C++标准库实现WAV文件读写
在上一篇文章RIFF和WAVE音频文件格式中对WAV的文件格式做了介绍,本文将使用标准C++库实现对数据为PCM格式的WAV文件的读写操作,只使用标准C++库函数,不依赖于其他的库。
WAV文件结构
WAV是符合RIFF标准的多媒体文件,其文件结构可以如下:
| WAV 文件结构 |
|---|
| RIFF块 |
| WAVE FOURCC |
| fmt 块 |
| fact 块(可选) |
| data块(包含PCM数据) |
首先是一个RIFF块,有块标识RIFF,指明该文件是符合RIFF标准的文件;接着是一个FourCC,WAVE,该文件为WAV文件;fmt块包含了音频的一些属性:采样率、码率、声道等;fact 块是一个可选块,不是PCM数据格式的需要该块;最后data块,则包含了音频的PCM数据。实际上,可以将一个WAV文件看着由两部分组成:文件头和PCM数据,则WAV文件头各字段的意义如下:

本文实现的是一个能够读取PCM数据格式的单声道或者双声道的WAV文件,是没有fact块以及扩展块。
结构体定义
通过上面的介绍发现,WAV的头文件所包含的内容有两种:RIFF文件格式标准中需要的数据和关于音频格式的信息。对于RIFF文件格式所需的信息,声明结构体如下:
// The basic chunk of RIFF file format
struct Base_chunk{
FOURCC fcc; // FourCC id
uint32_t cb_size; // 数据域的大小
Base_chunk(FOURCC fourcc)
: fcc(fourcc)
{
cb_size = 0;
}
};
chunk是RIFF文件的基本单元,首先一个4字节的标识FOURCC,用来指出该块的类型;cb_size则是改块数据域中数据的大小。
文件头中另一个信息则是音频的格式信息,实际上是frm chunk的数据域信息,其声明如下:
// Format chunk data field
struct Wave_format{
uint16_t format_tag; // WAVE的数据格式,PCM数据该值为1
uint16_t channels; // 声道数
uint32_t sample_per_sec; // 采样率
uint32_t bytes_per_sec; // 码率,channels * sample_per_sec * bits_per_sample / 8
uint16_t block_align; // 音频数据块,每次采样处理的数据大小,channels * bits_per_sample / 8
uint16_t bits_per_sample; // 量化位数,8、16、32等
uint16_t ex_size; // 扩展块的大小,附加块的大小
Wave_format()
{
format_tag = 1; // PCM format data
ex_size = 0; // don't use extesion field
channels = 0;
sample_per_sec = 0;
bytes_per_sec = 0;
block_align = 0;
bits_per_sample = 0;
}
Wave_format(uint16_t nb_channel, uint32_t sample_rate, uint16_t sample_bits)
:channels(nb_channel), sample_per_sec(sample_rate), bits_per_sample(sample_bits)
{
format_tag = 0x01; // PCM format data
bytes_per_sec = channels * sample_per_sec * bits_per_sample / 8; // 码率
block_align = channels * bits_per_sample / 8;
ex_size = 0; // don't use extension field
}
};
关于各个字段的信息,在上面图中有介绍,这里主要说明两个字段:
format_tag表示以何种数据格式存储音频的sample值,这里设置为0x01表示用PCM格式,非压缩格式,不需要fact块。ex_size表示的是扩展块的大小。有两种方法来设置不使用扩展块,一种是设置fmt中的size字段为16(无ex_size字段);或者,有ex_size,设置其值为0.在本文中,使用第二种方法,设置ex_size的值为0,不使用扩展块。
有了上面两个结构体的定义,对于WAV的文件头,可以表示如下:
/*
数据格式为PCM的WAV文件头
--------------------------------
| Base_chunk | RIFF |
---------------------
| WAVE |
---------------------
| Base_chunk | fmt | Header
---------------------
| Wave_format| |
---------------------
| Base_chunk | data |
--------------------------------
*/
struct Wave_header{
shared_ptr<Base_chunk> riff;
FOURCC wave_fcc;
shared_ptr<Base_chunk> fmt;
shared_ptr<Wave_format> fmt_data;
shared_ptr<Base_chunk> data;
Wave_header(uint16_t nb_channel, uint32_t sample_rate, uint16_t sample_bits)
{
riff = make_shared<Base_chunk>(MakeFOURCC<'R', 'I', 'F', 'F'>::value);
fmt = make_shared<Base_chunk>(MakeFOURCC<'f', 'm', 't', ' '>::value);
fmt->cb_size = 18;
fmt_data = make_shared<Wave_format>(nb_channel, sample_rate, sample_bits);
data = make_shared<Base_chunk>(MakeFOURCC<'d', 'a', 't', 'a'>::value);
wave_fcc = MakeFOURCC<'W', 'A', 'V', 'E'>::value;
}
Wave_header()
{
riff = nullptr;
fmt = nullptr;
fmt_data = nullptr;
data = nullptr;
wave_fcc = 0;
}
};
在WAV的文件头中有三种chunk,分别为:RIFF,fmt,data,然后是音频的格式信息Wave_format。在RIFF chunk的后面是一个4字节非FOURCC:WAVE,表示该文件为WAV文件。另外,Wave_format的构造函数只需要三个参数:声道数、采样率和量化精度,关于音频的其他信息都可以使用这三个数值计算得到。注意,这里设置fmt chunk的size为18。
实现
有了上面结构体后,再对WAV文件进行读写就比较简单了。由于RIFF文件中使用FOURCC老标识chunk的类型,这里有两个FOURCC的实现方法:使用宏和使用模板,具体如下:
#define FOURCC uint32_t
#define MAKE_FOURCC(a,b,c,d) \
( ((uint32_t)d) | ( ((uint32_t)c) << 8 ) | ( ((uint32_t)b) << 16 ) | ( ((uint32_t)a) << 24 ) )
template <char ch0, char ch1, char ch2, char ch3> struct MakeFOURCC{ enum { value = (ch0 << 0) + (ch1 << 8) + (ch2 << 16) + (ch3 << 24) }; };
Write WAVE file
写WAV文件过程,首先是填充文件头信息,对于Wave_format只需要三个参数:声道数、采样率和量化精度,将文件头信息写入后,紧接这写入PCM数据就完成了WAV文件的写入。其过程如下:
Wave_header header(1, 48000, 16);
uint32_t length = header.fmt_data->sample_per_sec * 10 * header.fmt_data->bits_per_sample / 8;
uint8_t *data = new uint8_t[length];
memset(data, 0x80, length);
CWaveFile::write("e:\\test1.wav", header, data, length);
首先够着WAV文件头,然后写入文件即可。将数据写入的实现也比较简单,按照WAv的文件结构,依次将数据写入文件。在设置各个chunk的size值时要注意其不同的意义:
- RIFF chunk 的size表示的是其数据的大小,其包含各个chunk的大小以及PCM数据的长度。该值 + 8 就是整个WAV文件的大小。
- fmt chunk 的size是
Wave_format的大小,这里为18 - data chunk 的size 是写入的PCM数据的长度
Read WAVE file
知道了WAV的文件结构后,读取其数据就更为简单了。有一种直接的方法,按照PCM相对于文件起始的位置的偏移位置,直接读取PCM数据;或者是按照其文件结构依次读取信息,本文的将依次读取WAV文件的信息填充到相应的结构体中,其实现代码片段如下:
header = make_unique<Wave_header>();
// Read RIFF chunk
FOURCC fourcc;
ifs.read((char*)&fourcc, sizeof(FOURCC));
if (fourcc != MakeFOURCC<'R', 'I', 'F', 'F'>::value) // 判断是不是RIFF
return false;
Base_chunk riff_chunk(fourcc);
ifs.read((char*)&riff_chunk.cb_size, sizeof(uint32_t));
header->riff = make_shared<Base_chunk>(riff_chunk);
// Read WAVE FOURCC
ifs.read((char*)&fourcc, sizeof(FOURCC));
if (fourcc != MakeFOURCC<'W', 'A', 'V', 'E'>::value)
return false;
header->wave_fcc = fourcc;
...
实例
调用本文的实现,写入一个单声道,16位量化精度,采样率为48000Hz的10秒钟WAV文件,代码如下:
Wave_header header(1, 48000, 16);
uint32_t length = header.fmt_data->sample_per_sec * 10 * header.fmt_data->bits_per_sample / 8;
uint8_t *data = new uint8_t[length];
memset(data, 0x80, length);
CWaveFile::write("e:\\test1.wav", header, data, length);
这里将所有的sample按字节填充为0x80,以16进制打开该wav文件,结果如下:
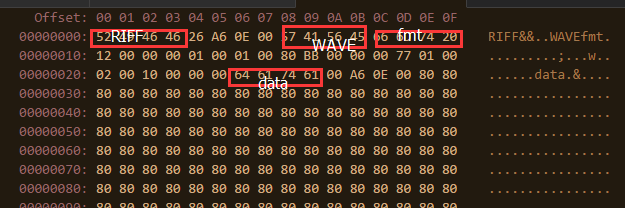
可以参照上图给出的WAV文件头信息,看看各个字节的意义。音频的格式信息在FOURCC fmt后面
- 4字节 00000012 fmt数据的长度 18字节
- 2字节 0001 数据的存储格式为PCM
- 2字节 0001 声道个数
- 4字节 0000BB80 采样率 48000Hz
- 4字节 00017700 码率 96000bps
- 2字节 0002 数据块大小
- 2字节 0010 量化精度 16位
- 2字节 0000 扩展块的大小
- 4字节 FOURCC data
- 4字节 数据长度 0x000EA600
代码
最后将本文的代码封装在了类CWaveFile中,使用简单。
- 写WAV文件
Wave_header header(1, 48000, 16);
uint32_t length = header.fmt_data->sample_per_sec * 10 * header.fmt_data->bits_per_sample / 8;
uint8_t *data = new uint8_t[length];
memset(data, 0x80, length);
CWaveFile::write("e:\\test1.wav", header, data, length);
- 读取WAV文件
CWaveFile wave;
wave.read("e:\\test1.wav");
wave.data // PCM数据
源代码只有一个不到300行的cpp文件, CSDN下载
C++标准库实现WAV文件读写的更多相关文章
- 用 #include “filename.h” 格式来引用非标准库的头文件
用 #include “filename.h” 格式来引用非标准库的头文件(编译器将 从用户的工作目录开始搜索) #include <iostream> /* run this progr ...
- 用 #include <filename.h> 格式来引用标准库的头文件
用 #include <filename.h> 格式来引用标准库的头文件(编译器将从 标准库目录开始搜索). #include <iostream> /* run this p ...
- c/c++标准库中的文件操作总结
1 stdio.h是c标准库中的标准输入输出库 2 在c++中调用的方法 直接调用即可,但是最好在函数名前面加上::,以示区分类的内部函数和c标准库函数. 3 c标准输入输出库的使用 3.1 核心结构 ...
- Linux音频编程--使用ALSA库播放wav文件
在UBUNTU系统上使用alsa库完成了对外播放的wav文件的案例. 案例代码: /** *test.c * *注意:这个例子在Ubuntu 12.04.1环境下编译运行成功. * */ #inclu ...
- Python 标准库 csv —— csv 文件的读写
csv 文件,逗号分割文件. 0. 读取 csv 到 list from csv import reader def load_csv(csvfile): dataset = [] with open ...
- python --标准库 路径与文件 (os.path包, glob包)
os.path包 os.path包主要是处理路径字符串,提取出有用信息. #coding:utf-8 import os.path path = 'D:\\Python7\\test\\data.tx ...
- C++标准库头文件找不到的问题
当你写C++程序时,在头文件中包含C++标准库的头文件,比如#include <string>,而编译器提示你找不到头文件! 原因就是你的实现源文件扩展名是".c"而不 ...
- Python解析Wav文件并绘制波形的方法
资源下载 #本文PDF版下载 Python解析Wav文件并绘制波形的方法 #本文代码下载 Wav波形绘图代码 #本文实例音频文件night.wav下载 音频文件下载 (石进-夜的钢琴曲) 前言 在现在 ...
- Python标准库、第三方库和外部工具汇总
导读:Python数据工具箱涵盖从数据源到数据可视化的完整流程中涉及到的常用库.函数和外部工具.其中既有Python内置函数和标准库,又有第三方库和工具. 这些库可用于文件读写.网络抓取和解析.数据连 ...
随机推荐
- 奇异值分解(SVD)原理与在降维中的应用
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域.是 ...
- 本人提供微软系.NET技术顾问服务,欢迎企业咨询!
背景: 1:目前微软系.NET技术高端人才缺少. 2:企业很难直接招到高端技术人才. 3:本人提供.NET技术顾问,保障你的产品或项目在正确的技术方向. 技术顾问服务 硬服务项: 1:提供技术.决策. ...
- android键盘
在应用的开发过程中有不少的情况下会用到自定义键盘,例如支付宝的支付密码的输入,以及类似的场景.android系统给开发者们提供了系统键盘,KeyboardView,其实并不复杂,只是有些开发者不知道罢 ...
- PHP之Memcache缓存详解
Mem:memory缩写(内存):内存缓存 1. 断电或者重启服务器内存数据即消失,即临时数据: Memcache默认端口:11211 存入方式:key=>>value ...
- C#项目中文件的具体含义
1.Bin 目录 用来存放编译的结果,bin是二进制binary的英文缩写,因为最初C编译的程序文件都是二进制文件,它有Debug和Release两个版本,分别对应的文件夹为bin/Debug和bin ...
- GOF23设计模式之单例模式
·核心作用: -保证一个类只有一个实例,并且提供一个访问该实例的全局访问点. ·常见应用场景: -Windows的Task Manager(任务管理器)就是很典型的单例模式 -Windows的Recy ...
- 在 SharePoint Server 2016 本地环境中设置 OneDrive for Business
建议补丁 建议在sharepoint2016打上KB3127940补丁,补丁下载地址 https://support.microsoft.com/zh-cn/kb/3127940 当然不打,也可以用O ...
- 浅谈SQL注入风险 - 一个Login拿下Server
前两天,带着学生们学习了简单的ASP.NET MVC,通过ADO.NET方式连接数据库,实现增删改查. 可能有一部分学生提前预习过,在我写登录SQL的时候,他们鄙视我说:“老师你这SQL有注入,随便都 ...
- 【Update】C# 批量插入数据 SqlBulkCopy
SqlBulkCopy的原理就是通过在客户端把数据都缓存在table中,然后利用SqlBulkCopy一次性把table中的数据插入到数据库中. SqlConnection sqlConn = new ...
- git &github 快速入门
本节内容 github介绍 安装 仓库创建& 提交代码 代码回滚 工作区和暂存区 撤销修改 删除操作 远程仓库 分支管理 多人协作 github使用 忽略特殊文件.gitignore 1.gi ...