flink ---- 系统内部消息传递的exactly once语义
At Most once,At Least once和Exactly once
在分布式系统中,组成系统的各个计算机是独立的。这些计算机有可能fail。
一个sender发送一条message到receiver。根据receiver出现fail时sender如何处理fail,可以将message delivery分为三种语义:
At Most once: 对于一条message,receiver最多收到一次(0次或1次).
可以达成At Most Once的策略:
sender把message发送给receiver.无论receiver是否收到message,sender都不再重发message.
At Least once: 对于一条message,receiver最少收到一次(1次及以上).
可以达成At Least Once的策略:
sender把message发送给receiver.当receiver在规定时间内没有回复ACK或回复了error信息,那么sender重发这条message给receiver,直到sender收到receiver的ACK.
Exactly once: 对于一条message,receiver确保只收到一次
Flink的Exactly once模式
Flink实现Exactly once的策略: Flink会持续地对整个系统做snapshot,然后把global state(根据config文件设定)储存到master node或HDFS.当系统出现failure,Flink会停止数据处理,然后把系统恢复到最近的一次checkpoint.
什么是分布式系统的global state?
分布式系统由空间上分立的process和连接这些process的channel组成.
空间上分立的含义是,这些process不共享memory,而是通过在communication channel上进行的message pass来异步交流.
分布式系统的global state就是所有process,channel的local state的集合.
process的local state取决于the state of local memory and the history of its activity.
channel的local state是上游process发送进channel的message集减去下游process从channel接收的message的差集.
什么是一致性global state?

假设有两个银行账户A,B.A中初始有600美元,B中初始有200美元. SA, SB, CAB, CBA由A和B分别记录,组成了global state.
在t0时刻,A向B转账50美元;在t1时刻,B向A转账80美元.
如果SA, SB记录于(t0, t1), CAB, CBA记录于(t1, t2),那么global state = 550+200+50+80 = 880,比真实值多了$80. 这就是不一致性global state.
如果 SA, SB, CAB, CBA同属于一个时间区间,那么得到的global state就是一致性的.
Snapshot算法获得一致性global state的难点是什么?
分布式系统没有共享内存(globally shared memory)和全局时钟(global clock).
如果分布式系统有共享内存,那么可以从共享内存中直接获取整个分布式系统的snapshot,无需分别获得各个process,channel的local state再组合成global state.
如果分布式系统有global clock,那么所有的process能在同一时刻各自记录local state,这样就保证了state的一致性.
获得一致性global state的算法 ---- Chandy-Lamport算法
精髓:该算法在普通message中插入了control message – marker
前提:
1) message的传输可能有delay,但一定会到达
2) 每两个process之间都有一条communication path(可能由多条channel组成)
3) Channel是单向的FIFO
描述:
Marker sending rule for process Pi
(1) Process Pi 记录自身state
(2) Pi在记录自身state后,发送下一条message前,Pi向自己所有的outgoing channel发送marker
Marker receiving rule for process Pj on receiving a marker along channel C
如果Pj第一次接收到marker,那么
把channel C的state记为空集
执行marker sending rule
否则(并非第一次接收到marker)
把记录自身state(或最近一次记录另一个channel的state)后,收到这个marker前的message集记为C的state
每个process会记录自身的state和它的incoming channel的state
图解:
A,B,C,D代表4个process.有向线段代表FIFO的channel.绿色圆形代表普通message,橙色矩形代表marker.蓝色的节点和线段代表已经记录state的process和channel
Process A启动snapshot算法,A执行marker sending rule(记录自身state,然后发送marker):

Process B接收到marker,执行marker receiving rule:将channel AB的state记为空集,然后记录自身state并向下发送marker:

Process C接收到marker, 执行marker receiving rule:将channel AC的state记为空集,然后记录自身state并向下发送marker:
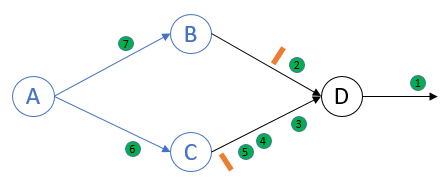
Process D接收到来自于process B的marker, 执行marker receiving rule:将channel BD的state记为空集,然后记录自身state并向下发送marker:
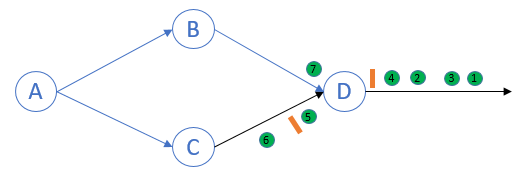
Process D接收到来自于process C的marker, 执行marker receiving rule:这是process D第二次接收到marker,将channel CD的state记为{5},不会向下发送marker:

自此process A,B,C,D的local state和所有Channel的state都记录完毕. 将这些local state组合,所得到的就是global state
Flink的snapshot算法 ---- Asynchronous Barrier Snapshotting(ABS)
为了消去记录channel state这一步骤,process在接收到第一个barrier后不会马上做snapshot,
而是等待接受其他上游channel的barrier.
在等待期间,process会把barrier已到的channel的record放入input buffer.
当所有上游channel的barrier到齐后,process才记录自身state,之后向所有下游channel发送barrier.
因为先到的barrier会等待后到的barrier,所有所有barrier相当于同时到达process,
因此,该process的上游channel的state都是空集.这就避免了去记录channel的state
图解:
A是JobManager, B C是source,D是普通task.
JobManager发起一次snapshot:向所有source发送barrier.
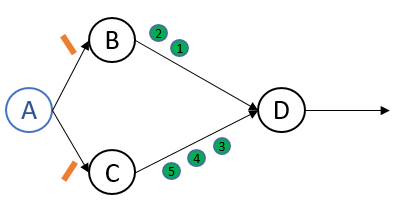
每个Barrier先后到达各自的source.Source在收到barrier后记录自身state,然后向下游节点发送barrier

Barrier (from)B 到达process D,但不会进行snapshot
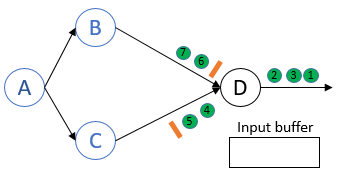
Barrier (from)B已经到达process D,
所以当来自于channel BD的record 6 7到达后,process D不会处理它们,而是将它们放入input buffer.
而Barrier (from)C尚未到达process D,所以当来自于channel CD的record 4到达后,process D会处理它.
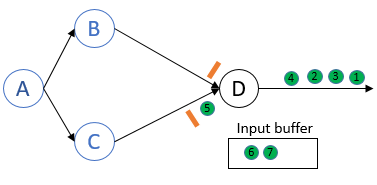
Barrier C也到达process D.
这样,process D已经接收到了所有上游process的barrier.process D记录自身state,然后向下游节点发送barrier
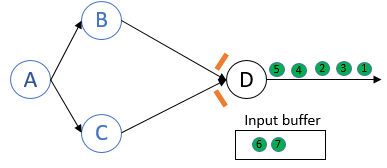
ABS的at least once模式
当process接收到barrier后,会立刻做snapshot. Process会继续处理所有channel的record.后来的snapshot会覆盖之前的snapshot.

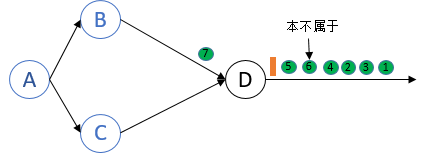
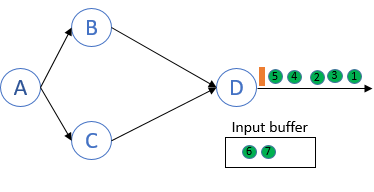
Record 6本不属于这次checkpoint,却包含在process D的local state中.
在recovery时,source认为record 6还没有被处理过,所以重发record 6. 这就导致stream中出现了两个record 6,造成了at least once.
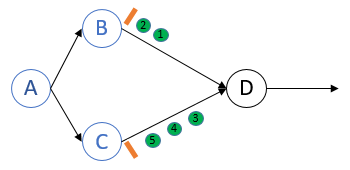
这里的问题在于,当第二个barrier到达时,节点D再次对自身做了snapshot.
而在Chandy-Lamport的算法中,第二个barrier到达时,节点D应该对barrier来源的channel做snapshot.
对单一input channel的算子来说,没有Alignment这个概念.这些算子在at least once模式下也是呈现exactly once的行为
原文:https://www.cnblogs.com/tuowang/p/9022198.html
flink ---- 系统内部消息传递的exactly once语义的更多相关文章
- 深入理解Flink ---- 系统内部消息传递的exactly once语义
At Most once,At Least once和Exactly once 在分布式系统中,组成系统的各个计算机是独立的.这些计算机有可能fail. 一个sender发送一条message到rec ...
- [源码分析] 从FlatMap用法到Flink的内部实现
[源码分析] 从FlatMap用法到Flink的内部实现 0x00 摘要 本文将从FlatMap概念和如何使用开始入手,深入到Flink是如何实现FlatMap.希望能让大家对这个概念有更深入的理解. ...
- 彻底明白Flink系统学习5:window、Linux本地安装Flink
http://www.aboutyun.com/thread-26393-1-1.html 问题导读 1.如何在window下安装Flink? 2.Flink本地安装启动命令与原先版本有什么区别? 3 ...
- 系统内部集成测试(System Integration Testing) SIT 用户验收测试(User Acceptance Testing)
系统内部集成测试(System Integration Testing) SIT 用户验收测试(User Acceptance Testing) UAT SIT在前,UAT在后,UAT测完才可以上线
- Flink系统之Table API 和 SQL
Flink提供了像表一样处理的API和像执行SQL语句一样把结果集进行执行.这样很方便的让大家进行数据处理了.比如执行一些查询,在无界数据和批处理的任务上,然后将这些按一定的格式进行输出,很方便的让大 ...
- Flink流处理(四)- 时间语义
4. 时间语义(Time Semantics) 这章我们会介绍时间语义,以及在流中,对于时间的各种不同的概念的描述.同时我们也会讨论一个流处理器在事件乱序的情况下,如何能提供精准的结果,以及如何使用流 ...
- Github 的系统内部都在用什么开源软件?
有时候处理规模问题最好的办法就是让事情变得简单并尽你可能去避免出现这种情况.这是 GitHub 所采用的方法,林纳斯·托瓦兹(Linus Torvalds)在十年前开发了Git源代码控制工具,GitH ...
- Page9:结构分解以及系统内部稳定和BIBO稳定概念及其性质[Linear System Theory]
内容包含系统能控性结构分解.系统能观测性结构分解以及系统结构规范分解原理,线性系统的内部稳定.BIBO稳定概念及其性质
- twitter storm 源码走读之5 -- worker进程内部消息传递处理和数据结构分析
欢迎转载,转载请注明出处,徽沪一郎. 本文从外部消息在worker进程内部的转化,传递及处理过程入手,一步步分析在worker-data中的数据项存在的原因和意义.试图从代码实现的角度来回答,如果是从 ...
随机推荐
- 使用FileZilla快速搭建FTP文件服务
为了便于平时对文件的存储访问,特意搭建FTP服务 FTP服务器(File Transfer Protocol Server)是在互联网上提供文件存储和访问服务的计算机,它们依照FTP协议提供服务. F ...
- js动画---多物体运动
对于多物体运动和单个物体运动来说,没有特别大的区别,实现原理基本上是一样的,都是通过定时器来实现的,但是多物体有一些地方需要注意,具体哪些需要注意,我将在下面的程序中说明. 首先,我们需要建立几个li ...
- loj10017. 「一本通 1.2 练习 4」传送带(三分套三分)
题目描述 在一个2维平面上有两条传送带,每一条传送带可以看成是一条线段.两条传送带分别为线段AB和线段CD.lxhgww在AB上的移动速度为P,在CD上的移动速度为Q,在平面上的移动速度R.现在lxh ...
- Java批量下载文件并zip打包
客户需求:列表勾选需要的信息,点击批量下载文件的功能.这里分享下我们系统的解决方案:先生成要下载的文件,然后将其进行压缩,生成zip压缩文件,然后使用浏览器的下载功能即可完成批量下载的需求.以下是zi ...
- 【IIS】跨域(转)
Access to XMLHttpRequest at 'http://*****/.dae' from origin 'http://192.168.198.21:22222' has been b ...
- js回调与异步加载的用法
以前还是菜鸟的时候(虽然现在依然很菜 -_-|| )对异步加载与回调函数的技术无比向往,但也一直没有使用过,这次因为页面逻辑太过复杂,一堆请求逻辑,如果还是用顺序请求,页面的速度... 领导又要挠头了 ...
- jasypt-spring-boot
运行 运行时配置解密秘钥-Djasypt.encryptor.password=在idea中运行 命令行启动和docker中运行参见https://www.cnblogs.com/zz0412/p/j ...
- svn服务器命令(转)
*验证svn安装是否成功 #svnadmin --version *创建svn的数据仓库 #svnadmin create /data/svn/svndata/spms *启动svn服务 #svnse ...
- GoCN每日新闻(2019-11-01)
GoCN每日新闻(2019-11-01) GoCN每日新闻(2019-11-01) 1. Rob Pike 认为 Go 成功的 5 个因素 https://changelog.com/posts/5- ...
- GoCN每日新闻(2019-10-31)
GoCN每日新闻(2019-10-31) GoCN每日新闻(2019-10-31) 1. Go语言继承的其他语言的优秀之处 https://spf13.com/presentation/the-leg ...