Hadoop框架:HDFS简介与Shell管理命令
本文源码:GitHub·点这里 || GitEE·点这里
一、HDFS基本概述
1、HDFS描述
大数据领域一直面对的两大核心模块:数据存储,数据计算,HDFS作为最重要的大数据存储技术,具有高度的容错能力,稳定而且可靠。HDFS(Hadoop-Distributed-File-System),它是一个分布式文件系统,用于存储文件,通过目录树来定位文件;设计初衷是管理数成百上千的服务器与磁盘,让应用程序像使用普通文件系统一样存储大规模的文件数据,适合一次写入,多次读出的场景,且不支持文件的修改,适合做数据分析。
2、基础架构

HDFS具有主/从体系结构,有两个核心组件,NameNode与DataNode。
NameNode
负责文件系统的元数据(MetaData)管理,即文件路径名、数据块ID、存储位置等信息,并配置副本策略,处理客户端读写请求。
DataNode
执行文件数据的实际存储和读写操作,每个DataNode存储一部分文件数据块,文件整体分布存储在整个HDFS服务器集群中。
Client
客户端,文件切分上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;从NameNode获取文件的位置信息;与DataNode通信读取或者写入数据; Client通过一些命令来访问或管理HDFS。
Secondary-NameNode
不是NameNode的热备,但是分担NameNode工作量,比如定期合并Fsimage和Edits,并推送给NameNode;在紧急情况下,可辅助恢复NameNode。
3、高容错性
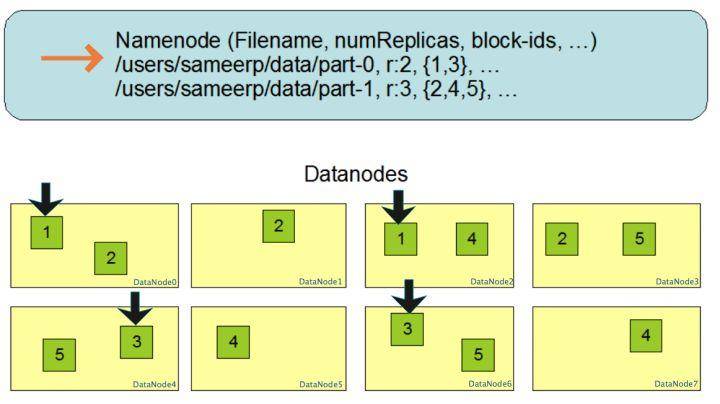
数据块多份复制存储的示意,文件/users/sameerp/data/part-0,复制备份设置为2,存储的block-ids分别为1、3;文件/users/sameerp/data/part-1,复制备份设置为3,存储的block-ids分别为2、4、5;任何单台服务器宕机后,每个数据块至少还存在一个备份服务存活,不会影响对文件的访问,提高整体容错性。
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过参数dfs.blocksize来配置,块设置太小,会增加寻址时间;块设置的太大,从磁盘传输数据的时间会很慢,HDFS块的大小设置主要取决于磁盘传输速率。
二、基础Shell命令
1、基础命令
查看Hadoop下相关Shell操作命令。
[root@hop01 hadoop2.7]# bin/hadoop fs
[root@hop01 hadoop2.7]# bin/hdfs dfs
dfs是fs的实现类
2、查看命令描述
[root@hop01 hadoop2.7]# hadoop fs -help ls
3、递归创建目录
[root@hop01 hadoop2.7]# hadoop fs -mkdir -p /hopdir/myfile
4、查看目录
[root@hop01 hadoop2.7]# hadoop fs -ls /
[root@hop01 hadoop2.7]# hadoop fs -ls /hopdir
5、剪贴文件
hadoop fs -moveFromLocal /opt/hopfile/java.txt /hopdir/myfile
## 查看文件
hadoop fs -ls /hopdir/myfile
6、查看文件内容
## 查看全部
hadoop fs -cat /hopdir/myfile/java.txt
## 查看末尾
hadoop fs -tail /hopdir/myfile/java.txt
7、追加文件内容
hadoop fs -appendToFile /opt/hopfile/c++.txt /hopdir/myfile/java.txt
8、拷贝文件
copyFromLocal命令和put命令相同
hadoop fs -copyFromLocal /opt/hopfile/c++.txt /hopdir
9、HDFS文件拷贝到本地
hadoop fs -copyToLocal /hopdir/myfile/java.txt /opt/hopfile/
10、HDFS内拷贝文件
hadoop fs -cp /hopdir/myfile/java.txt /hopdir
11、HDFS内移动文件
hadoop fs -mv /hopdir/c++.txt /hopdir/myfile
12、合并下载多个文件
基础命令get和copyToLocal命令效果相同。
hadoop fs -getmerge /hopdir/myfile/* /opt/merge.txt
13、删除文件
hadoop fs -rm /hopdir/myfile/java.txt
14、查看文件夹信息
hadoop fs -du -s -h /hopdir/myfile
15、删除文件夹
bin/hdfs dfs -rm -r /hopdir/file0703
三、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
推荐阅读:编程体系整理
| 序号 | 项目名称 | GitHub地址 | GitEE地址 | 推荐指数 |
|---|---|---|---|---|
| 01 | Java描述设计模式,算法,数据结构 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 02 | Java基础、并发、面向对象、Web开发 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆ |
| 03 | SpringCloud微服务基础组件案例详解 | GitHub·点这里 | GitEE·点这里 | ☆☆☆ |
| 04 | SpringCloud微服务架构实战综合案例 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 05 | SpringBoot框架基础应用入门到进阶 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆ |
| 06 | SpringBoot框架整合开发常用中间件 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 07 | 数据管理、分布式、架构设计基础案例 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
| 08 | 大数据系列、存储、组件、计算等框架 | GitHub·点这里 | GitEE·点这里 | ☆☆☆☆☆ |
Hadoop框架:HDFS简介与Shell管理命令的更多相关文章
- hadoop(十一)HDFS简介和常用命令介绍
HDFS背景 随着数据量的增大,在一个操作系统中内存不了了,就需要分配到操作系统的的管理磁盘中,但是不方便管理者维护,迫切需要一种系统来管理多态机器上的文件,这就是分布式文件管理系统. HDFS的概念 ...
- 【Hadoop】HDFS原理、元数据管理
1.HDFS原理 2.元数据管理原理
- Hadoop之HDFS(一)HDFS入门及基本Shell命令操作
1 . HDFS 基本概念 1.1 HDFS 介绍 HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统.是 Hadoop 核心组件之 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hdfs简单的shell命令
实验目的 了解bin/hadoop脚本的原理 学会使用fs shell脚本进行基本操作 学习使用hadoop shell进行简单的统计计算 实验原理 1.hadoop的shell脚本 当hadoop集 ...
- Hadoop框架之HDFS的shell操作
既然HDFS是存取数据的分布式文件系统,那么对HDFS的操作,就是文件系统的基本操作,比如文件的创建.修改.删除.修改权限等,文件夹的创建.删除.重命名等.对HDFS的操作命令类似于Linux的she ...
- Hadoop学习笔记(2)-HDFS的基本操作(Shell命令)
在这里我给大家继续分享一些关于HDFS分布式文件的经验哈,其中包括一些hdfs的基本的shell命令的操作,再加上hdfs java程序设计.在前面我已经写了关于如何去搭建hadoop这样一个大数据平 ...
- HDFS的基本shell操作,hadoop fs操作命令
(1)分布式文件系统 随着数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管 ...
- hadoop之hdfs命令详解
本篇主要对hadoop命令和hdfs命令进行阐述,yarn命令会在之后的文章中体现 hadoop fs命令可以用于其他文件系统,不止是hdfs文件系统内,也就是说该命令的使用范围更广可以用于HDFS. ...
- Hadoop集群常用的shell命令
Hadoop集群常用的shell命令 Hadoop集群常用的shell命令 查看Hadoop版本 hadoop -version 启动HDFS start-dfs.sh 启动YARN start-ya ...
随机推荐
- Windows五次Shift漏洞
本文首发于我的个人博客. 在小破站上看到了一个关于Windows五次shift的视频,觉得很有意思,就像拿来复现一下试试.原视频是在Window7虚拟机上进行的,由于现在基本上都已经用Win10了,我 ...
- vim编辑器 与etc目录
第1章 目录结构 1.1 vim vim故障 vim 是vi的升级版本 vi类似于文本文档 vim类似于notepad++ 编辑 必须先安装vim命令 yum -y insta ...
- Spine学习一 -渲染组件
一共有四个播放的组件: SkeletonAnimation:有点儿类似于 unity的 Animation,挂上一个spine资源,就可以跑了 SkeletonRenderer:SkeletonAni ...
- 记一次内存飙升的Windbg
背景 突然间接到运维的报警,我们一个服务,内存找过了6GB的占用.才6GB 也不是很大,因为在处理别的事情,服务dump一下暂时一放,然后半小时之后,接到了运维的Kafka堆积报警.然后切换着重启了一 ...
- 深入了解Netty【三】Netty概述
1.简介 Netty是一个异步事件驱动的网络应用程序框架,用于快速开发可维护的高性能协议服务器和客户端. Netty是一个NIO客户端服务器框架,它支持快速.简单地开发协议服务器和客户端等网络应用程序 ...
- Pandoanload涅槃重生,小白羊重出江湖?
Pandoanload涅槃重生,小白羊重出江湖? 科技是把双刃剑,一方面能够砸烂愚昧和落后,另一方面也可能带给人类无尽的灾难. 原子物理理论的发展是的人类掌握了核能技术但是也带来了广岛和长崎的核灾难, ...
- Eclipse的安装和配置
1. 下载Eclipse 前往Eclipse官网(https://www.eclipse.org/downloads/packages/)下载Eclipse: 这里下载的版本为: 这里给出该版本的百度 ...
- Explain Plan试分析
注:以下是本人对Explain Plan的试分析,有不对的地方希望大家指出.关于如何查看Oracle的解释计划请参考:https://www.cnblogs.com/xiandedanteng/p/1 ...
- CSS的坑
如何触发 bfc 规则 浮动元素:float 除 none 以外的值 绝对定位元素:position (absolute.fixed) display 为 inline-block.table-cel ...
- JAVA JDK 环境变量配置 入门详解 - 精简归纳
JAVA JDK 环境变量配置 入门详解 - 精简归纳 JERRY_Z. ~ 2020 / 9 / 13 转载请注明出处!️ 目录 JAVA JDK 环境变量配置 入门详解 - 精简归纳 一.为什么j ...