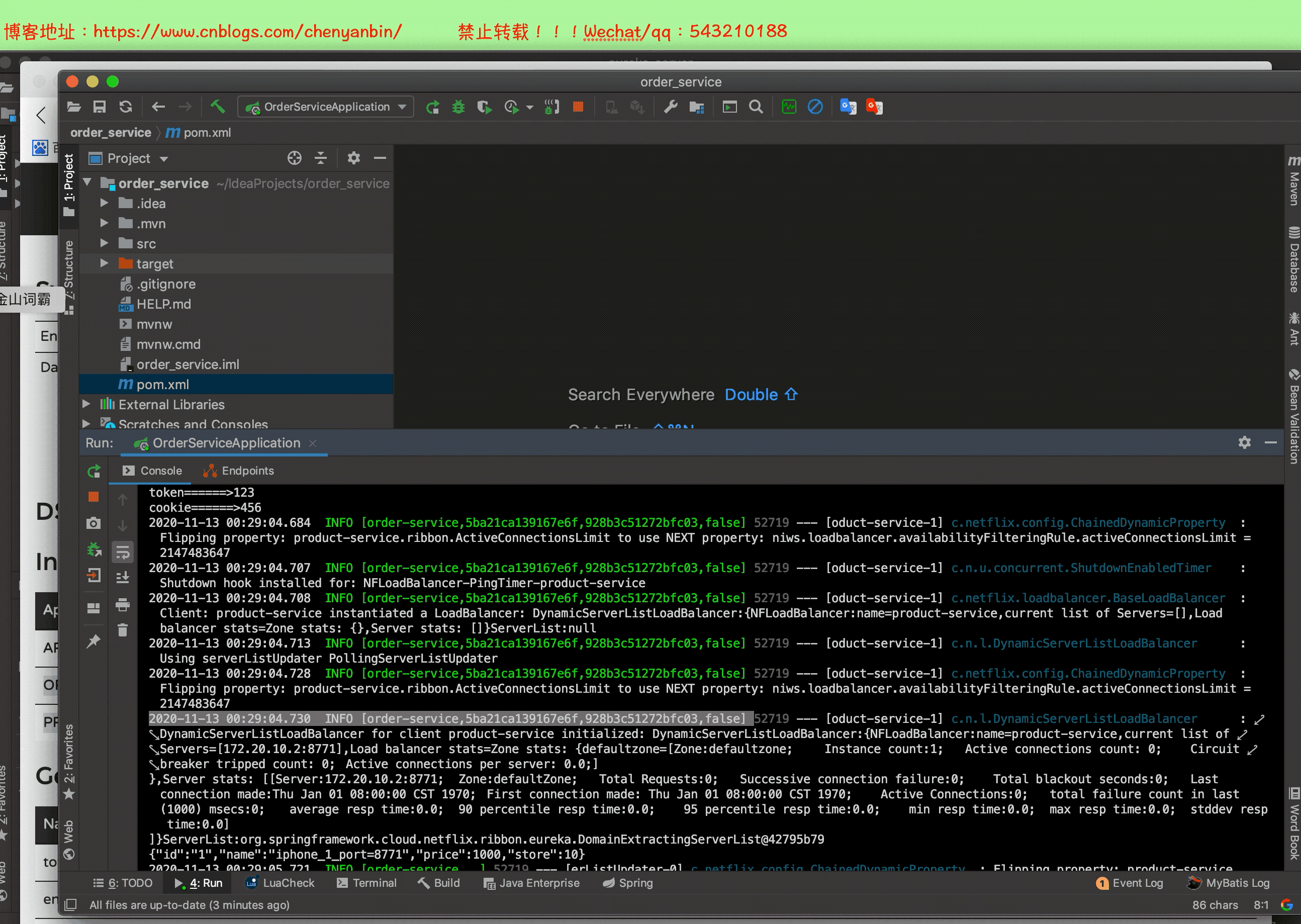
启动整个微服务测试
部署可视化链路追踪Zipkin
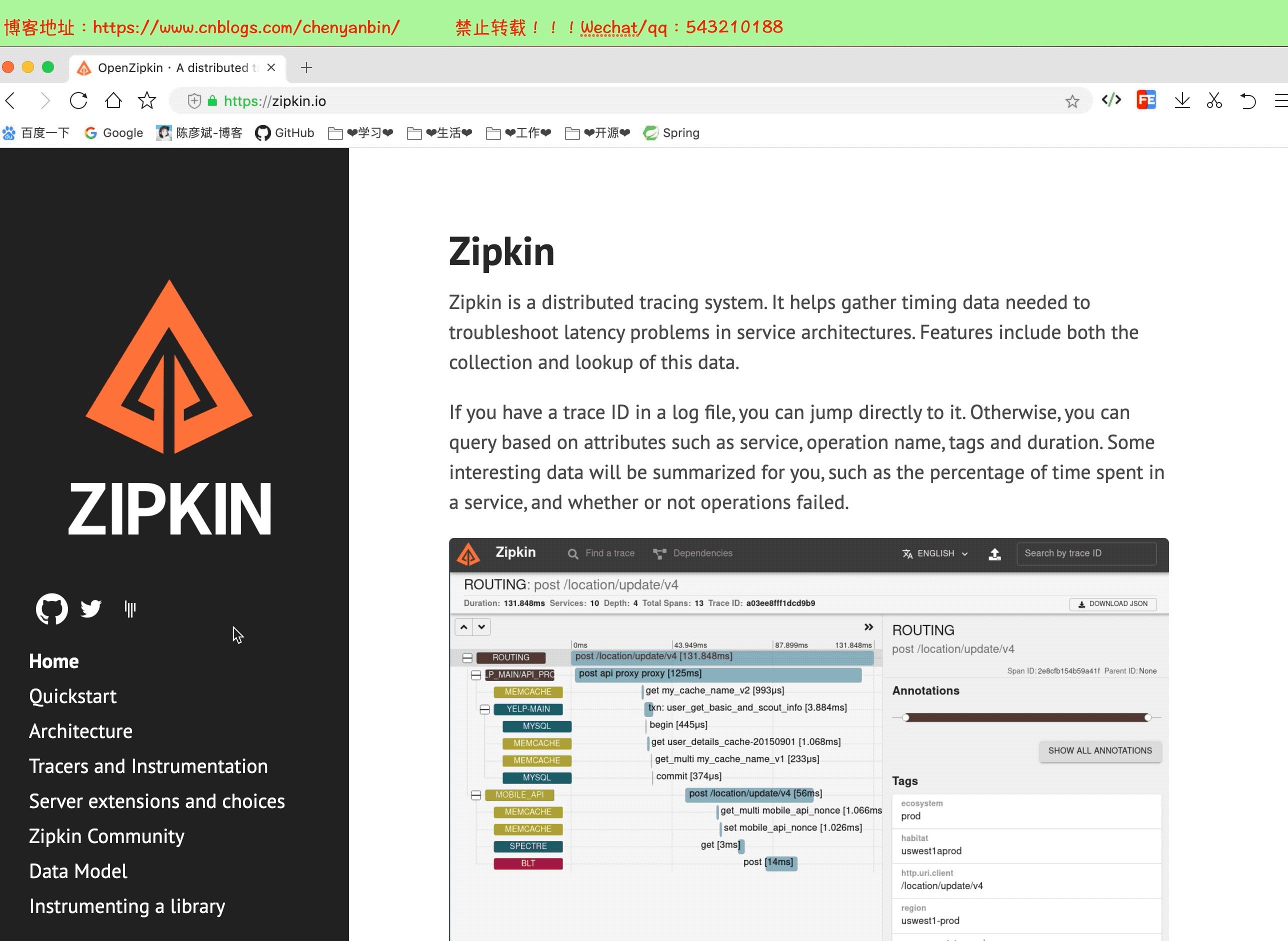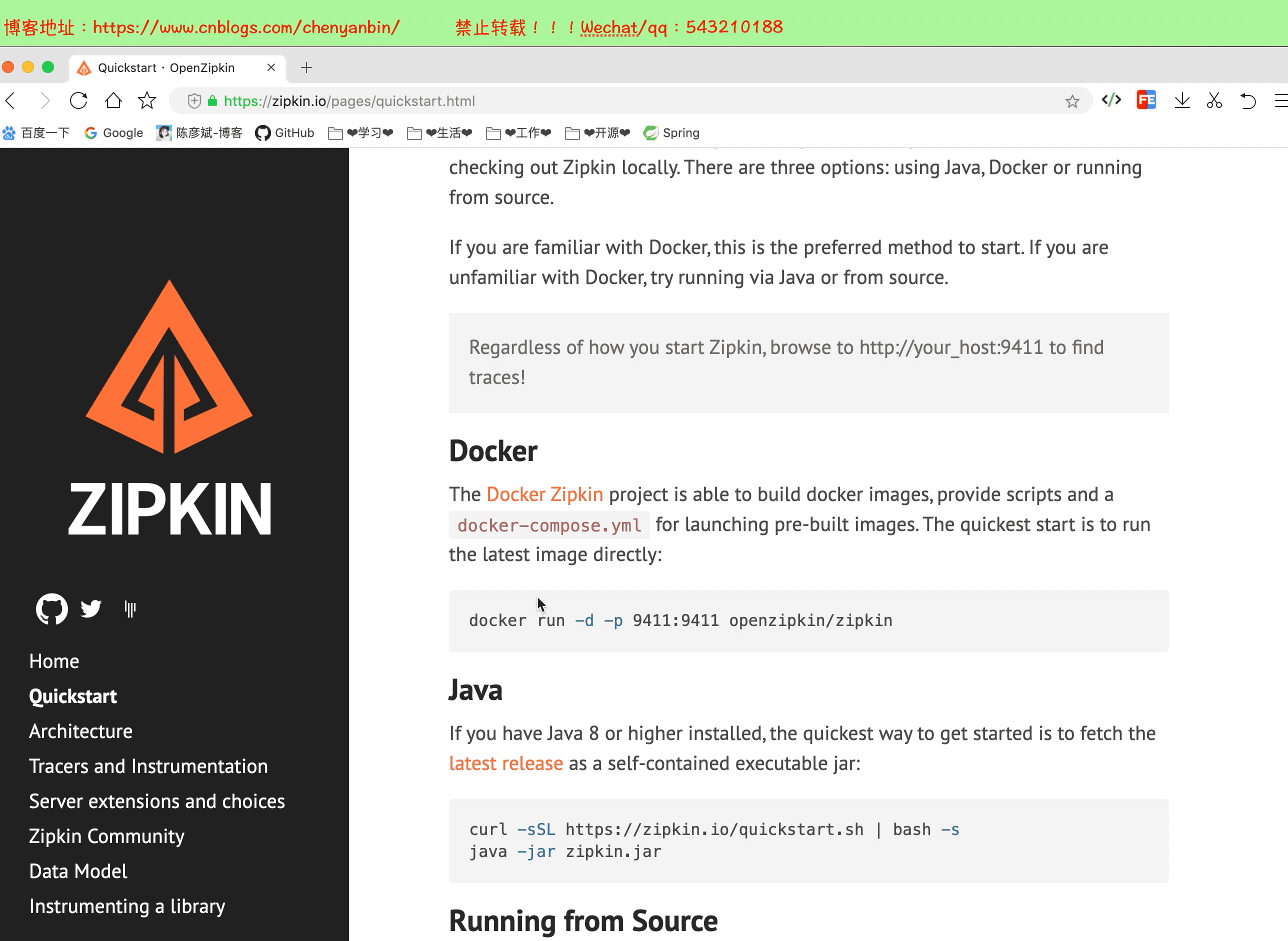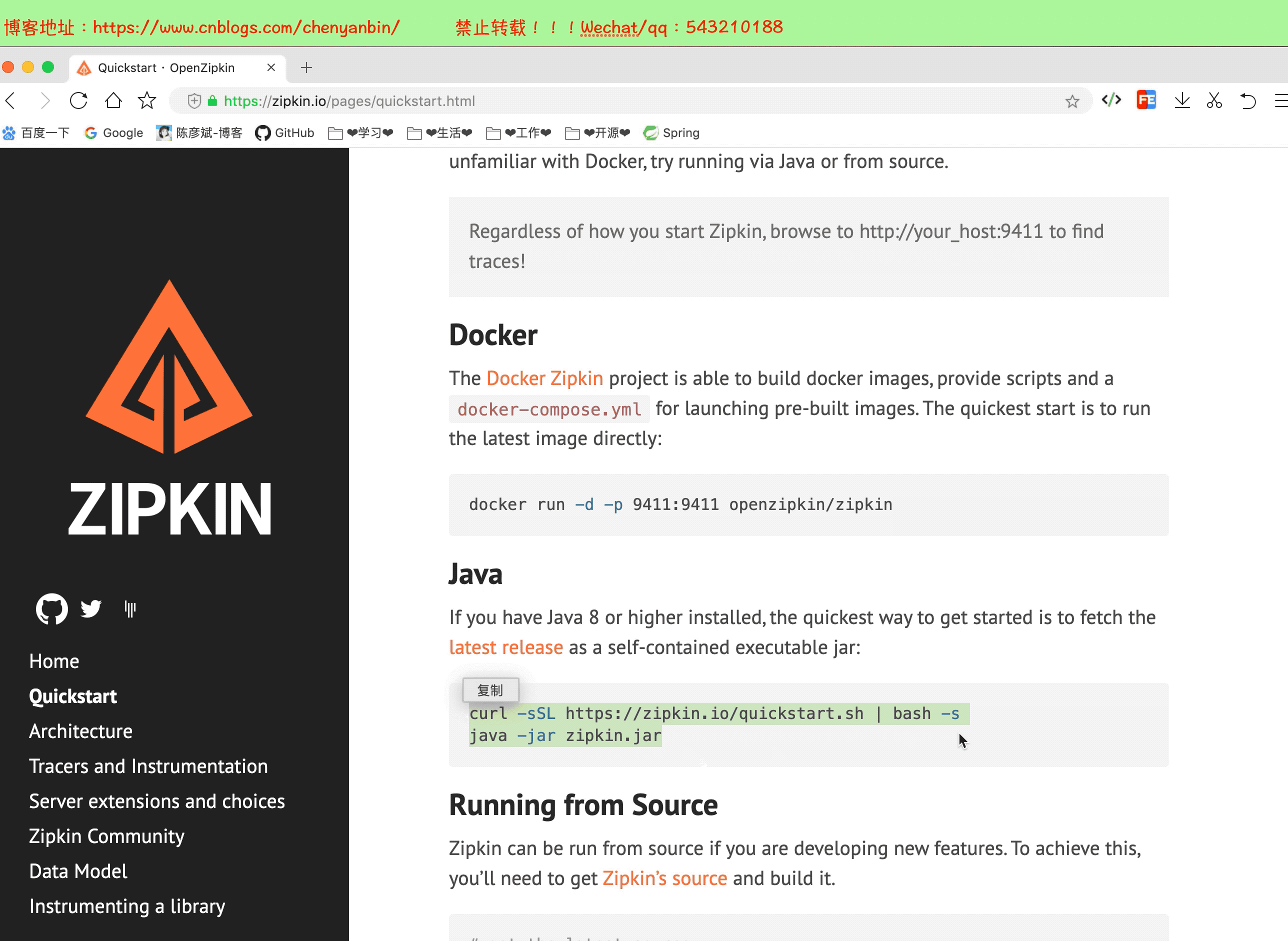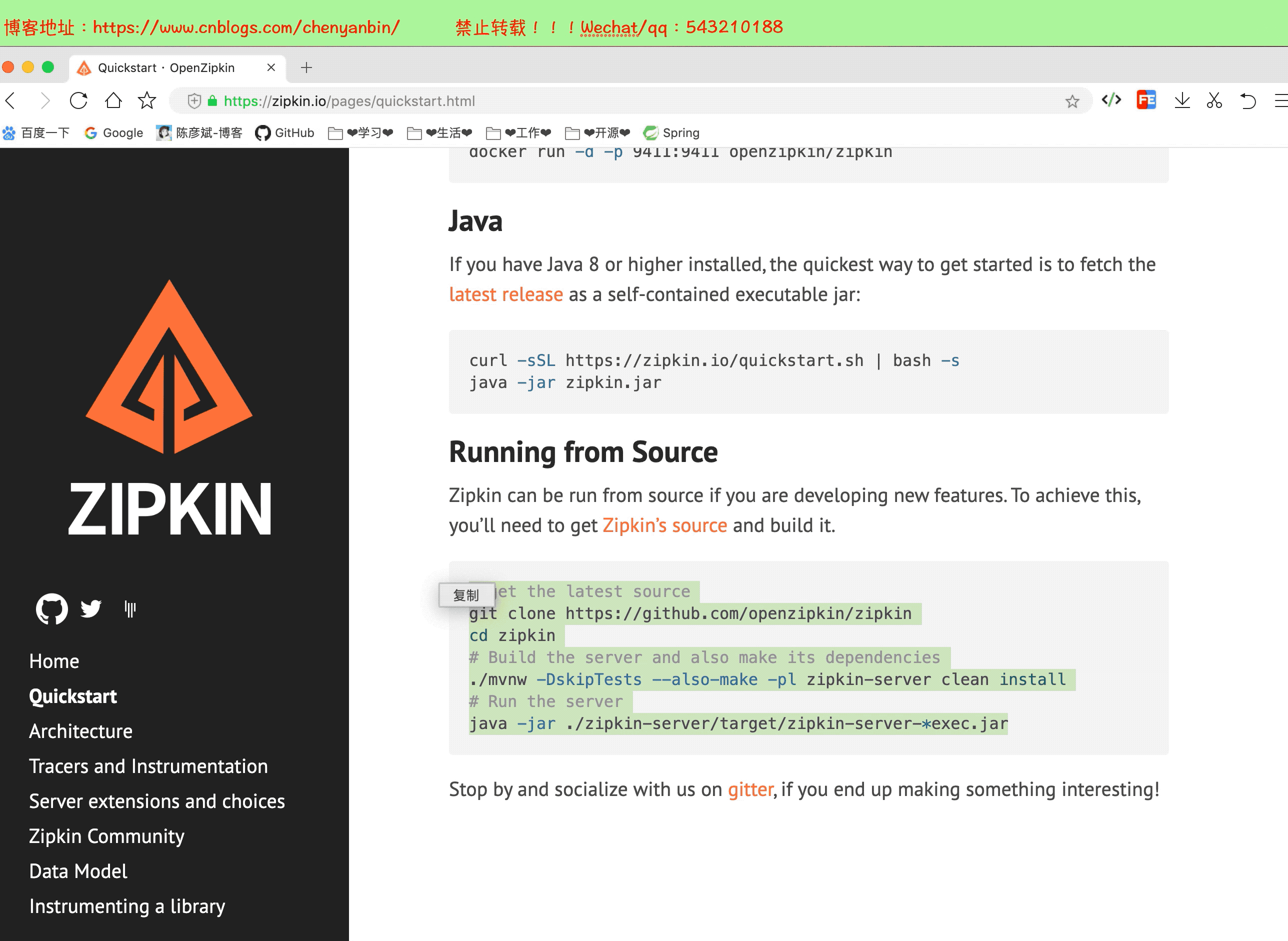
简介
大规模分布式系统的APM工具,基于Google Dapper的基础实现,和Sleuth结合可以提供可视化web界面分析调用链路耗时情况。
官网
部署
这里我使用下载源码的方式
# get the latest source
git clone https://github.com/openzipkin/zipkin
cd zipkin
# Build the server and also make its dependencies
./mvnw -DskipTests --also-make -pl zipkin-server clean install
# Run the server
java -jar ./zipkin-server/target/zipkin-server-*exec.jar
备注
因为种种原因,从github上下载这个源码包,非常慢,可以使用:点我直达
git clone https://gitee.com/mirrors/zipkin.git cd zipkin mvn -DskipTests clean package java -jar ./zipkin-server/target/zipkin-server-*exec.jar
启动
地址:ip:9411
Zpikin+Sleuth整合
添加依赖
涉及到的服务都得加!(我这里是在order-service、product-service加的依赖)
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>

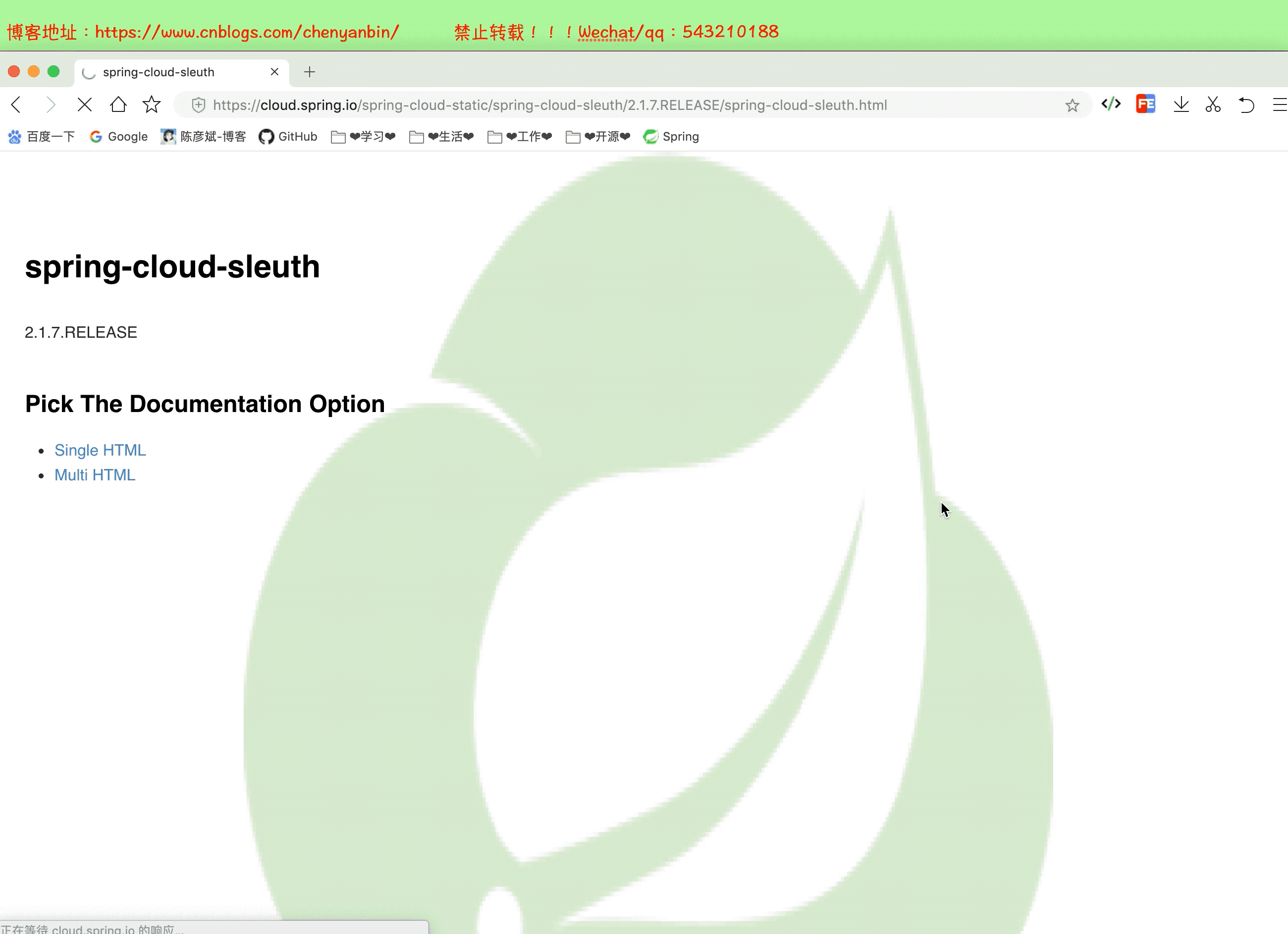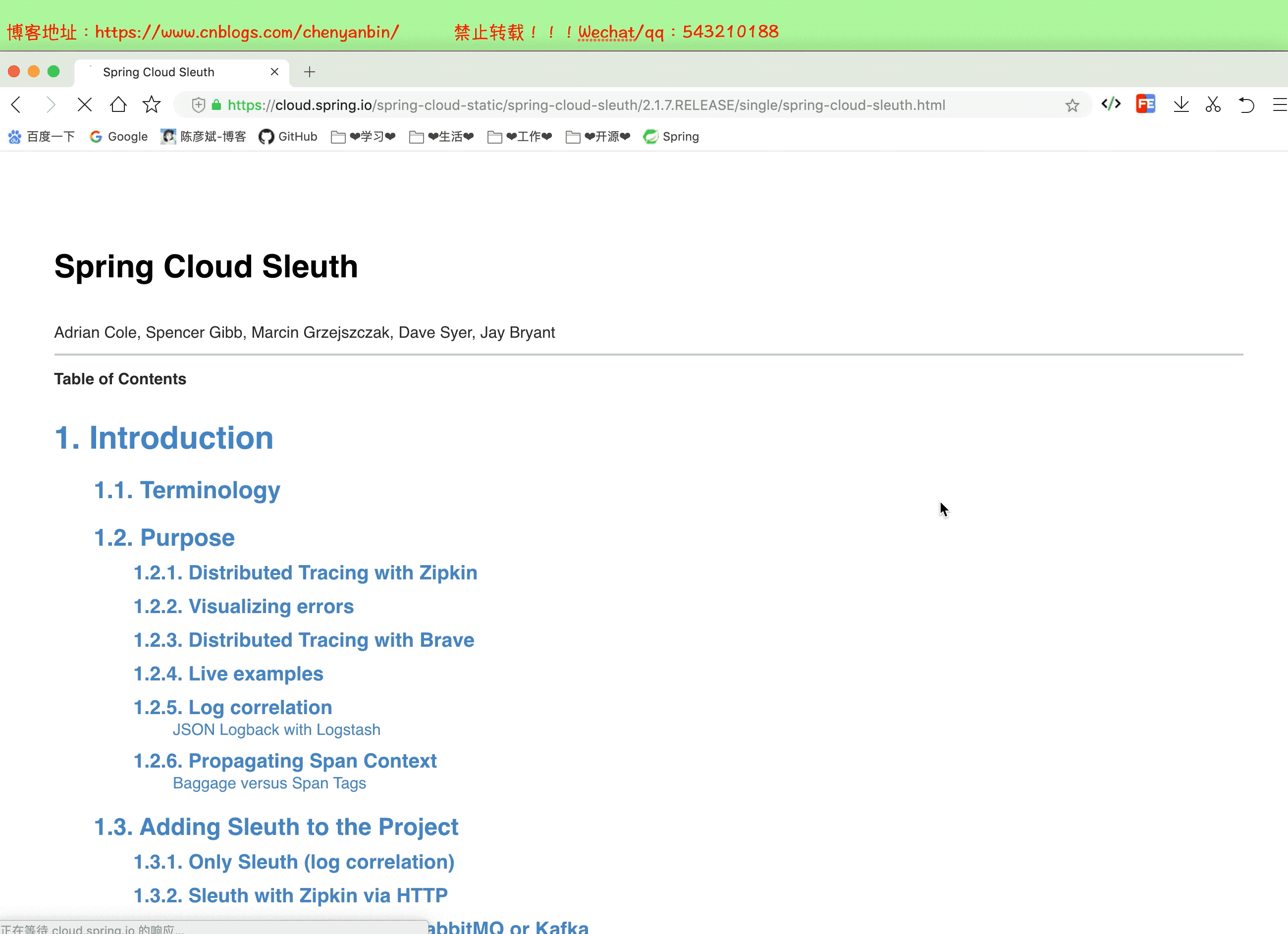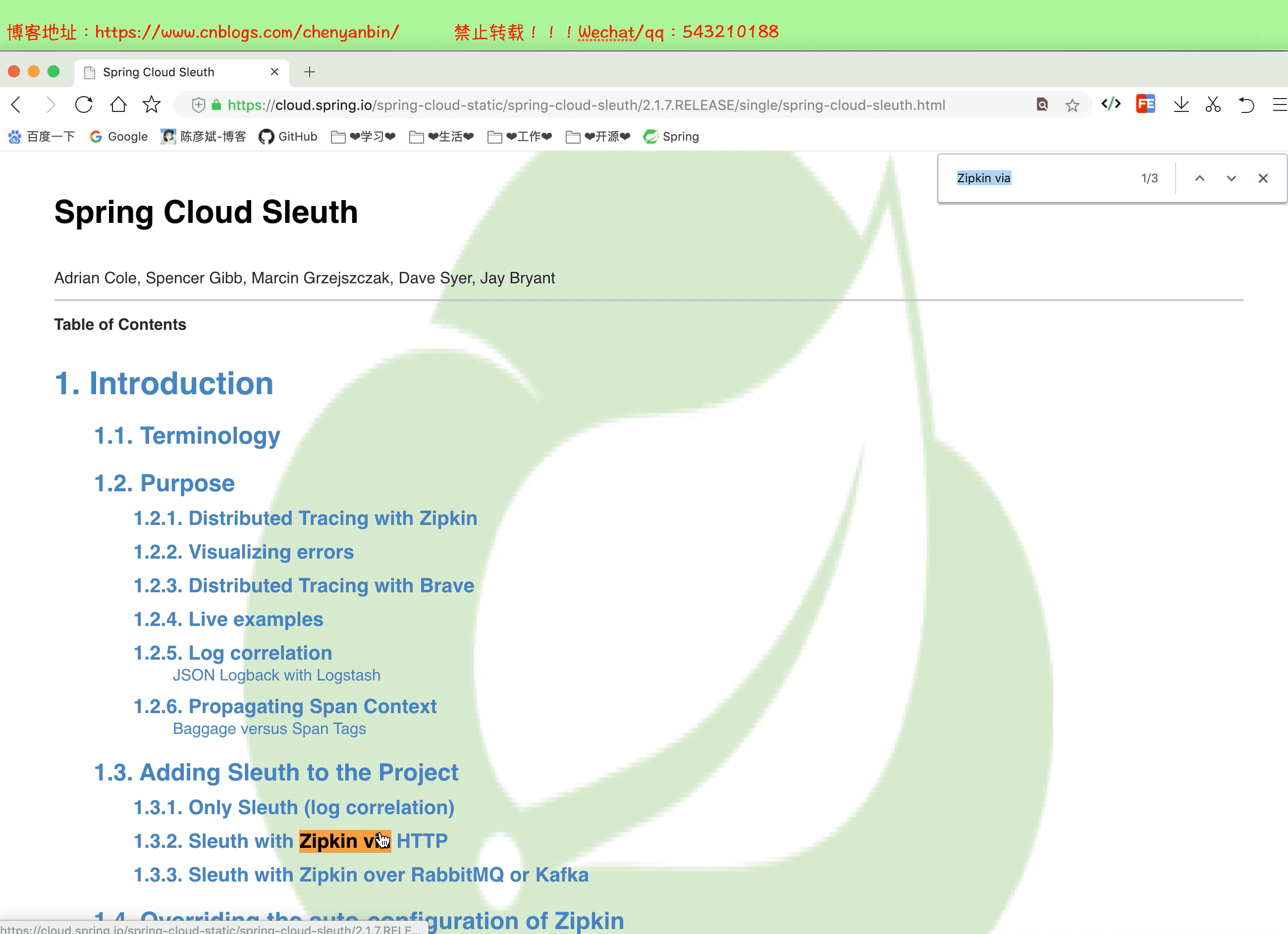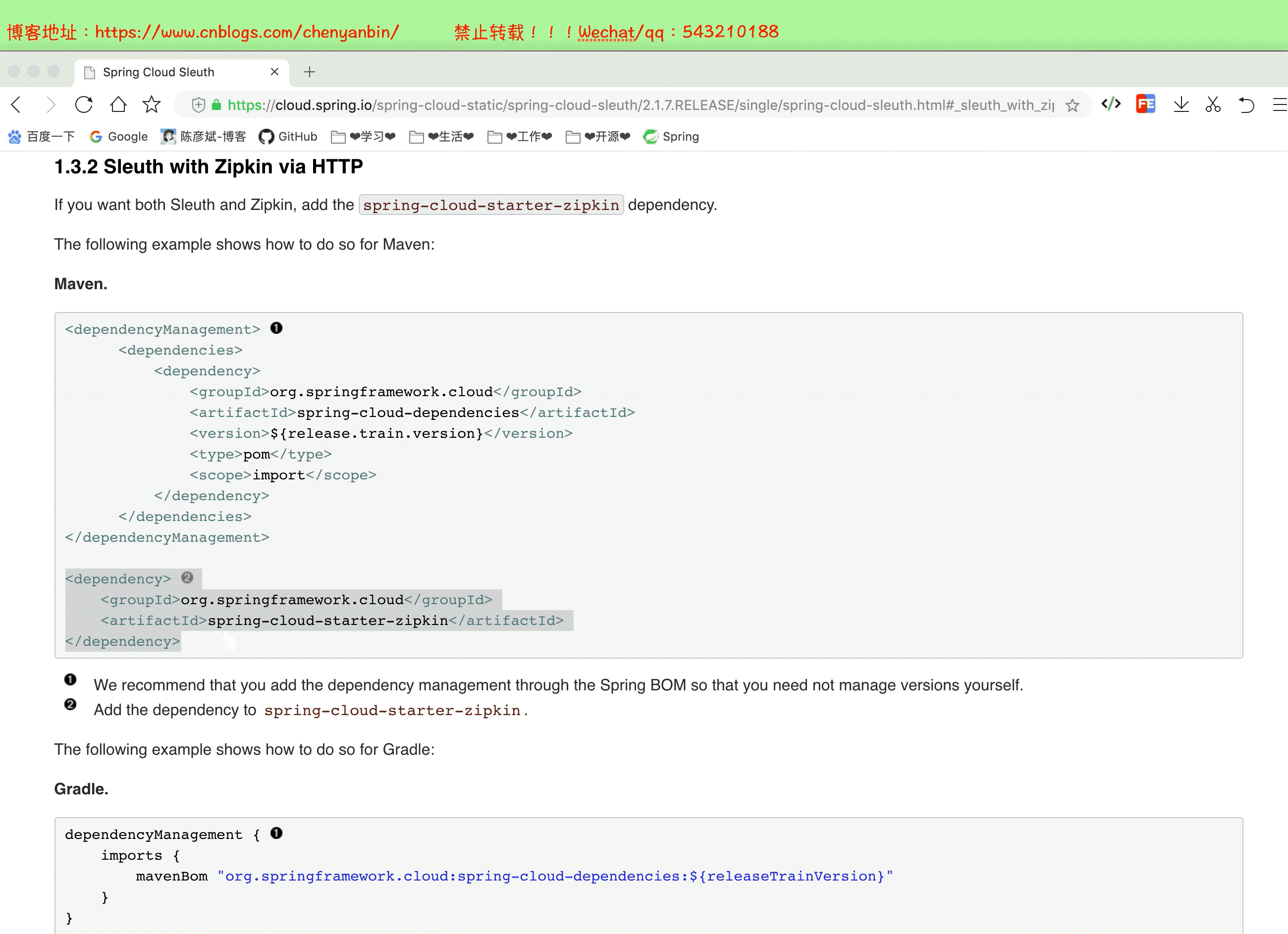
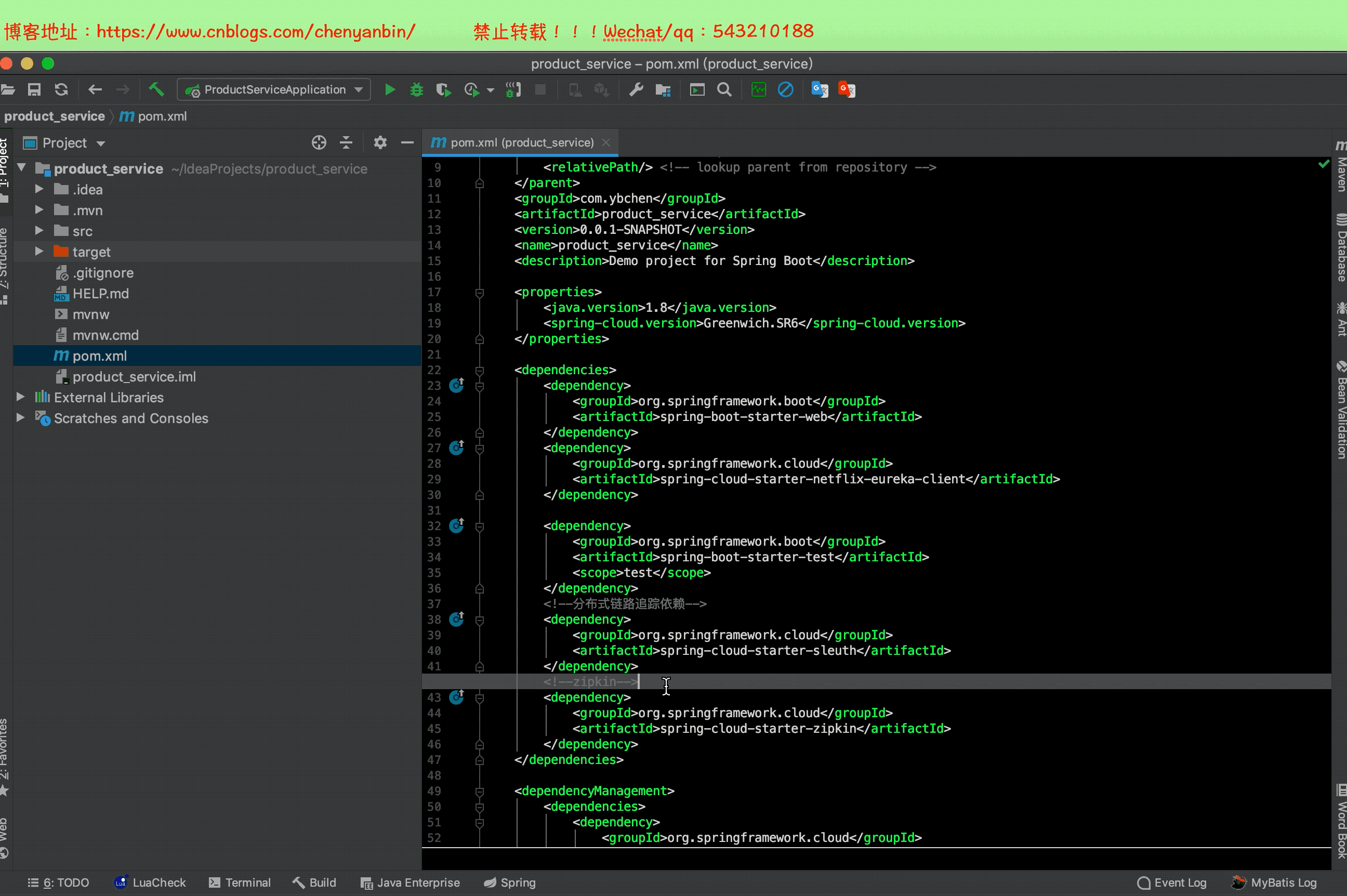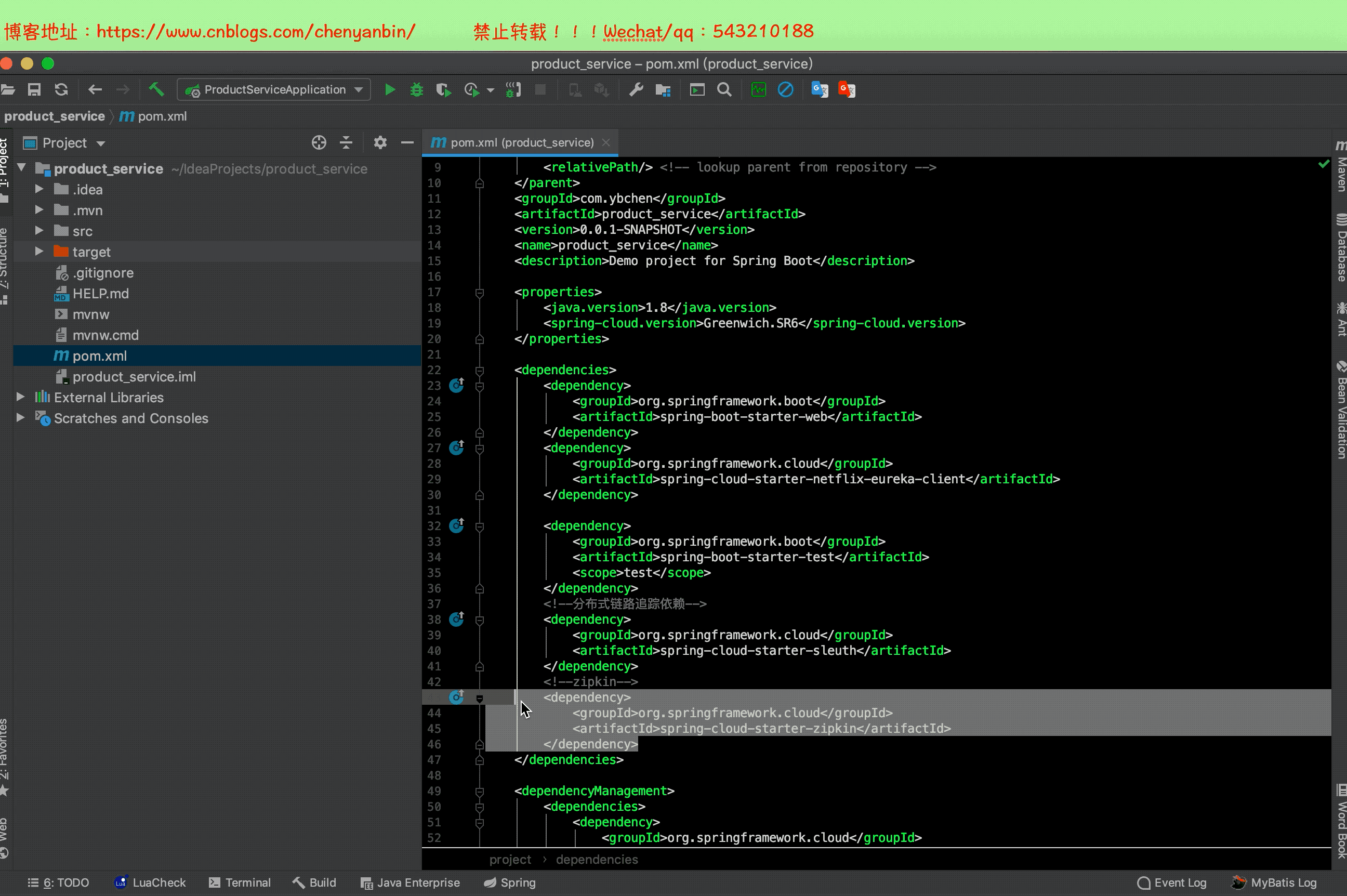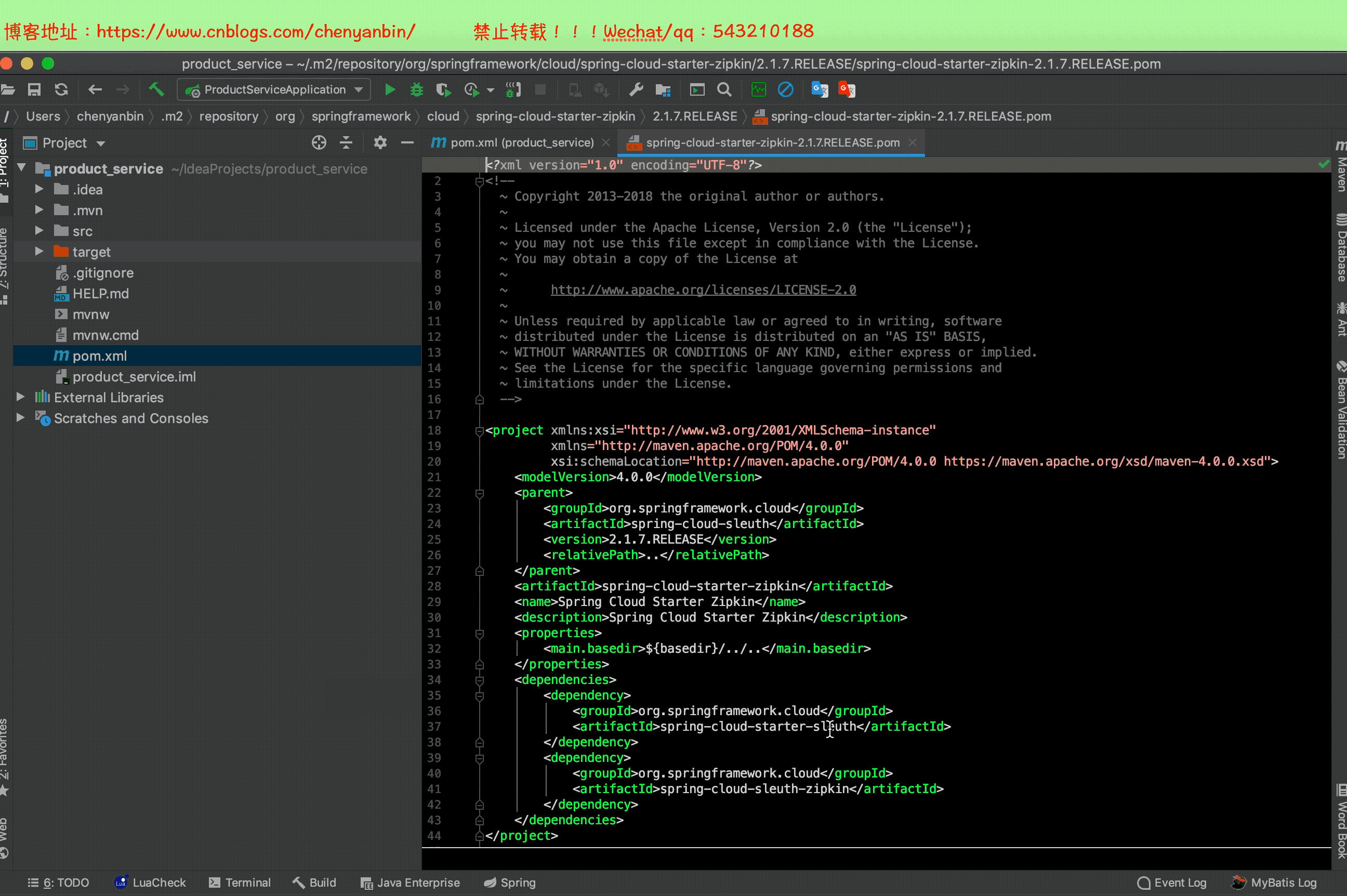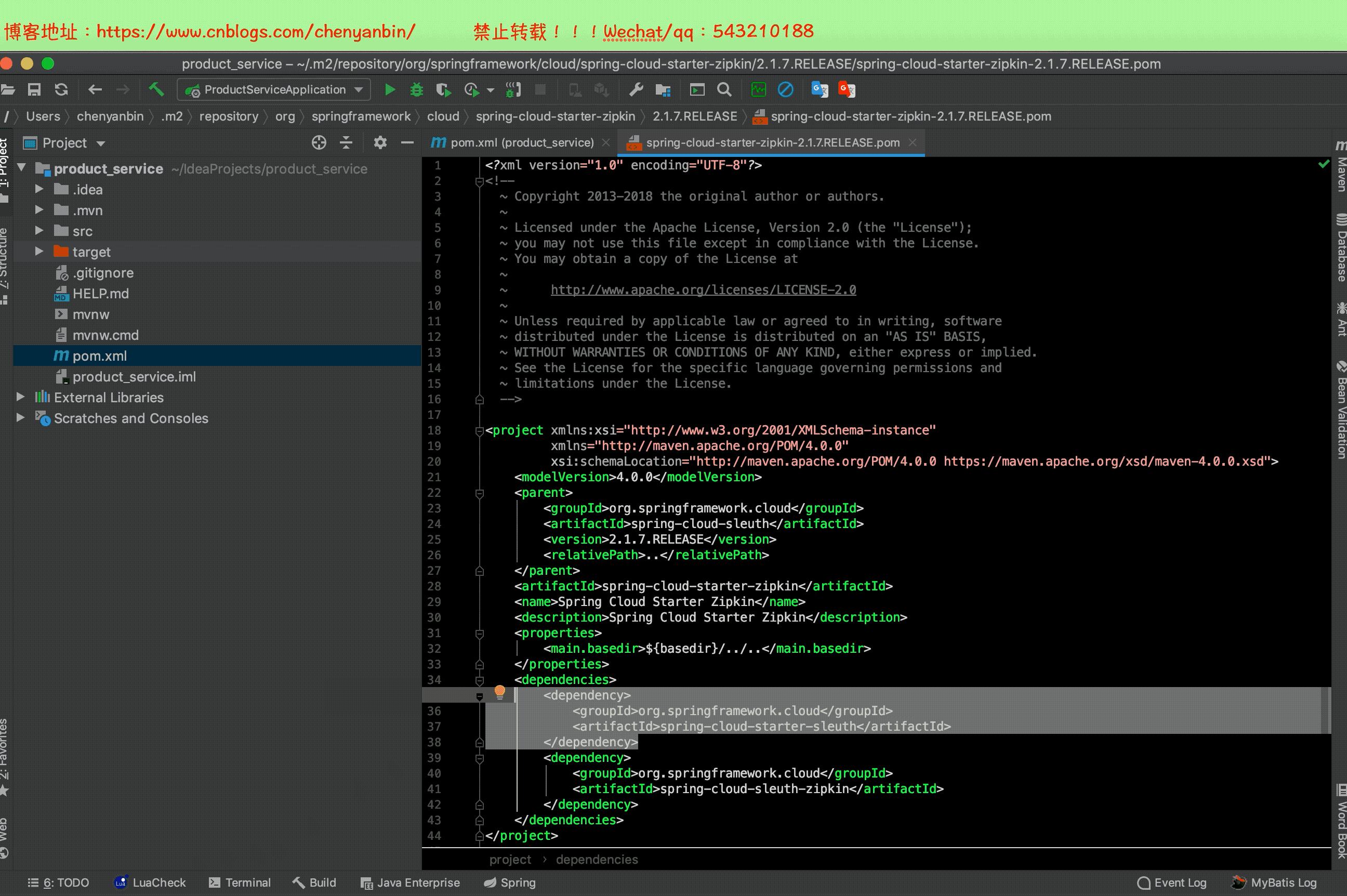
注意
之前加过Sleuth依赖,现在加zipkin依赖,2.x的zipkin已经包含sleuth了,这里可以把之前的sleuth依赖去掉
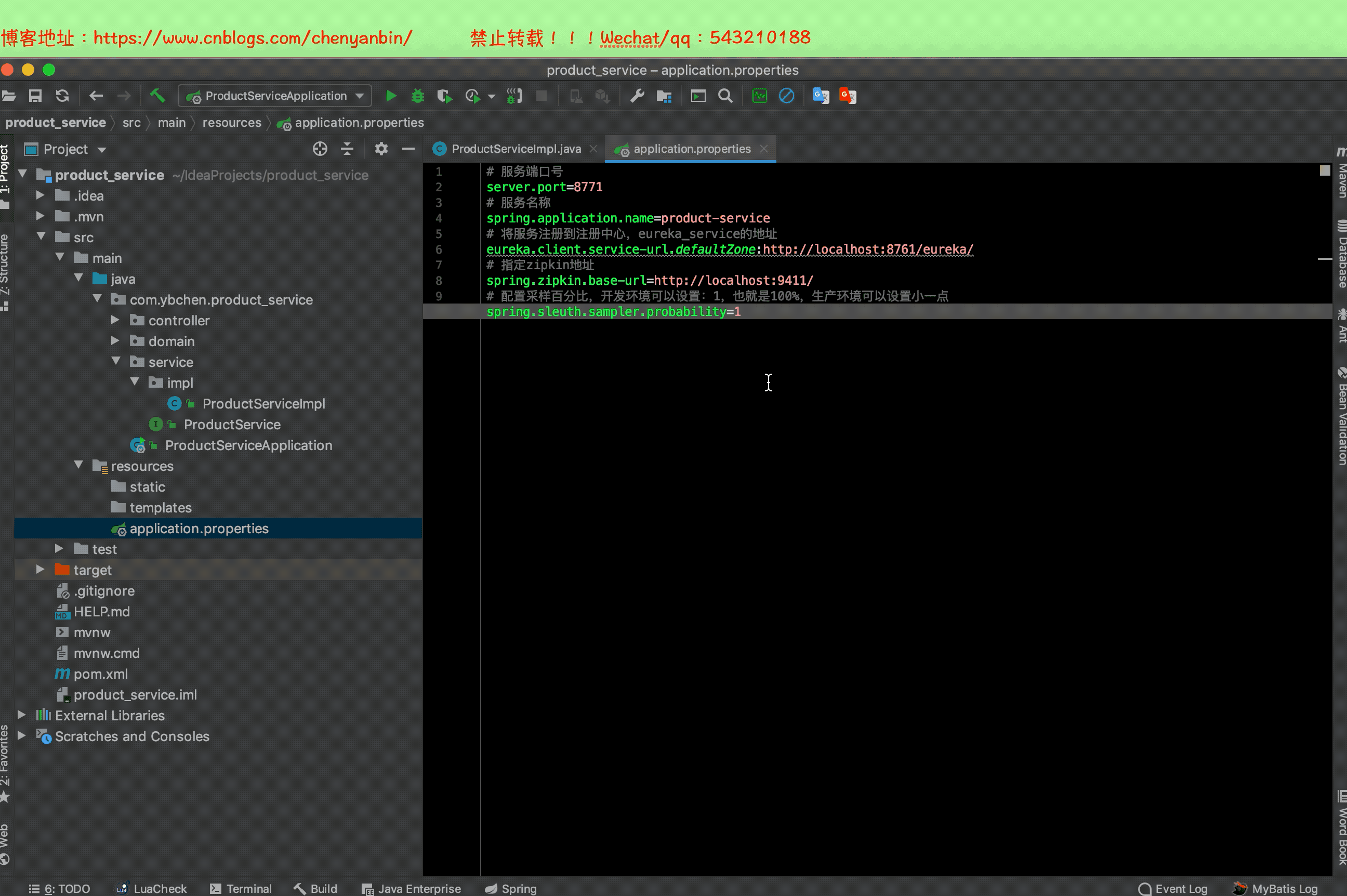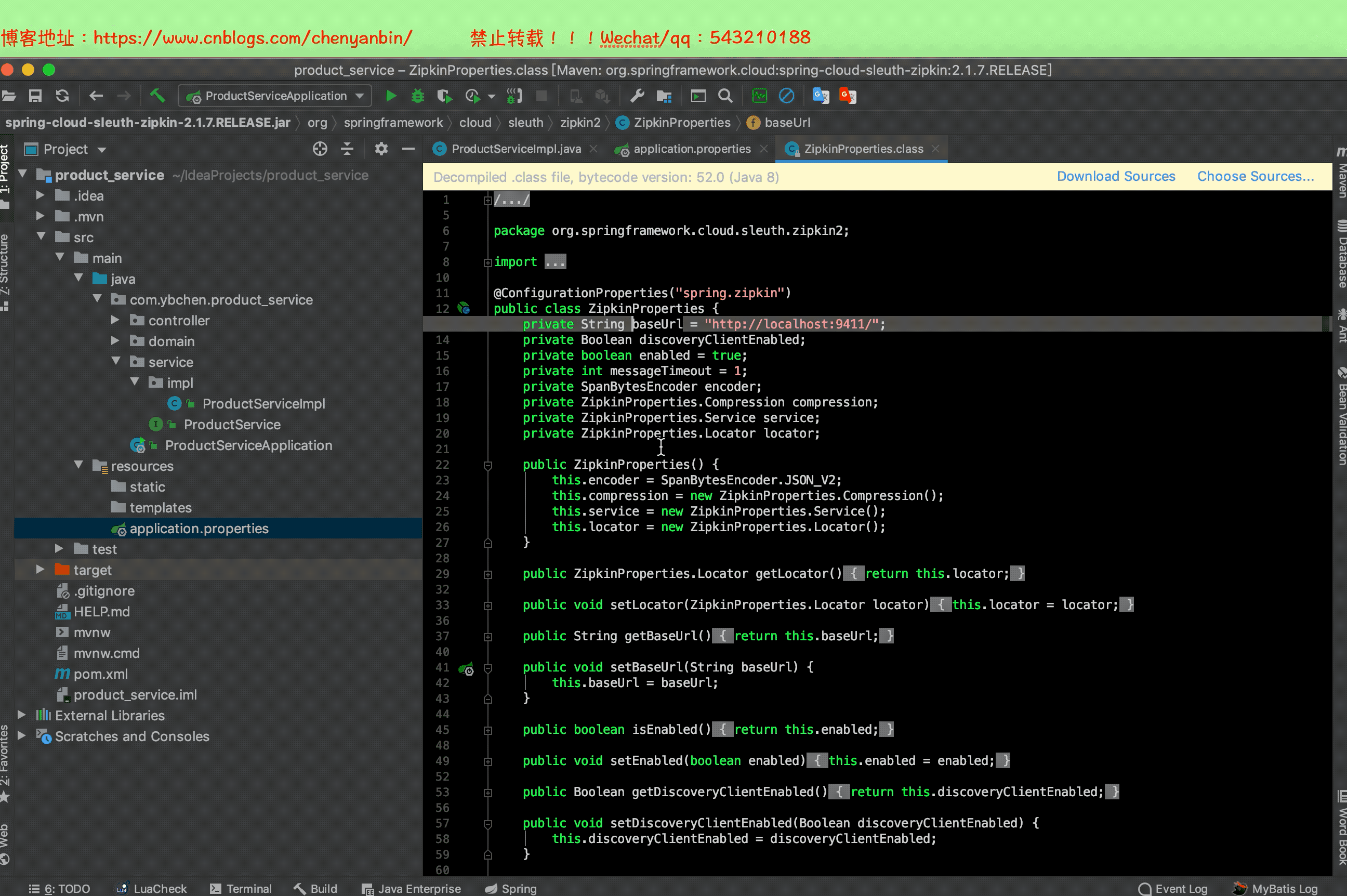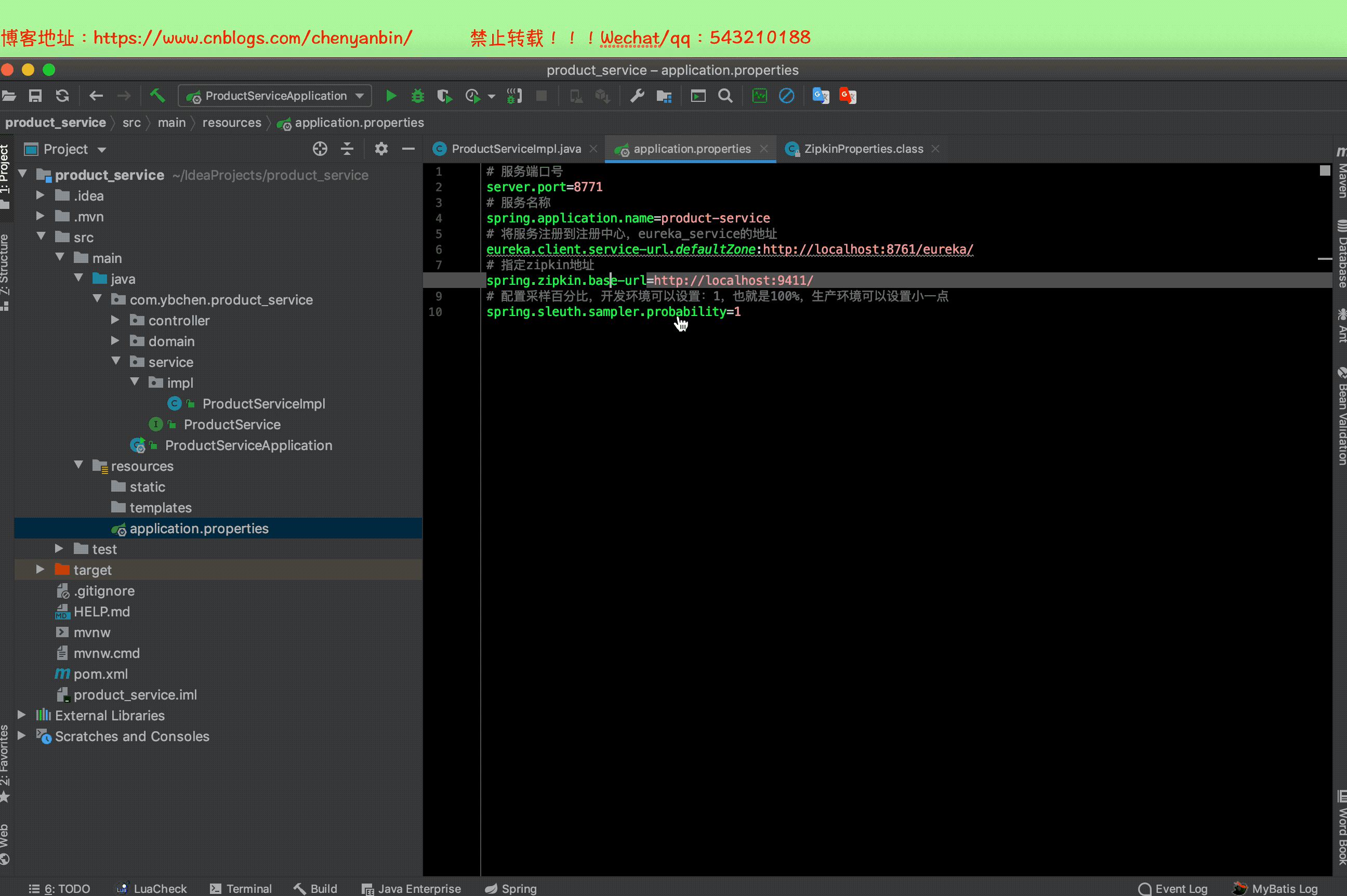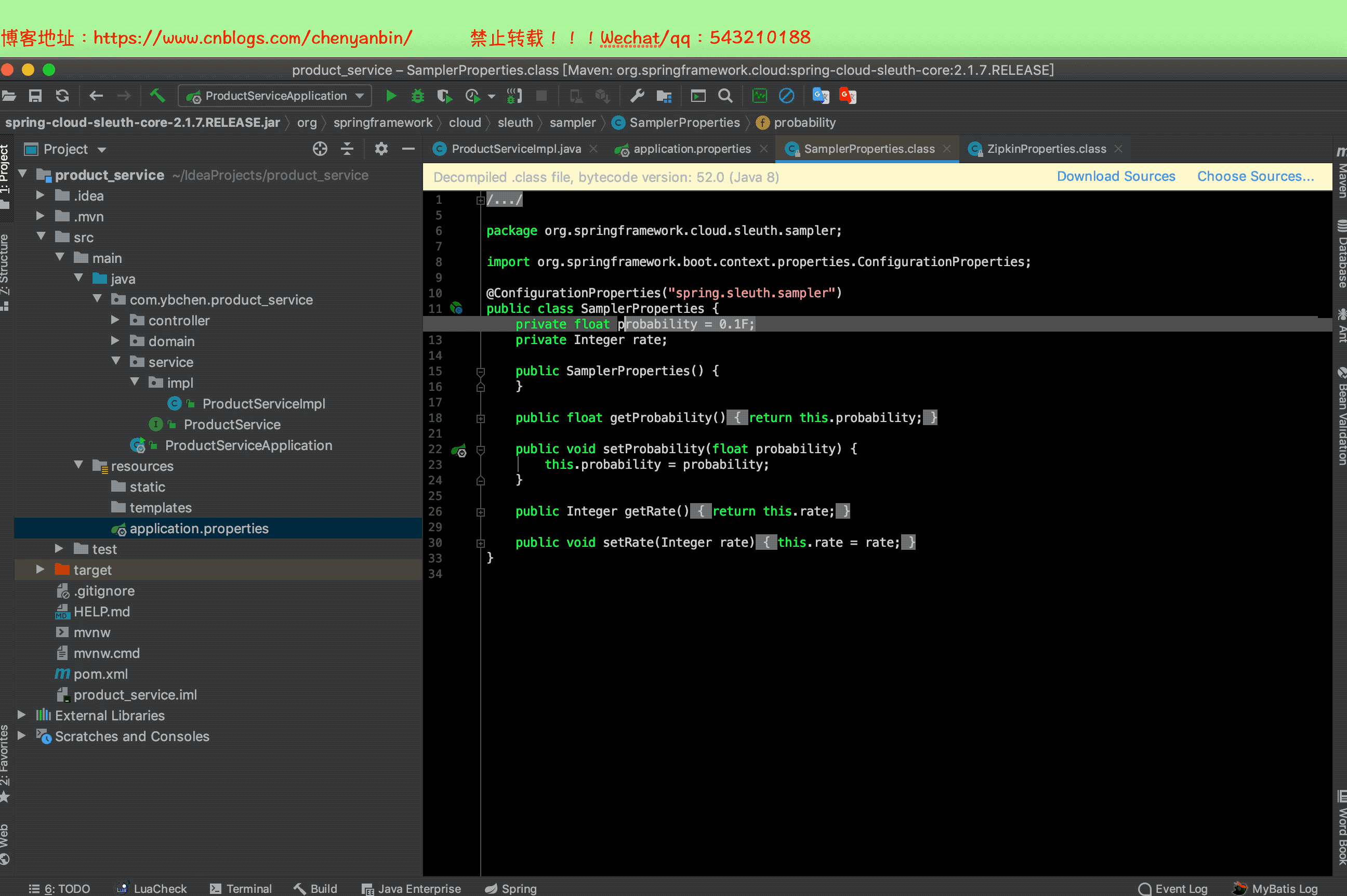
修改配置文件
默认指向的zipkin地址为本机地址:http://localhost:9411/
默认收集百分比为:10%
application.properties
# 指定zipkin地址
spring.zipkin.base-url=http://localhost:9411/
# 配置采样百分比,开发环境可以设置:1,也就是100%,生产环境可以设置小一点
spring.sleuth.sampler.probability=1
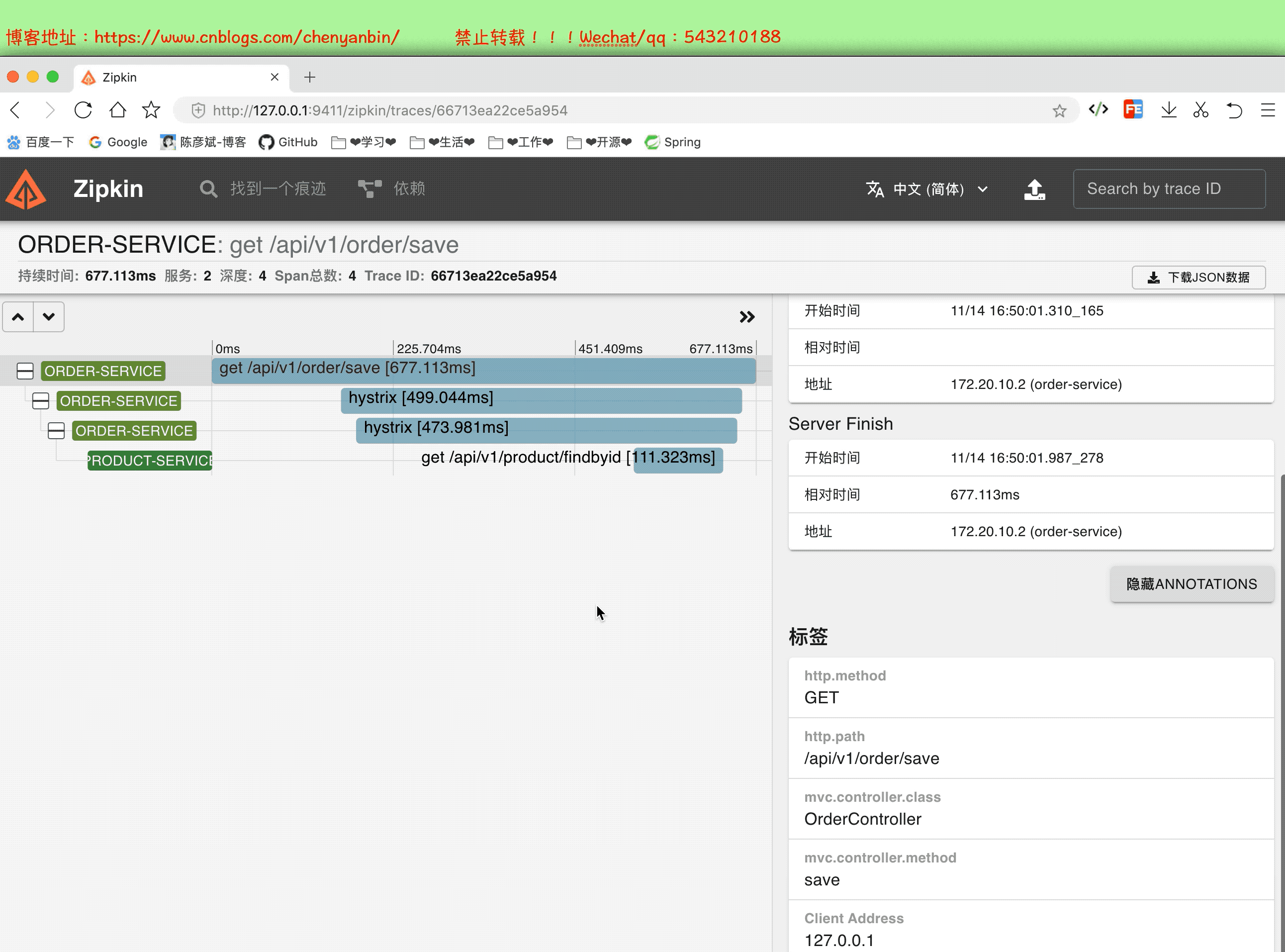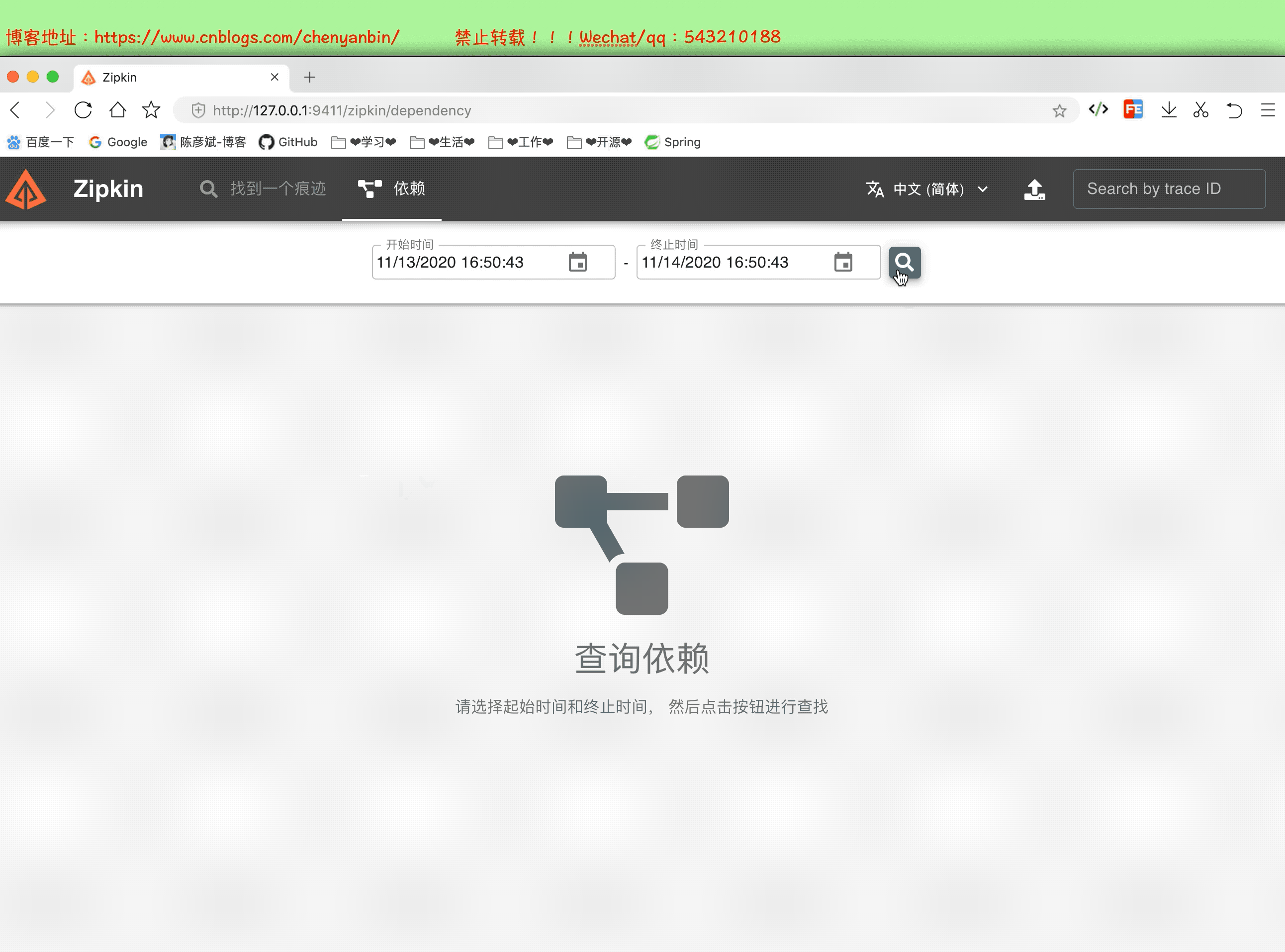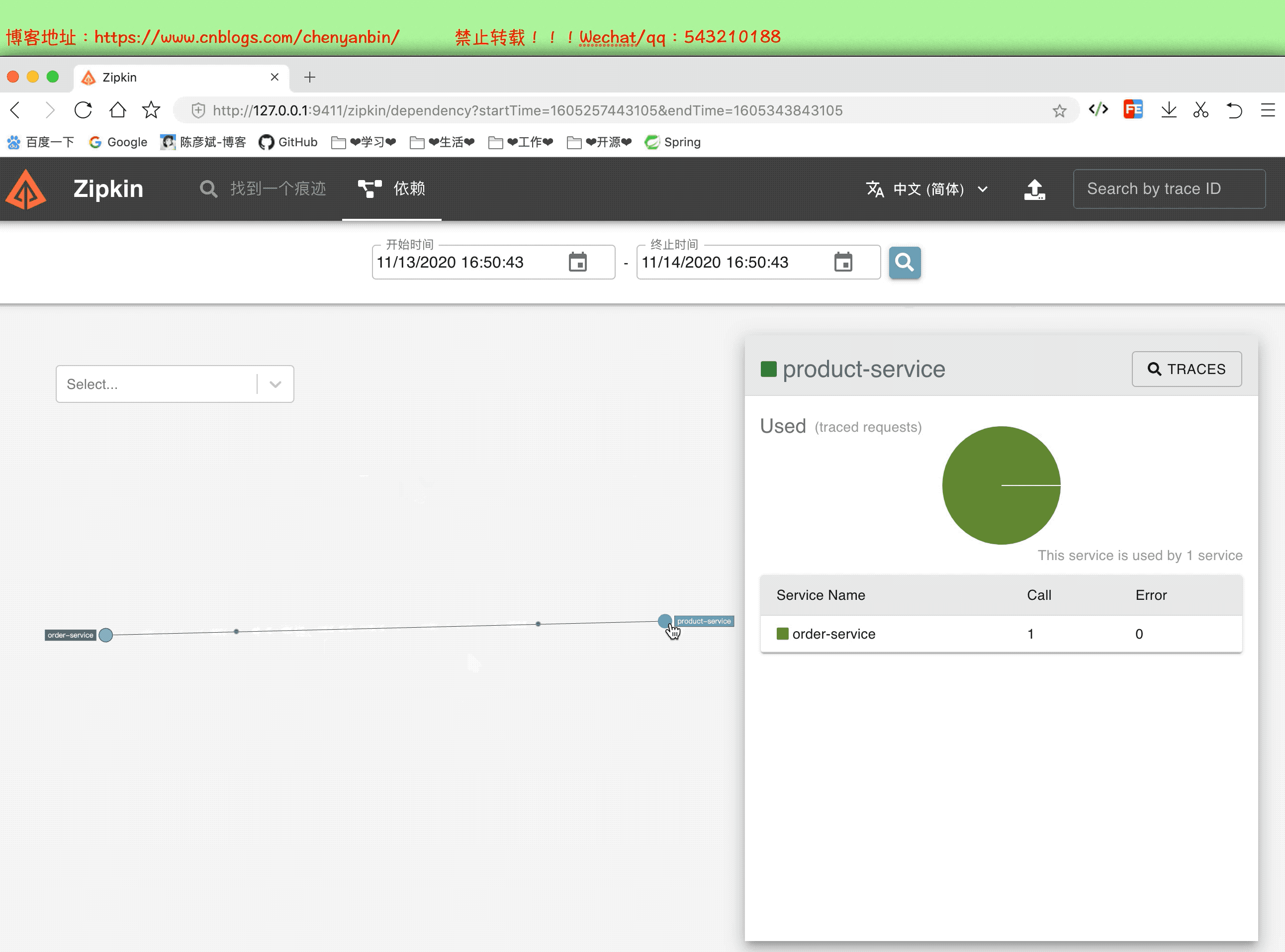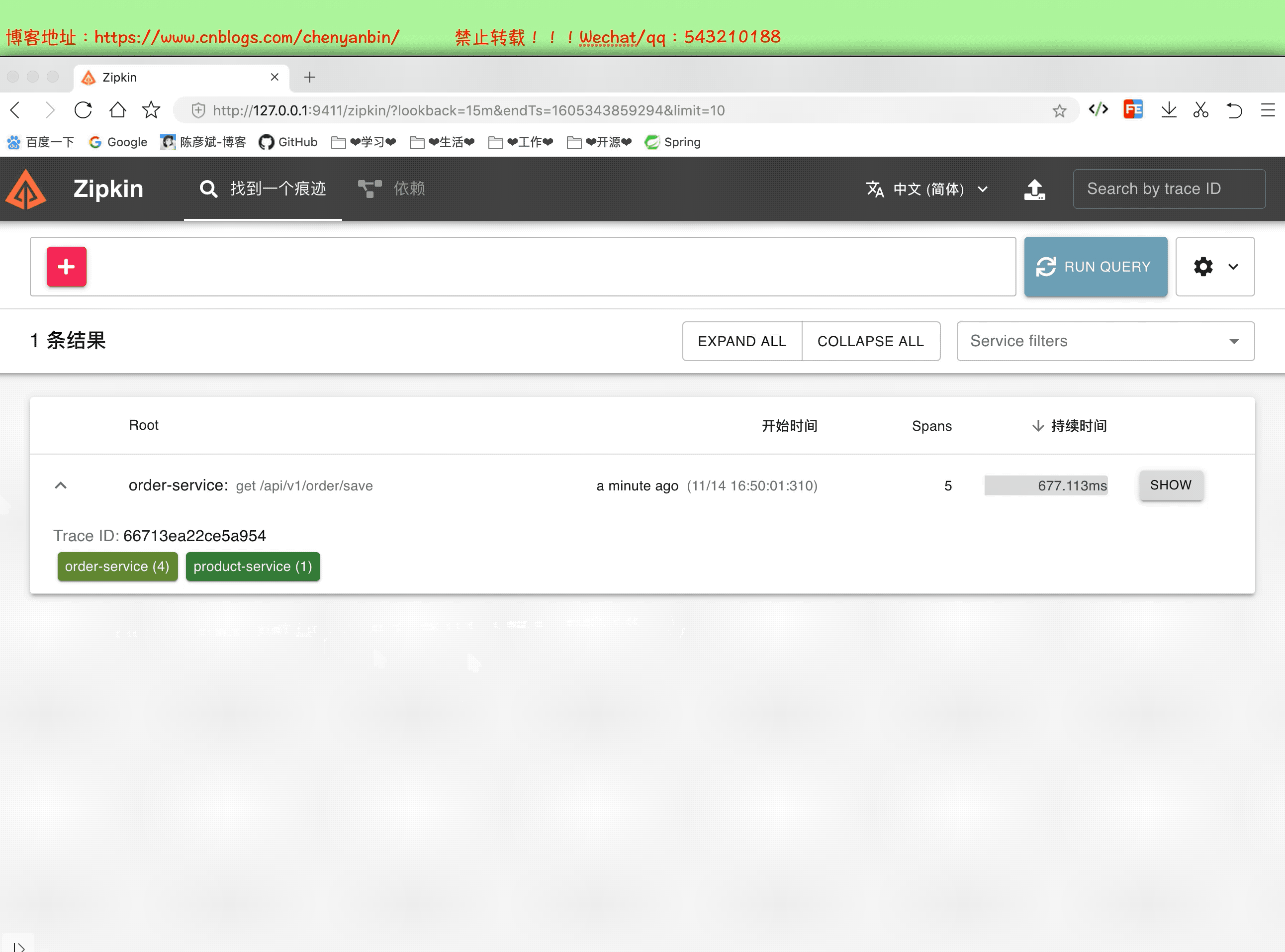
启动并分析数据
通过这个分析,我们可以知道,微服务中那个服务耗时多,可以在这个服务上做性能优化,可以考虑加:缓存、异步、算法等等~
源码下载
好了,今天先到这,只可意会不可言传,自己体会他的好处~
链接: https://pan.baidu.com/s/1c4ZWufjmDgzgAAiOOzRg9A 密码: or12
Spring Cloud 整合分布式链路追踪系统Sleuth和ZipKin实战,分析系统瓶颈的更多相关文章
- Spring Boot + Spring Cloud 构建微服务系统(八):分布式链路追踪(Sleuth、Zipkin)
技术背景 在微服务架构中,随着业务发展,系统拆分导致系统调用链路愈发复杂,一个看似简单的前端请求可能最终需要调用很多次后端服务才能完成,那么当整个请求出现问题时,我们很难得知到底是哪个服务出了问题导致 ...
- 分布式链路追踪(Sleuth、Zipkin)
技术背景 在微服务架构中,随着业务发展,系统拆分导致系统调用链路愈发复杂,一个看似简单的前端请求可能最终需要调用很多次后端服务才能完成,那么当整个请求出现问题时,我们很难得知到底是哪个服务出了问题导致 ...
- spring cloud链路追踪组件sleuth和zipkin
spring cloud链路追踪组件sleuth 主要作用就是日志埋点 操作方法 1.增加依赖 <dependency> <groupId& ...
- Spring Boot + Spring Cloud 实现权限管理系统 后端篇(二十二):链路追踪(Sleuth、Zipkin)
在线演示 演示地址:http://139.196.87.48:9002/kitty 用户名:admin 密码:admin 技术背景 在微服务架构中,随着业务发展,系统拆分导致系统调用链路愈发复杂,一个 ...
- spring cloud 2.x版本 Sleuth+Zipkin分布式链路追踪
前言 本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka ...
- 分布式链路追踪之Spring Cloud Sleuth+Zipkin最全教程!
大家好,我是不才陈某~ 这是<Spring Cloud 进阶>第九篇文章,往期文章如下: 五十五张图告诉你微服务的灵魂摆渡者Nacos究竟有多强? openFeign夺命连环9问,这谁受得 ...
- 分布式链路追踪系统Sleuth和ZipKin
1.微服务下的链路追踪讲解和重要性 简介:讲解什么是分布式链路追踪系统,及使用好处 进行日志埋点,各微服务追踪. 2.SpringCloud的链路追踪组件Sleuth 1.官方文档 http://cl ...
- 基于zipkin分布式链路追踪系统预研第一篇
本文为博主原创文章,未经博主允许不得转载. 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infras ...
- zipkin分布式链路追踪系统
基于zipkin分布式链路追踪系统预研第一篇 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Inf ...
随机推荐
- tslib-1.4移植(转)
转自:http://blog.163.com/zhuandi_h/blog/static/180270288201222310291262/ 环境:host:Ubuntu11.10target:Oma ...
- 第一期chrome浏览器的小技巧------《提高搜索效率》
!!! 这次的技巧是:利用chrome提供的设置 提高你的搜索效率 !!! 我们经常遇到问题,搜索的时候很不方便 比如你在百度上搜索一个东西的时候正好没有搜到,那么你想找到这个东西的话,很明显要到其他 ...
- STM32时钟和定时器
时钟源 STM32包含了5个时钟源,分别为HSI.HSE.LSI.LSE.PLL. HSI是高速内部时钟.RC振荡器,频率为8MHz: HSE是高速外部时钟,即晶振,可接石英/陶瓷谐振器或接外部时钟源 ...
- windows搭建SVN服务MD版
windows搭建SVN服务MD 1下载TortoiseSVN 官网下载 根据自己系统环境选择适合的版本 2 安装TortoiseSVN 双击运行程序 出现第一个小坑 原来是你的系统没有打 kb299 ...
- 在Linux上成功启动Jenkins却无法访问的问题
本鸟最近打算学习Jenkins,正准备在Linux上面鼓捣一番,,却没想被入门级别问题当头一棒 下载完jenkins.war,使用java -jar命令在8088端口开启服务:java -jar je ...
- 联赛模拟测试22 B. 分组配对 倍增+二分
题目描述 分析 首先,容易发现一个小组内的最优配对方式(能得到最大综合实力的方式) 一定是实力值最大的男生和最大的女生配对,次大的和次大的配对,以此类推. 但是每次新插入一个值时,需要用 \(nlog ...
- Lombda表达式(四)
/* * 自定义函数式接口: * 1.声明一个接口,只能包含一个抽象方法 * 2.给这个接口加@FunctionalInterface */ public class Test { public st ...
- (Pytorch)涉及的常见操作
涉及一些pytorch的API内容在此进行整理 损失函数:Binary-Cross-Entropy loss criterion = nn.BCECriterion() 创建一个标准来度量目标和输出之 ...
- Linux文件操作常用命令
一.一些文件操作命令. 1.cd /home 进入"home目录" 2.cd ../ 返回上一级目录 3.cd - 返回上次所在的目录 4.pwd 显示工程路径 5.ll 显示 ...
- Mysql优化建议
Mysql优化建议: (1)CPU要更快,而不是更多.因为mysql不支持多个处理器并发处理一条sql,所以正常情况下不需要考虑更多的CPU.当然,你的系统中的对mysql的并发很高时,多核可以解决一 ...