高速缓冲存储器Cache
概述
问题的提出
避免CPU“空等”的现象
CPU和主存的速度差异
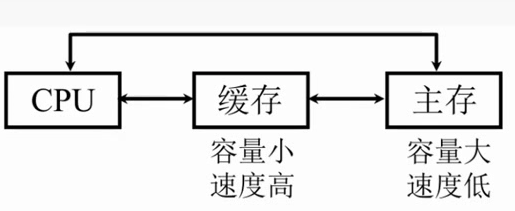
容量非常小,但是速度非常高,他就能提高CPU的访存速率了。
为了充分发挥cache的作用,切实提高CPU的访存速率,所以CPU的访问数据和指令要求能大多数都能在cache中能够取到,这样就不需要到主存中去取了。这需要依靠局部性原理。
局部性原理
时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息。
空间局部性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是临近的。
顺序存放。
所以我们未来要用的信息很可能和我们现在使用的信息的存储空间上是临近的
交换的单位是以块为单位的。
主存分成大小相同的块,Cache也分成了大小相同的块
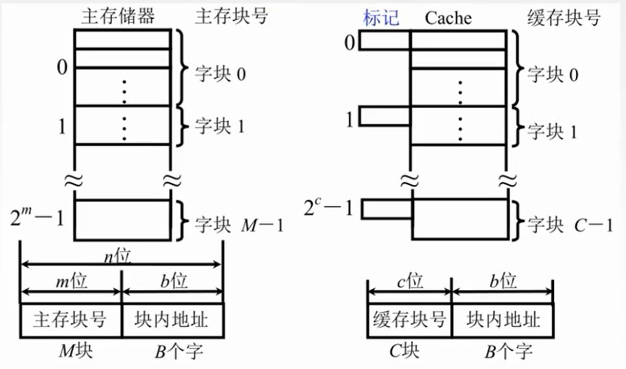
主存和缓存按块存储,块的大小相同,B为块长。
M要远远大于C
块内地址的位数决定了块的大小。假如有16个字节,块内地址就有4位???
主存和缓存的块内地址是完全相同
标记是用来说明主存块和cache的对应关系。
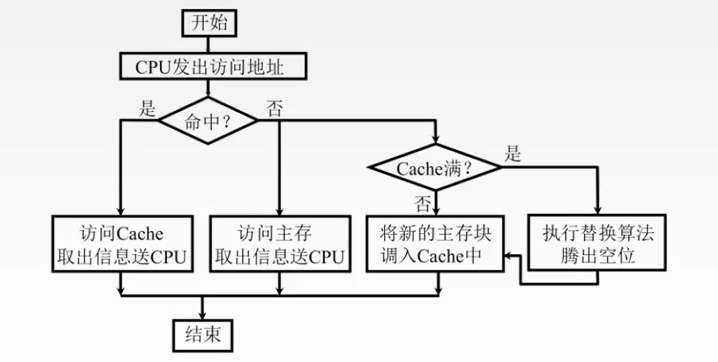
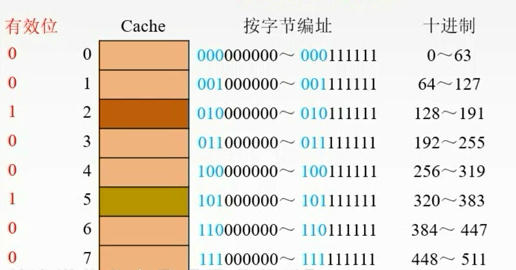
命中与未命中
缓存中有C块
主存中有M块M>>C
命中:主存块已经调入缓存,主存块与缓存块建立了对应关系,用标记记录与某缓存块建立了对应关系的主存块号。
未命中:主存块未调入缓存,主存块与缓存块未建立对应关系。
Cache的命中率
CPU欲访问的信息在Cache中的比率
设一个程序在执行期间,Cache的总命中次数为Nc,访问主存的总次数为Nm,则命中率
\]
命中率和Cache的容量和块长有关
一般每块可取4~8个字
块长取一个存取周期内从主存调出的信息长度
失效率=1-H
Cache-主存系统的效率
效率e与 命中率 有关
\]
如何计算平均访问时间?命中时访问Cache的时间加上不命中在主存的时间
设Cache命中率为h,访问Cache的时间为tc,访问主存的时间为tm
\]
最小值是命中率为0的时候,最大值是命中率为1的时候
例题

设Cache的存储周期是t,则主存的存储周期是5t
Cache和主存同时访问,不命中时访问时间为5t
故系统的平均访问时间为Ta=0.95 * t+0.05 * 5t=1.2t
设每个周期可存取的数据量为S,
则存储系统带宽为S/1.2t
不采用Cache时带宽为S/5t
故性能为原来的
\]
提高了3.17倍
若改为先访问Cache再访问主存的方式:
不命中时,访问Cache耗时t
发现不命中后在访问主存,耗时5t
总耗时6t
故系统的平均访问时间为Ta=0.95 * t+0.05 * 6t = 1.25t
故性能为原来的5t/1.25t=4倍,提高了3倍
工作原理
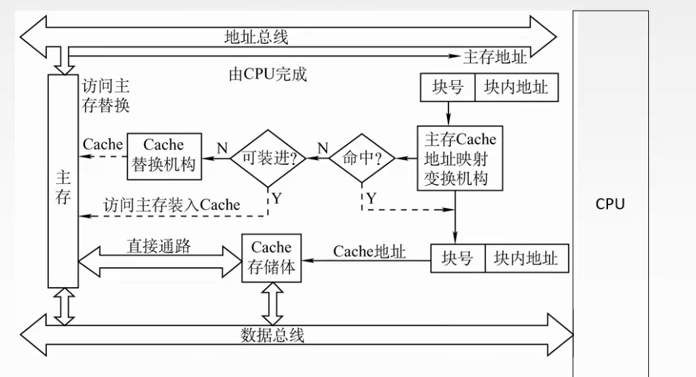
当Cache要读的时候
地址映射方式(本节最重要)
1.主存中的块放到Cache中哪个位置?
(1)空位随意放:全相联映射
(2)对号入座:直接映射
(3)按号分组,组内随意放:组相联映射
2.对于(1),Cache满了如何处理?对于(2)(3),对应位置被占用如何处理?
随机(RAND)算法
先进先出(FIFO)算法
近期最少使用(LRU)算法
最不经常使用(LFU)算法
3.修改Cache中的内容后,如何保持主存中相应内容的一致性?
命中:全写法(write-through)、写回法(write-back)
不命中:写分配法(write-allocate)、非写分配法(not-write-allocate)
直接映射
主存当中的数据块只能够装入到Cache的唯一位置。
把主存划分为若干个区,每个区大小和Cache是相等的,每个去的子块数也是相等的。
每个区的对应单元只能对应Cache对应的单元。
主存地址的高m位就被划分为两个部分——主存子块标记,Cache子块地址
记录建立对应关系的缓存位的标记位当中
当缓存接到CPU接来的一个主存地址之后,根据中间的c位(Cache子块地址)找到cache字块,然后根据这个子块的标记,判断****是否与主存的高t位相符,如果相符,并且有效位**是有效(1)的,那么就表示Cache块已经和主存的某一块地址建立了对应关系。
如果不符合的话,就要从主存中读入新的子块。
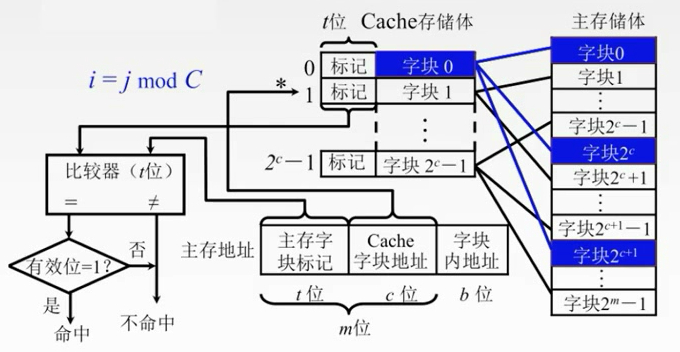
每个缓存块i 可以和若干个主存块对应
每个主存块j 只能和一个缓存块对应
直接映射主存地址被划分为三个部分

j是Cache的块号。i是主存的块号
特点简单,但是不够灵活,容易发生冲突。
即使Cache有很多空位置,但是我还是要找到对应位置的来换
全相联映射
大大提高了利用率,只要有位置就放。但是速度很慢。对比子块标记很麻烦,每块都要比较。
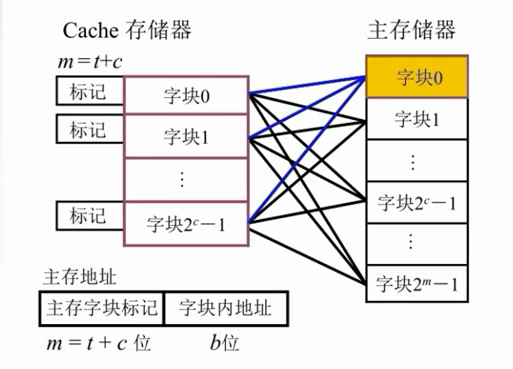
主存中的任一块可以映射到缓存中的任一块
组相联映射
折中。
先把主存储器划分为块,在把每个块划分为组。
先把Cache地址分成大小相同的组,每一个主存的数据块可以装入到一个组内的任何位置。
组间采用直接映射,组内全相联映射。
01,23,45,67,。。。
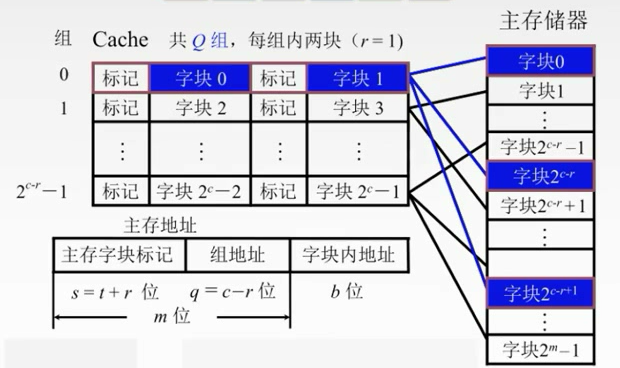

二路组相联映射。
速度快:直接映射
一般:组相联
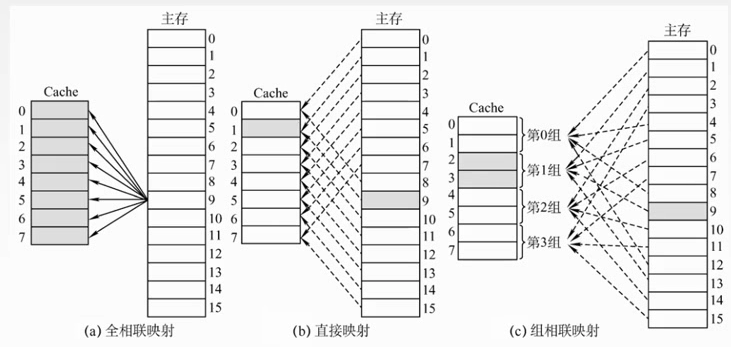
例子

全相联

直接映射

组相联

替换策略
- 随机算法(RAND):随机地确定替换的Cache块。实现比较简单,但没有依据程序访问的局部性原理,故可能命中率较低。(基本不考)
- 先进先出算法(FIFO): 选择最早调入的行进行替换。容易实现,但也没有依据程序访问的局部性原理,可能会把一些经常使用的程序块(如循环程序)也作为最早进入的Cache的块替换掉。
- 近期最少使用算法(LRU):依据程序访问的局部性原理选择近期内长久未访问过的存储行作为替换的行,平均命中率要比FIFO高,是堆栈类算法。LRU算法对每行设置一个计数器,Cache每命中一次,命中行计数器清零,而其他各行计数器均加1,需要替换时比较各特定行的计数值,将计数值最大的行换出。
- 最不经常使用算法(LFU):将一段时间内被访问次数最少的存储行换出。每行也设置一个计数器,新行建立后从0开始计数,每访问一次,被访问的行计数器加1,需要替换时比较各特定行的计数值,将计数值最小的行换出。
例题

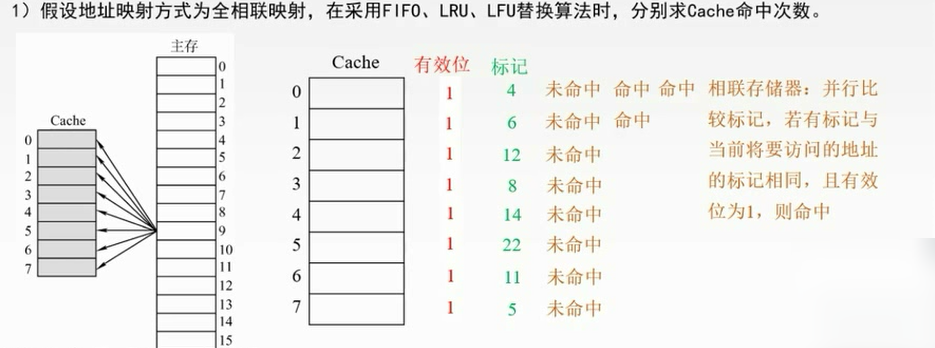
FIFO:把4替换掉
LRU:最近最少使用的是12,替换掉。从后往前数,最后那个就是最不常用的

LFU:4号块用了3次,6号块用了2次,其他均用了1次,需要更多的判断依据。换12

只命中了1次。
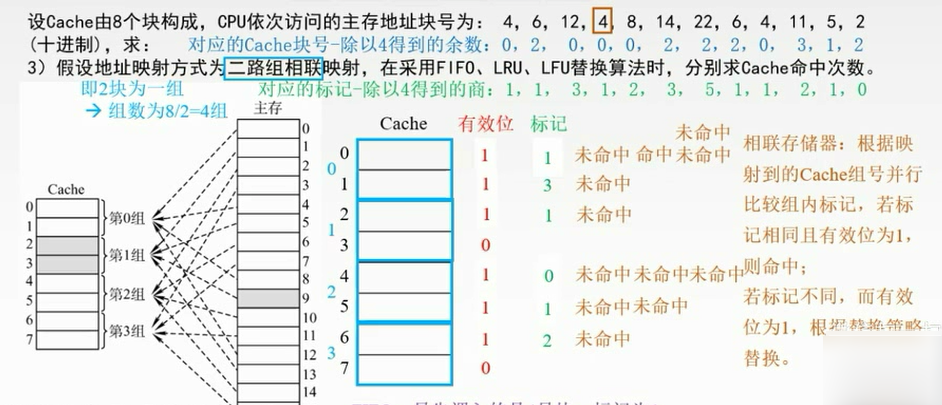
在组内是用不同的替换算法的。
FIFO:在第0组中,最先调入的是4号块,标记为1,命中0次
列表的方法。
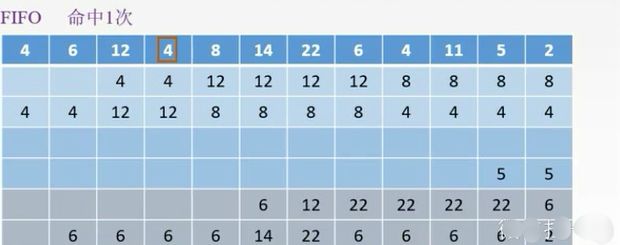
每次都放到每组的最下面,然后出去的就是先进先出的。
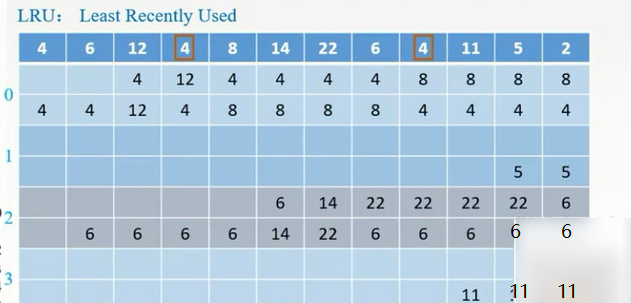
如果用了就把它移上去。
LFU:操作系统。
写策略
命中

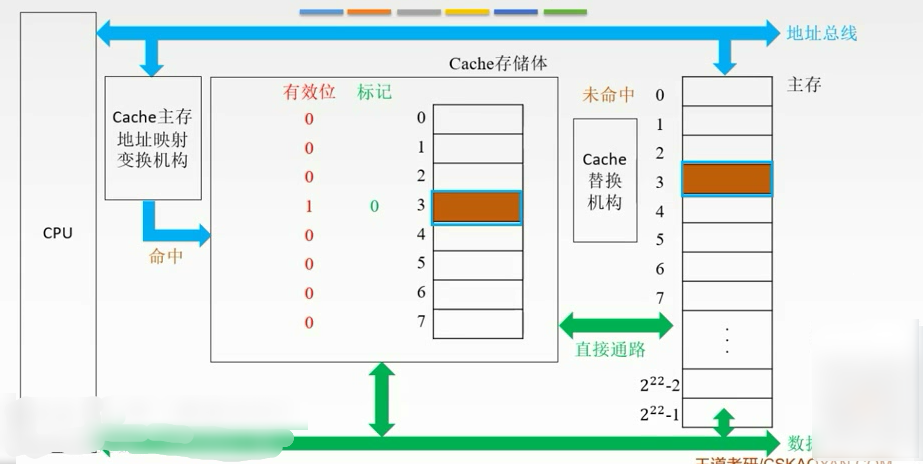
如果对Cache的内容进行修改,就要修改主存中对应的块。
命中:要访问的主存内容已经在Cache当中。
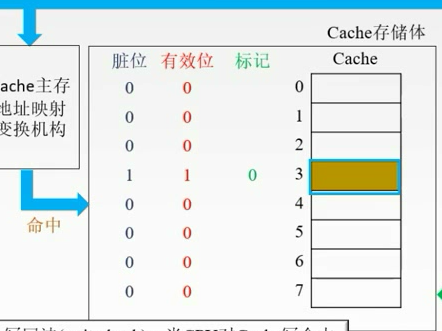
这块要被换掉之后才把主存的修改掉。写回法。加多一个脏位
写回法(write-back):当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。
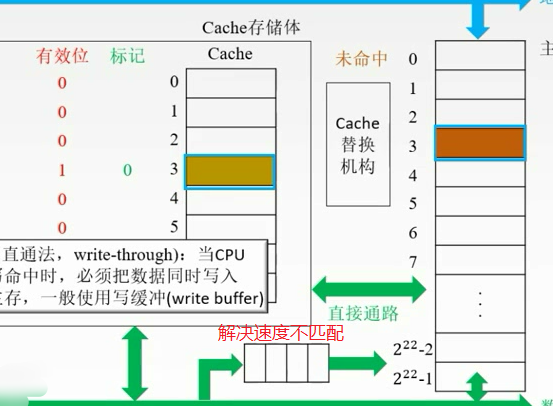
每次有修改就改,不用脏位了,但是增加访存次数。
全写法(write-through):当CPU对Cache写命中时,必须把数据同时写入Cache和主存,一般使用写缓冲(write buffer)
写的太频繁,会有队列的溢出。
未命中
写分配法(write-allocate):把主存中的块调入Cache,在Cache中修改,搭配写回法使用。
缺点:每次不命中都要从主存中读取块。
非写分配法(not-write-allocate):只写入主存,不调入Cache,搭配全写法使用。
小结
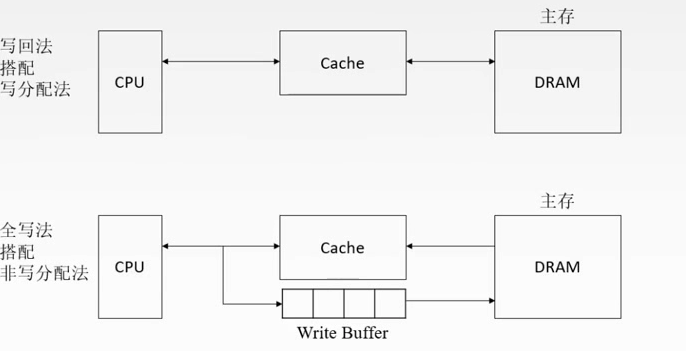
多级Cache
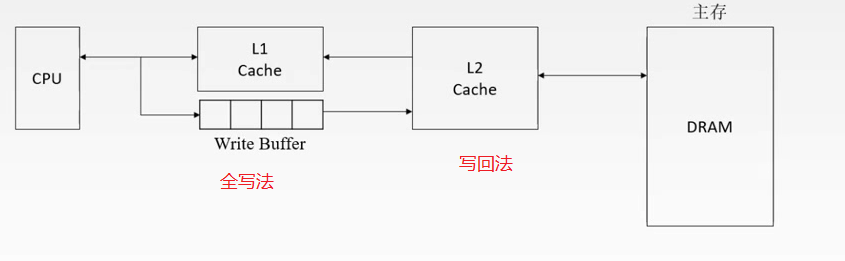
本节小结
高速缓冲存储器Cache的更多相关文章
- 7.2 高速缓冲存储器-Cache
高速缓冲存储器:Cache.Cache的功能是提高CPU数据的输入和输出的速率.CPU的速度与主存的速度之间有巨大的差异.主存的存取时间.存取速度要比CPU的速度要慢了很多倍.为了调和它们之间的巨大速 ...
- Cache高速缓冲存储器
Cache的命中率:命中Cache的次数比总访问次数 平均访问时间:t(Cache)X命中次数+t(未命中)X未命中次数 Cache与主存的映射方式: 直接映射 全相联映射 组相联映射 图片来源:ht ...
- Cache的原理、设计及实现
Cache的原理.设计及实现 前言 虽然CPU主频的提升会带动系统性能的改善,但系统性能的提高不仅仅取决于CPU,还与系统架构.指令结构.信息在各个部件之间的传送速度及存储部件的存取速度等因素有关,特 ...
- 转:Cache相关
声明:本文截取自http://blog.163.com/ac_victory/blog/static/1033187262010325113928577/ (1)“Cache”是什么 Cache(即高 ...
- 存储器结构、cache、DMA架构分析--【原创】
存储器的层次结构 高速缓冲存储器 cache 读cache操作 cache如果包含数据就直接从cache中读出来,因为cache速度要比内存快 如果没有包含的话,就从内存中找 ...
- [z]计算机架构中Cache的原理、设计及实现
前言 虽然CPU主频的提升会带动系统性能的改善,但系统性能的提高不仅仅取决于CPU,还与系统架构.指令结构.信息在各个部件之间的传送速度及存储部件的存取速度等因素有关,特别是与CPU/内存之间的存取速 ...
- Something about cache
http://www.tyut.edu.cn/kecheng1/2008/site04/courseware/chapter5/5.5.htm 5.5 高速缓冲存储器cache 随着CPU时钟速率的不 ...
- 操作系统-存储管理(3)高速缓存Cache
存储器的组织形式: 数据总是在相邻两层之间复制传送,最小传送单位是定长块,互为副本(不删除) ️指令和数据有时间局部性和空间局部性. 高速缓冲存储器Cache 介于CPU和主存储器间的高速小容量存 ...
- linux系统meminfo详解(待补充)
========================================================================================== MemTotal: ...
随机推荐
- 洛谷 P2101 命运石之门的选择 (分治)
P2101 命运石之门的选择 (分治) 介绍 El Psy Congroo 题目链接 没错,作为石头门厨,怎么能不做石头门的题呢?(在搜石头门的时 候搜到了本题) 本题作为一道分治基础练习题还是不错的 ...
- 详解Java锁的升级与对比(1)——锁的分类与细节(结合部分源码)
前言 之前只是对Java各种锁都有所认识,但没有一个统一的整理及总结,且没有对"锁升级"这一概念的加深理解,今天趁着周末好好整理下之前记过的笔记,并归纳为此博文,主要参考资源为&l ...
- 思维导图软件iMindMap怎么使用
人人都说,思维导图记忆法实用.可是,我们应该如何使用思维导图呢?又该如何从思维小白摇身一变成为逻辑大神呢?俗话说,心急吃不了热豆腐,让我们一步一步来,慢慢接触使用思维导图吧. 小编作为"过来 ...
- 使用Camtasia 让照片变身动态视频
视觉化影像已经慢慢渗入我们平日的生活了,很多人已经慢慢地从单纯的文字记录,发展到使用照片记录生活,而视频化的记录也随着智能手机的普及而迅速发展起来.对于一些曾经使用照片记录的瞬间,我们也可以将其变身为 ...
- 苹果电脑下载电影教程:如何用folx下载《小妇人》
由西尔莎罗南.艾玛沃特森等知名影星重新演绎的<小妇人>又带动了新一轮的<小妇人>热潮.这部由露易莎创作的长篇小说,曾被多次拍摄,无论是小说本身,还是其影视资源,都能让观众回味无 ...
- FL Studio时间面板讲解
今天我们一起来学习一下FL Studio时间面板的知识.看到这个名词我们一定就会想到该功能跟时间是脱不了关系的,是的,它就是用来显示时间的.它显示当前时间的方法不是很单一,而是有好几个,具体有哪几个下 ...
- 两种方式教你搞定在mac中格式化磁盘的问题
mac怎么格式化u盘?想必这是大部分苹果用户都会关心的一个问题.格式化u盘在我们日常工作中算是一个比较常规的操作了.但是在mac中随着系统版本不一样,格式化的方式也略有差别.今天,小编将以Mac OS ...
- Vegas教程:教你制作抖音热门人物穿越门窗特效
抖音上经常会有很多特效视频,例如换妆.分镜.合拍.放大等,合适的特效总是会让视频更加出彩.这些特效,除了一部分是抖音自带以外,很多都是用的其他视频特效软件制作而成.这些视频编辑软件操作简单易上手,强大 ...
- Arcgis基于高程(DEM)计算地形湿度指数(TWI),以及坡度(Slope)度单位转换为弧度
以30m*30m分辨率的图层为例 一.基于表面工具箱Surface计算Slope 1.如下图输入图层DEM,输出Slope 2.单位转换: Scale_slope=Slope*pi/180 二.基于水 ...
- Java高薪训练营(对标阿里P7,限时分享)
某钩Java高薪训练营(部分,持续更新) 下载地址 防止网盘和谐多次补链修改,公众号回复「训练营」自提.