AI小白必读:深度学习、迁移学习、强化学习别再傻傻分不清
摘要:诸多关于人工智能的流行词汇萦绕在我们耳边,比如深度学习 (Deep Learning)、强化学习 (Reinforcement Learning)、迁移学习 (Transfer Learning),不少人对这些高频词汇的含义及其背后的关系感到困惑,今天就为大家理清它们之间的关系和区别。
一. 深度学习:
深度学习的成功和发展,得益于算力的显著提升和大数据,数字化后产生大量的数据,可通过大量的数据训练来发现数据的规律,从而实现基于监督学习的数据预测。
基于神经网络的深度学习主要应用于图像、文本、语音等领域。
2016年的 NIPS 会议上,吴恩达给出了一个未来AI方向的技术发展图:

监督学习(Supervised learning)是目前商用场景最多,成熟度最高的AI技术,而下一个商用的AI技术将会是迁移学习(Transfer Learning),这也是 Andrew 预测未来五年最有可能走向商用的AI技术。
二. 迁移学习:
迁移学习:用相关的、类似数据来训练,通过迁移学习来实现模型本身的泛化能力,是如何将学习到知识从一个场景迁移到另一个场景。
拿图像识别来说,从白天到晚上,从冬天到夏天,从识别中国人到 识别外国人……
借用一张示意图(From:A Survey on Transfer Learning)来进行说明:
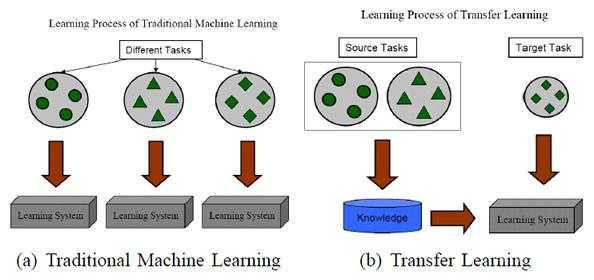
迁移学习的价值体现在:
1.一些场景的数据根本无法采集,这时迁移学习就很有价值;
2.复用现有知识域数据,已有的大量工作不至于完全丢弃;
3.不需要再去花费巨大代价去重新采集和标定庞大的新数据集;
4.对于快速出现的新领域,能够快速迁移和应用,体现时效性优势;
关于迁移学习算法的实践总结:
1. 通过原有数据和少量新领域数据混淆训练;
2. 将原训练模型进行分割,保留基础模型(数据)部分作为新领域的迁移基础;
3. 通过三维仿真来得到新的场景图像(OpenAI的Universe平台借助赛车游戏来训练);
4. 借助对抗网络 GAN 进行迁移学习 的方法;
三. 强化学习:
强化学习:全称是 Deep Reinforcement Learning(DRL),让机器有了自我学习、自我思考的能力。
目前强化学习主要用在游戏 AI 领域,最出名的应该算AlphaGo的围棋大战。强化学习是个复杂的命题,Deepmind 大神 David Silver 将其理解为这样一种交叉学科:

实际上,强化学习是一种探索式的学习方法,通过不断 “试错” 来得到改进,不同于监督学习的地方是 强化学习本身没有 Label,每一步的 Action 之后它无法得到明确的反馈(在这一点上,监督学习每一步都能进行 Label 比对,得到 True or False)。
强化学习是通过以下几个元素来进行组合描述的:
对象(Agent)
也就是我们的智能主题,比如 AlphaGo。
环境(Environment)
Agent 所处的场景-比如下围棋的棋盘,以及其所对应的状态(State)-比如当前所对应的棋局。
Agent 需要从 Environment 感知来获取反馈(当前局势对我是否更有利)。
动作 (Actions)
在每个State下,可以采取什么行动,针对每一个 Action 分析其影响。
奖励 (Rewards)
执行 Action 之后,得到的奖励或惩罚,Reward 是通过对 环境的观察得到。
AI小白必读:深度学习、迁移学习、强化学习别再傻傻分不清的更多相关文章
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
- [强化学习]Part1:强化学习初印象
引入 智能 人工智能 强化学习初印象 强化学习的相关资料 经典书籍推荐:<Reinforcement Learning:An Introduction(强化学习导论)>(强化学习教父Ric ...
- David Silver强化学习Lecture1:强化学习简介
课件:Lecture 1: Introduction to Reinforcement Learning 视频:David Silver深度强化学习第1课 - 简介 (中文字幕) 强化学习的特征 作为 ...
- 卡耐基梅隆大学(CMU)元学习和元强化学习课程 | Elements of Meta-Learning
Goals for the lecture: Introduction & overview of the key methods and developments. [Good starti ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- 【转载】 “强化学习之父”萨顿:预测学习马上要火,AI将帮我们理解人类意识
原文地址: https://yq.aliyun.com/articles/400366 本文来自AI新媒体量子位(QbitAI) ------------------------------- ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
随机推荐
- webgl实现径向模糊
径向模糊简介 径向模糊,是一种从中心向外呈幅射状,逐渐模糊的效果. 因此径向模糊经常会产生一些中心的发散效果,在PS中同样也有径向模糊的滤镜效果. 径向模糊通常也称为变焦模糊.径向模糊(Radial ...
- mysql数据库中数据类型的长度
在mysql中新建数据表的时候会有长度一说,其实用建表语句建数据表的时候也有涉及 例如: CREATE TABLE user( uid int(4), name varchar(255), passw ...
- Intermediate English Book 1
List x1.0 x1.5 Lesson 1 Reading Lesson 1 Details Lesson 2 Dialogue Lesson 2 Details Lesson 3 Reading ...
- ios Standard Framework和Umbrella Framework
Standard Framework:标准库,通过引用对应的header文件而不是引用master header 文件来引用类(也可以通过引用Master Header file来引用需要使用的类), ...
- selenium上手
功能自动化 前提 自动化的主要目的并不是为了找Bug,是为了证明功能可用 不只是所有的功能都可以自动化,如UI 并不是所有的项目都可以使用自动化,如selenium只能使用bs项目,小项目不适合使用自 ...
- 使用Telnet服务测试端口时,提示没有Telnet服务
1.win7系统是默认不开启Telnet服务的,所以我们第一次使用时要手动开启Telnet服务 1)打开 控制面板 > 程序 > 程序功能 > 打开或关闭Windows功能,勾选上T ...
- 【CF】Sereja and Arcs
#include <bits/stdc++.h> #define llong long long using namespace std; const int N = 1e5; const ...
- C013:颠倒显示三位数
代码: #include "stdafx.h" int _tmain(int argc, _TCHAR* argv[]) { int original; do{ printf(&q ...
- (Python)正则表达式进行匹配
import os import re pattern=re.compile(r'(\d{4})-(\d{2})-(\d{2})-b(\d{3})') // 要匹配的目录格式 for root,dir ...
- 从通达信导出文件获取A股所有股票代号名称(至2020年2月24日)
下文是讲述如何从通达信的输出文件中获得股票信息,如果想用Java爬虫从网页爬取信息请参考:https://www.cnblogs.com/xiandedanteng/p/12808381.html 要 ...