Java基础之HashMap原理分析(put、get、resize)
在分析HashMap之前,先看下图,理解一下HashMap的结构
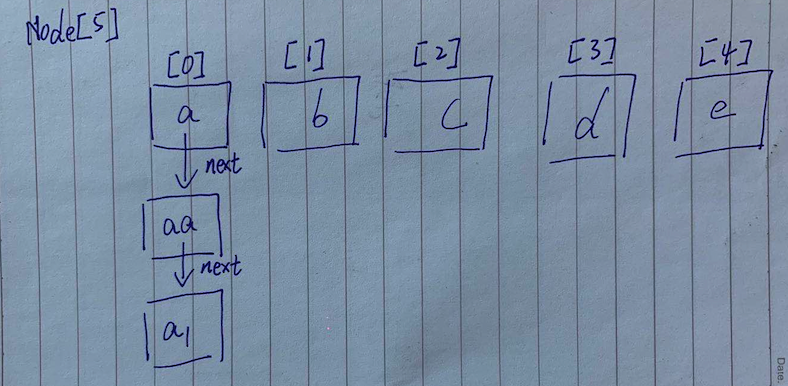
我手画了一个图,简单描述一下HashMap的结构,数组+链表构成一个HashMap,当我们调用put方法的时候增加一个新的 key-value 的时候,HashMap会通过key的hash值和当前node数据的长度计算出来一个index值,然后在把 hash,key,value 创建一个Node对象,根据index存入Node[]数组中,当计算出来的index上已经存在了Node对象的话。就把新值存在 Node[index].next 上,就像图中的 a->aa->a1 一样,这样的情况我们称之为hash冲突
HashMap基本用法
Map<String, Object> map = new HashMap<>();
map.put("student", "333");//正常入数组,i=5
map.put("goods", "222");//正常入数据,i=9
map.put("product", "222");//正常入数据,i=2
map.put("hello", "222");//正常入数据,i=11
map.put("what", "222");//正常入数据,i=3
map.put("fuck", "222");//正常入数据,i=7
map.put("a", "222");//正常入数据,i=1
map.put("b", "222");//哈希冲突,i=2,product.next
map.put("c", "222");//哈希冲突,i=3,what.next
map.put("d", "222");//正常入数据,i=4
map.put("e", "222");//哈希冲突,i=5,student.next
map.put("f", "222");//正常入数据,i=6
map.put("g", "222");//哈希冲突,i=7,fuck.next
首先我们都是创建一个Map对象,然后用HashMap来实现,通过调用 put get 方法就可以实现数据存储,我们就先从构造方法开始分析
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
初始化负载因子为0.75,负载因子的作用是计算一个扩容阀值,当容器内数量达到阀值时,HashMap会进行一次resize,把容器大小扩大一倍,同时也会重新计算扩容阀值。扩容阀值=容器数量 * 负载因子,具体为啥是0.75别问我,自己查资料吧(其实我是不知道,我觉得这个不重要吧~)
继续看 put 方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
额,也没啥可看的,继续往下看putVal方法吧
transient Node<K,V>[] table;
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//先判断当前容器内的哈希表是否是空的,如果table都是空的就会触发resize()扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//通过 (n - 1) & hash 计算索引,稍后单独展开计算过程
if ((p = tab[i = (n - 1) & hash]) == null)
//如果算出来的索引上是空的数据,直接创建Node对象存储在tab下
tab[i] = newNode(hash, key, value, null);
else {
//如果tab[i]不为空,说明之前已经存有值了
Node<K,V> e; K k;
//如果key相同,则需要先把旧的 Node 对象取出来存储在e上,下边会对e做替换value的操作
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//在这里解决hash冲突,判断当前 node[index].next 是否是空的,如果为空,就直接
//创建新Node在next上,比如我贴的图上,a -> aa -> a1
//大概逻辑就是a占了0索引,然后aa通过 (n - 1) & hash 得到的还是0索引
//就会判断a的next节点,如果a的next节点不为空,就继续循环next节点。直到为空为止
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果当前这个链表上数量超过8个,会直接转化为红黑树,因为红黑树查找效率
//要比普通的单向链表速度快,性能好
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//只有替换value的时候,e才不会空
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//在增加计数器
++modCount;
//判断是否超过了负载,如果超过了会进行一次扩容操作
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
虽然写我加了注释,但是我还是简单说一下这个的逻辑吧
1.首先判断哈希表,是否存在,不存在的时候,通过resize进行创建
2.然后在通过索引算法计算哈希表上是否存在该数据,不存在就新增node节点存储,然后方法结束
3.如果目标索引上存在数据,则需要用equals方法判断key的内容,要是判断命中,就是替换value,方法结束
4.要是key也不一样,索引一样,那么就是哈希冲突,HashMap解决哈希冲突的策略就是遍历链表,找到最后一个空节点,存储值,就像我的图一样。灵魂画手有木有,很生动的表式了HashMap的数据结构
5.最后一步就是判断是否到扩容阀值,容量达到阀值后,进行一次扩容,按照2倍的规则进行扩容,因为要遵循哈希表的长度必须是2次幂的概念
好,put 告一断落,我们继续 get 吧
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
get方法,恩,好,很简单。hash一下key,然后通过getNode来获取节点,然后返回value,恩。get就讲完了,哈哈。开个玩笑。我们继续看getNode吧
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//哈希表存在的情况下,根据hash获取链表的头,也就是first对象
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//检测第一个first是的hash和key的内容是否匹配,匹配就直接返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//链表的头部如果不是那就开始遍历整个链表,如果是红黑树节点,就用红黑树的方式遍历
//整个链表的遍历就是通过比对hash和equals来实现
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
我们在整理一下,get方法比put要简单很多,核心逻辑就是取出来索引上的节点,然后挨个匹配hash和equals,直到找出节点。
那么get方法就搞定了
再来看一下resize吧。就是HashMap的扩容机制
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
//检测旧容器,如果旧容器是空的,就代表不需要处理旧数据
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//保存扩容阀值
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 对阀值进行扩容更新,左移1位代表一次2次幂
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//如果哈希表是空的,这里会进行初始化扩容阀值,
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
//处理旧数据,把旧数据挪到newTab内,newTab就是扩容后的新数组
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//如果当前元素无链表,直接安置元素
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//红黑树处理
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
//对链表的索引重新计算,如果还是0,那说明索引没变化
//如果hash的第5位等于1的情况下,那说明 hash & n - 1 得出来的索引已经发生变化了,变化规则就是 j + oldCap,就是索引内向后偏移16个位置
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
resize方法的作用就是初始化容器,以及对容器做扩容操作,扩容规则就是double
扩容完了之后还有一个重要的操作就是会对链表上的元素重新排列
(e.hash & oldCap) == 0
在讲这个公式之前,我先做个铺垫
16的二进制是 0001 0000
32的二进制是 0010 0000
64的二进制是 0100 0000
我们知道HashMap每次扩容都是左移1位,其实就是2的m+1次幂,也就是说哈希表每次扩容都是 16、32、64........n
然后我们知道HashMap内的索引是 hash & n - 1,n代表哈希表的长度,当n=16的时候,就是hash & 0000 1111,其实就是hash的后四位,当扩容n变成32的时候,就是 hash & 0001 1111,就是后五位
我为啥要说这个,因为跟上边的 (e.hash & oldCap) == 0 有关,这里其实我们也可以用
假设我们的HashMap从16扩容都了32。
其实可以用 e.hash & newCap -1 的方式来重新计算索引,然后在重排链表,但是源码作者采用的是另外一种方式(其实我觉得性能上应该一样)作者采用的是直接比对 e.hash 的第五位(16长度是后四位,32长度是后五位)进行 0 1校验,如果为0那么就可以说明 (hash & n - 1)算出来的索引没有变化,还是当前位置。要是第五位校验为1,那么这里(hash & n - 1)的公式得出来的索引就是向数据后偏移了16位。
所以作者在这里定义了两个链表,
loHead低位表头,loTail低位表尾(靠近索引0)
hiHead高位表头,hiTail高位表尾(远离索引0)
然后对链表进行拆分,如果计算出来索引没有变化,那么还让他停留在这个链表上(拼接在loTail.next上)
如果计算索引发生了变化。那么数据就要放置在高位链表上(拼接在hiTail.next)上
好了。HashMap就讲完了,可能还需要自己消化消化,反正我是消化完了。
Java基础之HashMap原理分析(put、get、resize)的更多相关文章
- 【Java基础】HashMap原理详解
哈希表(hash table) 也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,本文会对java集合框架中Has ...
- Java基础之LinkedHashMap原理分析
知识准备HashMap 我们平时用LinkedHashMap的时候,都会写下面这段 LinkedHashMap<String, Object> map = new LinkedHashMa ...
- JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balaba ...
- Java基础系列--HashMap(JDK1.8)
原创作品,可以转载,但是请标注出处地址:https://www.cnblogs.com/V1haoge/p/10022092.html Java基础系列-HashMap 1.8 概述 HashMap是 ...
- (6)Java数据结构-- 转:JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balab ...
- 原子类java.util.concurrent.atomic.*原理分析
原子类java.util.concurrent.atomic.*原理分析 在并发编程下,原子操作类的应用可以说是无处不在的.为解决线程安全的读写提供了很大的便利. 原子类保证原子的两个关键的点就是:可 ...
- Java NIO使用及原理分析 (四)
在上一篇文章中介绍了关于缓冲区的一些细节内容,现在终于可以进入NIO中最有意思的部分非阻塞I/O.通常在进行同步I/O操作时,如果读取数据,代码会阻塞直至有 可供读取的数据.同样,写入调用将会阻塞直至 ...
- Java NIO使用及原理分析 (四)(转)
在上一篇文章中介绍了关于缓冲区的一些细节内容,现在终于可以进入NIO中最有意思的部分非阻塞I/O.通常在进行同步I/O操作时,如果读取数据,代码会阻塞直至有 可供读取的数据.同样,写入调用将会阻塞直至 ...
- 支付宝app支付java后台流程、原理分析(含nei wang chuan tou)
java版支付宝app支付流程及原理分析 本实例是基于springmvc框架编写 一.流程步骤 1.执行流程 当手机端app(就是你公司开发的app)在支付 ...
随机推荐
- 三、HelloWorld
1.创建Hello.java 文件, 2.输入内容 public class Hello{ //公共类 Hello public static void main(String[] args){ // ...
- 简述python中`functools.wrapper()
简述python中functools.wrapper() 首先对于最简单的函数: def a(): pass if __name__ == '__main__': print(a.__name__) ...
- win10 + Ubuntu 20.04 LTS 双系统 引导界面美化
版权声明:本文为CSDN博主「ZChen1996」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明. 原文链接:https://blog.csdn.net/ZChen1 ...
- 《MySQL必知必会》通配符 ( like , % , _ ,)
<MySQL必知必会>通配符 ( like , % , _ ,) 关键字 LIke WHERE 搜索子句中使用通配符,必须使用 LIKE 操作符. % 百分号通配符 % 表示任意字符出现任 ...
- SVN的基本使用
2020年7月6日 为什么需要版本控制? 需要清晰地保存某些文件的不同修订版本 控制文件的发屐过程,找出导致 BUG 的原因 轻松将项目或文件恢复到指定版本 极大方便团队之间协同开发,防止出现混乱 在 ...
- Flutter简介
Flutter简介 Flutter 是 Google推出并开源的移动应用开发框架,主打跨平台.高保真.高性能.开发者可以通过 Dart语言开发 App,一套代码同时运行在 iOS 和 Android平 ...
- java+opencv实现人脸识别程序记录
结果 基本实现了识别的功能.基本的界面如下 界面长得比较丑,主要是JavaSwing写界面比较麻烦,写个菜单栏都要那么多代码.目前不打算改了. 实现的思路是:使用opencv中自带的OpenCVFra ...
- SpringBoot整合WebSocket实现前后端互推消息
小编写这篇文章是为了记录实现WebSocket的过程,受不了啰嗦的同学可以直接看代码. 前段时间做项目时设计了一个广播的场景,具体业务不再赘述,最终要实现的效果就是平台接收到的信息实时发布给所有的用户 ...
- APEX安装
git clone https://github.com/NVIDIA/apex.gitcd apex export CUDA_HOME=/usr/local/cudapip3 install -v ...
- hadoop平台环境搭建
centos01 配置静态ip vim /etc/sysconfig/network-scripts/ifcfg-eth0 见图1 修改主机名 vim /etc/sysconfig/network 见 ...