“计数质数”问题的常规思路和Sieve of Eratosthenes算法分析
题目描述
题目来源于 LeetCode 204.计数质数,简单来讲就是求“不超过整数 n 的所有素数个数”。
常规思路
一般来讲,我们会先写一个判断 a 是否为素数的 isPrim(int a) 函数:
bool isPrim(int a){
for (int i = 2; i < a; i++)
if (a % i == 0)//存在其它整数因子
return false;
return true;
}
然后我们会写一个 countIsPrim(int n) 来计算不超过 n 的所有素数个数:
int countPrimes(int n) {
int ans = 0;
for (int i = 2; i < n; i++)
if (isPrim(i)) ans++;
return ans;
}
显然这两个嵌套的 for 循环时间复杂度是 \(O(n^2)\) ,但是这样写有两个主要的问题:
isPrim()函数的计算冗余。首先,举个例子引入一下因子的对称性:12 = 2 × 6
12 = 3 × 4
12 = sqrt(12) × sqrt(12)
12 = 4 × 3
12 = 6 × 2
所以当循环判断一个数 \(a\) 是否有除了 1 和它本身之外其余的因子时,我们只需要将循环变量终止在 \(\sqrt a\) 的位置,而非
[2, a)的所有数。countPrimes(int n)函数的计算冗余。例如,一旦我们判断2为质数那么所有2的倍数一定都是质数,如果我们知道3是质数,那么所有3的倍数也一定都是质数。所以如果我们将[2, n)的数都进行一次isPrim(),那么将带来巨大的时间浪费。
我们在这里,先将第一个问题解决,即优化 isPrim() 函数:
bool isPrim(int n){
//根据因子对称性
for (int i = 2; i * i <= n; i++){
if (n % i == 0)//存在其它整数因子
return false;
}
return true;
}
采用 Sieve of Eratosthenes 算法高效实现
这个算法的中文叫作“埃拉托斯特尼筛法”,听起来很复杂,但是并不难理解,本质上就是把常规思路反过来,如下面动图所示:
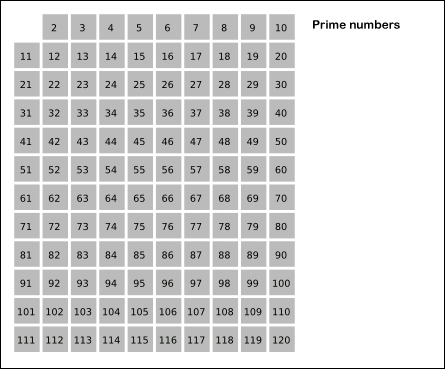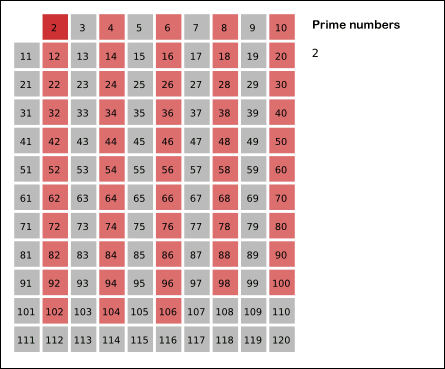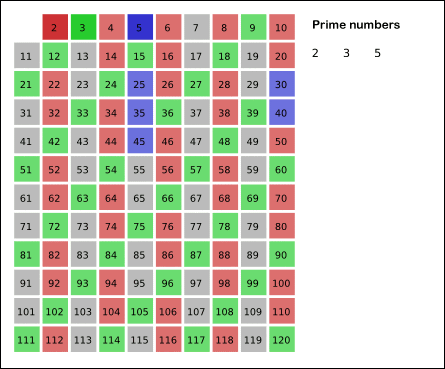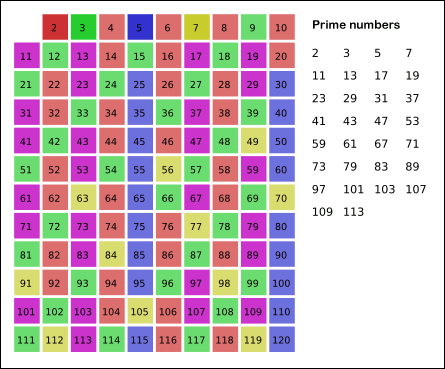
下面我们逐渐引出该算法的全貌:
常规思路就是将区间为 [2, n) 的数都遍历一遍,在过程中累加素数的个数。上述问题二已经说明了其低效性,根据“如果 i 是质数,那么所有 i 的倍数都不是质数”,我们做出优化:
int countPrimes(int n) {
vector<int> IsPrim(n + 1, true);
for (int i = 2; i < n; i++){
if (isPrim[i]){
//如果i是质数,那么所有i的倍数都不是质数
for (int j = 2 * i; j < n; j += i){
IsPrim[j] = false;
}
}
}
//遍历一遍计算结果
int ans = 0;
for (int i = 2; i < n; i++){
if (IsPrim[i]) ans++;
}
return ans;
}
这段代码展现了该算法的整体思路,但是还有两个细节可以优化:
- 由于因子的对称性,我们可以将外层 for 循环改为:
for (int i = 2; i * i < n; i++)。 - 将内层循环改为:
for (int j = i * i; j < n; j += i)。举个例子,n = 25,当i = 4时算法会标记 4 × 2 = 8,4 × 3 = 12 等等数字,但是这两个数字已经被i = 2和i = 3的 2 × 4 和 3 × 4 标记了。所以我们可以从平方项开始遍历。
到这里,Sieve of Eratosthenes 算法就已经实现了,下面给出完整的代码:
int countPrimes(int n) {
vector<int> prims(n + 1, 1);
for (int i = 2; i * i < n; i++){
if (isPrim[i]){
//如果i是质数,那么所有i的倍数都不是质数
for (int j = i * i; j < n; j += i){
prims[j] = 0;
}
}
}
//遍历一遍计算结果
int ans = 0;
for (int i = 2; i < n; i++){
if(prims[i]) ans++;
}
return ans;
}
Sieve of Eratosthenes 算法的证明
该算法的时间复杂度为 \(O(nloglogn)\) ,下面给出三个公式和证明:
\(Prerequisite\).
调和级数(Harmonic series)是一个发散的无穷级数,当 \(n\) 趋近于无穷大时,有一个近似公式:
\]
其中 \(\gamma\) 为欧拉常数,\(\gamma \approx 0.57721\)
泰勒级数(Taylor series)是1715年英国数学家布鲁克·泰勒提出的,在零点的导数求得的泰勒级数又叫麦克劳林级数,一个常用的泰勒级数如下:
\]
对任意 \(x \in [-1,1)\) 都成立。
欧拉乘积公式(Euler product)是著名的瑞士数学家欧拉于1737年在俄罗斯的圣彼得堡科学院发表的重要公式,为数学家研究素数的分布奠定了基础,即:
\]
其中 \(n\) 是自然数,\(p\) 为素数。
\(Prove.\)
该算法的运行时间可以看作筛除的次数之和:
\]
显然我们需要想办法处理后面的质数倒数和。我们拿出欧拉乘机公式,将所有的 \(s\) 用1来代替:
\]
两侧同时取对数:
\]
由于 \(-1< p^{-1} < 1\) ,所以对上面右侧求和的每一项进行泰勒展开得到:
\]
故得到:
\begin{equation}
\begin{split}
ln(\sum_{n}^{}\frac{1}{n}) &= \sum_{p}^{}\frac{1}{p} + \sum_{p}^{}\frac{1}{p^2}(\frac{1}{2} + \frac{1}{3p} + \frac{1}{4p^2}+\cdot\cdot\cdot)\\
&< \sum_{p}^{}\frac{1}{p} + \sum_p\frac{1}{p^2}(1+\frac{1}{p}+\frac{1}{p^2}+\cdot\cdot\cdot)\\
&= \sum_{p}^{}\frac{1}{p}+\sum_p\frac{1}{p(p-1)}\\
&= \sum_p\frac{1}{p} + C
\end{split}
\end{equation}
\]
上式左侧带入调和级数,当 \(n\) 趋向于无穷时得到:
\]
到这里就成功处理掉了质数倒数和,所以时间复杂度为 \(O(nloglogn)\) 。
耗时比较
未改进版 \(isPrim()\) 、改进版 \(isPrim()\) 、高效算法三者耗时对比如下,可以看出来差距还是很大的:
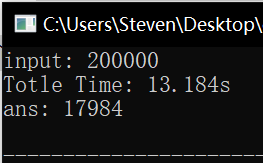
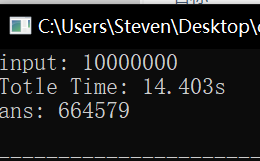
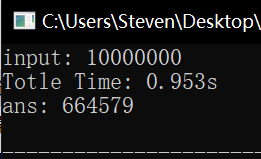
参考资料
“计数质数”问题的常规思路和Sieve of Eratosthenes算法分析的更多相关文章
- [LeetCode] 204. Count Primes 计数质数
Description: Count the number of prime numbers less than a non-negative number, n click to show more ...
- Leecode刷题之旅-C语言/python-204计数质数
/* * @lc app=leetcode.cn id=204 lang=c * * [204] 计数质数 * * https://leetcode-cn.com/problems/count-pri ...
- Leetcode 204计数质数
计数质数 统计所有小于非负整数 n 的质数的数量. 示例: 输入: 10 输出: 4 解释: 小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 . 比计算少n中素数的个数. 素数又称质 ...
- Java实现 LeetCode 204 计数质数
204. 计数质数 统计所有小于非负整数 n 的质数的数量. 示例: 输入: 10 输出: 4 解释: 小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 . class Solutio ...
- [原]素数筛法【Sieve Of Eratosthenes + Sieve Of Euler】
拖了有段时间,今天来总结下两个常用的素数筛法: 1.sieve of Eratosthenes[埃氏筛法] 这是最简单朴素的素数筛法了,根据wikipedia,时间复杂度为 ,空间复杂度为O(n). ...
- 埃拉托色尼筛法(Sieve of Eratosthenes)求素数。
埃拉托色尼筛法(Sieve of Eratosthenes)是一种用来求所有小于N的素数的方法.从建立一个整数2~N的表着手,寻找i? 的整数,编程实现此算法,并讨论运算时间. 由于是通过删除来实现, ...
- algorithm@ Sieve of Eratosthenes (素数筛选算法) & Related Problem (Return two prime numbers )
Sieve of Eratosthenes (素数筛选算法) Given a number n, print all primes smaller than or equal to n. It is ...
- 使用埃拉托色尼筛选法(the Sieve of Eratosthenes)在一定范围内求素数及反素数(Emirp)
Programming 1.3 In this problem, you'll be asked to find all the prime numbers from 1 to 1000. Prime ...
- Sieve of Eratosthenes时间复杂度的感性证明
上代码. #include<cstdio> #include<cstdlib> #include<cstring> #define reg register con ...
随机推荐
- PHP preg_replace_callback() 函数
preg_replace_callback 函数执行一个正则表达式搜索并且使用一个回调进行替换.高佣联盟 www.cgewang.com 语法 mixed preg_replace_callback ...
- Golang SQL连接池梳理
目录 一.如何理解数据库连接 二.连接池的工作原理 三.database/sql包结构 四.三个重要的结构体 4.1.DB 4.2.driverConn 4.3.Conn 五.流程梳理 5.1.先获取 ...
- [转]Nginx介绍-反向代理、负载均衡
原文:https://www.cnblogs.com/wcwnina/p/8728391.html 作者:失恋的蔷薇 1. Nginx的产生 没有听过Nginx?那么一定听过它的"同行&qu ...
- 04-Thread的生命周期
图示: 说明: 1.生命周期关注两个概念:状态.相应的方法 2.关注:状态a-->状态b:哪些方法执行了(回调方法) 某个方法主动调用:状态a-->状态b 3.阻塞:临时状态,不可以作为最 ...
- Java 循环语句及流程控制语句
java循环语句while与do-while 一 while循环 while循环语句和选择结构if语句有些相似,都是根据条件判断来决定是否执行大括号内的执行语句. 区别在于,while语句会反复地进行 ...
- Homekit_温湿度_人体红外_光强_传感器
市面上大多数,传感器产品多是简单的单个传感器进行售卖,这里我推荐一款四合一的产品,使用Homekit进行控制. 前置需求: 苹果手机一台 四合一传感器一个 USB数据线一根 介绍: 1.外观上是一个小 ...
- c++排序二叉树的出现的私有函数讨论,以及二叉树的删除操作详解
c++排序二叉树的出现的私有函数讨论, 以及二叉树的删除操作详解 标签(空格分隔): c++ 前言 我在c++学习的过程中, 最近打了一个排序二叉树的题目,题目中出现了私有函数成员,当时没有理解清楚这 ...
- 钉钉H5微应用
公司新项目要用到Vue+钉钉H5,在此记录一下免密登录: 引入插件: import * as dd from 'dingtalk-jsapi' import { login as loginUrl } ...
- 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书)
最近我出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Pyth ...
- 用过 mongodb 吧, 这三个大坑踩过吗?
一:背景 1. 讲故事 前段时间有位朋友在微信群问,在向 mongodb 中插入的时间为啥取出来的时候少了 8 个小时,8 在时间处理上是一个非常敏感的数字,又吉利又是一个普适的话题,后来我想想初次使 ...