爬虫入门六 总结 资料 与Scrapy实例-bibibili番剧信息
title: 爬虫入门六 总结 资料 与Scrapy实例-bibibili番剧信息
date: 2020-03-16 20:00:00
categories: python
tags: crawler
学习资料的补充。
和Scrapy的一个实例 bilibili番剧信息爬取。
1 总结与资料
1.1 基本知识
1、学习Python爬虫基础,安装PyCharm。
2、学习Scrapy框架。
相关官方链接:
Scrapy官网tutorial: https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
Requests官网文档: http://cn.python-requests.org/zh_CN/latest/
lxml官方文档: http://lxml.de/tutorial.html
python核心模块之pickle和cPickle讲解:http://www.pythonclub.org/modules/pickle
phantomJS进程不自动退出,需要手动添加:driver.quit(),
参考:http://www.jianshu.com/p/9d408e21dc3a
菜鸟教程(Python篇):https://www.runoob.com/python3/python3-tutorial.html
1.2 Xpath与re
1、学习Scrapy+XPath。
2、学习正则式
3、撰写实验报告1的part1.
相关官方链接:
XPath语法:http://www.w3school.com.cn/xpath/xpath_syntax.asp
Selectors:https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/selectors.html
2 实例 B站番剧信息爬取
参考: https://www.jianshu.com/p/530acc7b50d1?utm_source=oschina-app
2.1
新建工程。
crapy startproject bilibilianime
2.2 番剧索引
番剧索引链接 https://www.bilibili.com/anime/index/
F12控制台查看
可见相关信息:追番,会员,名称,话数都在
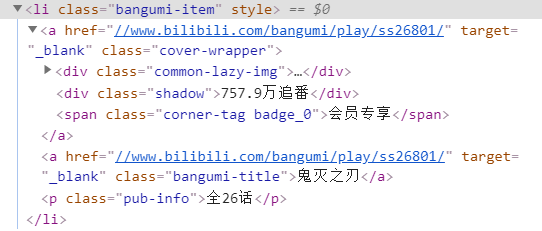
在Pycharm命令行调试Scrapy Xpath能否获取相关信息
scrapy shell "https://www.bilibili.com/anime/index" -s USER_AGENT='Mozilla/5.0'
response.xpath('//*[@class="bangumi-item"]//*[class="bangumi-title"]').extract()
out:[]
返回为空
View(response) 在浏览器查看,没问题
Reponse.text 查看内容,发现并没有相关信息
在浏览器F12,network抓包,xhr选项,右键保存为har到本地搜索。
在har文件查找鬼灭之刃
"text": "{\"code\":0,\"data\":{\"has_next\":1,\"list\":[{\"badge\":\"会员专享\",\"badge_type\":0,\"cover\":\"http://i0.hdslb.com/bfs/bangumi/9d9cd5a6a48428fe2e4b6ed17025707696eab47b.png\",\"index_show\":\"全26话\",\"is_finish\":1,\"link\":\"https://www.bilibili.com/bangumi/play/ss26801\",\"media_id\":22718131,\"order\":\"758万追番\",\"order_type\":\"fav_count\",\"season_id\":26801,\"title\":\"鬼灭之刃\",\"title_icon\":\
向上查找最近的request
"request": {
"method": "GET",
"url": "https://api.bilibili.com/pgc/season/index/result?season_version=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&year=-1&style_id=-1&order=3&st=1&sort=0&page=1&season_type=1&pagesize=20&type=1",
"httpVersion": "HTTP/1.1",
{"code":0,"data":{"has_next":1,"list":[{"badge":"会员专享","badge_type":0,"cover":"http://i0.hdslb.com/bfs/bangumi/9d9cd5a6a48428fe2e4b6ed17025707696eab47b.png","index_show":"全26话","is_finish":1,"link":"https://www.bilibili.com/bangumi/play/ss26801","media_id":22718131,"order":"758.1万追番","order_type":"fav_count","season_id":26801,"title":"鬼灭之刃","title_icon":""},{"badge":"会员专享","badge_type":0,"cover":"http://i0.hdslb.com/bfs/bangumi/f5d5f51b941c01f8b90b361b412dc75ecc2608d3.png","index_show":"全14话","is_finish":1,"link":"https://www.bilibili.com/bangumi/play/ss24588","media_id":102392,"order":"660.2万追番","order_type":"fav_count","season_id":24588,"title":"工作细胞","title_icon":""},{"badge":"会员专享",
...
...#略去
可见bilibili番剧索引页面是以api形式获取相关信息。其中sort,page_size..为设置的格式。
sort 0降序排列 1升序排列
order 3 追番人数排列 0更新时间 4最高评分 2播放数量 5开播时间
page 控制返回的Index
pagesize 20为默认,和网页上的一致 不过最多也就25
剩下的属性和网页右侧的筛选栏一致,也能猜出来了。

综上就可以用api获取索引
2.3 番剧详细信息
在上面查鬼灭之刃的时候有一条信息
https://www.bilibili.com/bangumi/play/ss26801","media_id":22718131
media_id为番剧id,而番剧详情页为
https://www.bilibili.com/bangumi/media/md22718131
可见只需要替换后面的id就可以获得每个番剧的详情
在鬼灭之刃的详情页,F12查看信息的节点
比如tags,,在class=media-tags的节点中
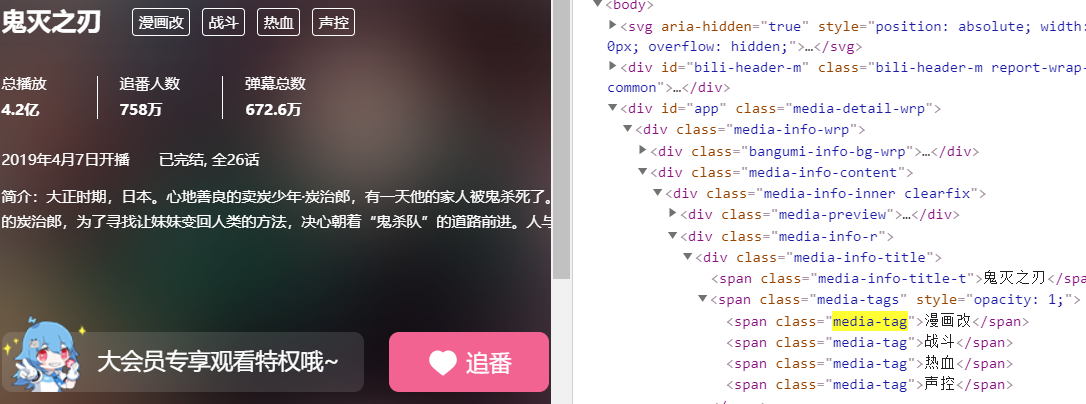
再尝试在scrapy shell能否xpath获取
>scrapy shell "https://www.bilibili.com/bangumi/media/md22718131" -s USER_AGENT='Mozilla/5.0'
response.xpath('//*[@class="media-tag"]/text()').extract()
发现可直接获得
In [1]: response.xpath('//*[@class="media-tag"]/text()').extract()
Out[1]: ['漫画改', '战斗', '热血', '声控']
但是,测试发现staff和声优无法直接xpath获取
就Reponse.text查看response
,"staff":"原作:吾峠呼世晴(集英社《周刊少年JUMP》连载)\\n监督:外崎春雄\\n角色设计:松岛晃\\n副角色设计:佐藤美幸、
梶山庸子、菊池美花\\n脚本制作:ufotable\\n概念美术:卫藤功二、矢中胜、竹内香纯、桦泽侑里\\n摄影监督:
"actors":"灶门炭治郎:花江夏树\\n灶门祢豆子:鬼头明里\\n我妻善逸:下野纮\\n嘴平伊之助:松冈祯丞\\n富冈义勇:樱井孝宏\\n鳞泷左近次:大冢芳忠\\n锖兔:
梶裕贵\\n真菰:加隈亚衣\\n不死川玄弥:冈本信彦\\n产屋敷耀哉:森川智之\\n产屋敷辉利哉:悠木碧\\n产屋敷雏衣:井泽诗织\\n钢铁冢萤:浪川大辅\\n鎹鸦:山崎巧\\n佛堂鬼:绿川光\\n手鬼:子安武人",
这些在一串json中。用re提取
比如声优
Import re
Actor=Re.compile(‘actors”:(.*?),’) #一直到 , 结束
Text=reponse.text
Re.findall(actors,text)
In [17]: actors=re.compile('actors":(.*?),')
In [18]: re.findall(actors,text)
Out[18]: ['"灶门炭治郎:花江夏树\\n灶门祢豆子:鬼头明里\\n我妻善逸:下野纮\\n嘴平伊之助:松冈祯丞\\n富冈义勇:樱井孝宏\\n鳞泷左近次:大冢芳忠\\n锖兔:梶裕贵\\n真菰:加隈亚衣\\n不死川玄弥:冈本信彦\\n产屋敷耀哉:森川智之\\n产屋敷辉利哉
:悠木碧\\n产屋敷雏衣:井泽诗织\\n钢铁冢萤:浪川大辅\\n鎹鸦:山崎巧\\n佛堂鬼:绿川光\\n手鬼:子安武人"']
包括评论、每集的标题等等都可以用re提取
2.4 索引页详细页面的转换处理
API每页包含20个子页面,API中还有这20个番剧的信息,并且需要根据API来判断是否把所有番剧爬完了。
https://blog.csdn.net/u012150179/article/details/34486677
https://www.zhihu.com/question/30201428
参考上述处理:
如何获取http://a.com中的url,同时也获取http://a.com页面中的数据?
可以直接在parse方法中将request和item一起“返回”,并不需要再指定一个parse_item例如:
def parse(self, response):
#do something
yield scrapy.Request(url, callback=self.parse)
#item[key] = value
yield item
2.5 其他
-o输出注意编码 utf-8,gb18030
2.6 code
settings.py
BOT_NAME = 'bilibilianime'
SPIDER_MODULES = ['bilibilianime.spiders']
NEWSPIDER_MODULE = 'bilibilianime.spiders'
FEED_EXPORT_ENCODING = "gb18030"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'bilibilianime (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
items.py
import scrapy
class BilibilianimeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
badge= scrapy.Field()
badge_type= scrapy.Field()
is_finish= scrapy.Field()
media_id= scrapy.Field()
index_show= scrapy.Field()
follow= scrapy.Field()
play= scrapy.Field()
pub_date= scrapy.Field()
pub_real_time= scrapy.Field()
renewal_time= scrapy.Field()
score= scrapy.Field()
season_id= scrapy.Field()
title = scrapy.Field()
tags= scrapy.Field()
brief= scrapy.Field()
cv= scrapy.Field()
staff= scrapy.Field()
count= scrapy.Field()
pass
bilibili.py (spider)
import scrapy
import logging
from scrapy import Request
from bilibilianime.items import BilibilianimeItem
import re
import json
class MySpider(scrapy.Spider):
name = 'bilibili'
allowed_domains = ['bilibili.com']
url_head = 'https://bangumi.bilibili.com/media/web_api/search/result?season_version=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&pub_date=-1&style_id=-1&order=3&st=1&sort=0&season_type=1'
start_urls = [url_head+"&page=1"]
# 先处理列表中的番剧信息
def parse(self, response):
self.log('Main page %s' % response.url,level=logging.INFO)
data=json.loads(response.text)
next_index=int(response.url[response.url.rfind("=")-len(response.url)+1:])+1
if(len(data['result']['data'])>0):
# 发出Request 处理下一个网址
next_url = self.url_head+"&page="+str(next_index)
yield Request(next_url, callback=self.parse)
medias=data['result']['data']
for m in medias:
media_id=m['media_id']
detail_url='https://www.bilibili.com/bangumi/media/md'+str(media_id)
yield Request(detail_url,callback=self.parse_detail,meta=m)
# 再处理每个番剧的详细信息
def parse_detail(self, response):
item = BilibilianimeItem()
item_brief_list=['badge','badge_type','is_finish','media_id','index_show','season_id','title']
item_order_list=['follow','play','pub_date','pub_real_time','renewal_time','score']
m=response.meta
for key in item_brief_list:
if (key in m):
item[key]=m[key]
else:
item[key]=""
for key in item_order_list:
if (key in m['order']):
item[key]=m['order'][key]
else:
item[key]=""
tags=response.xpath('//*[@class="media-tag"]/text()').extract()
tags_string=''
for t in tags:
tags_string=tags_string+" "+t
item['tags']=tags_string
item['brief'] = response.xpath('//*[@name="description"]/attribute::content').extract()
#detail_text = response.xpath('//script')[4].extract() 这里原来的代码有bug,应该是想缩小搜索区域加速,但是出了问题
detail_text = response.text
actor_p = re.compile('actors":(.*?),')
ratings_count_p = re.compile('count":(.*?),')
staff_p = re.compile('staff":(.*?),')
item['cv'] = re.findall(actor_p,detail_text)[0]
item['staff'] = re.findall(staff_p,detail_text)[0]
count_list=re.findall(ratings_count_p,detail_text)
if(len(count_list)>0):
item['count'] = count_list[0]
else:
item['count']=0
# self.log(item)
return item
2.7 输出
scrapy crawl bilibili -o bilibilianime.csv
调用api时使用默认参数,所以是按照追番人数排序
结果:

3 其他实例
https://www.cnblogs.com/xinyangsdut/p/7628770.html 腾讯社招
https://blog.csdn.net/u013830811/article/details/45793477 亚马逊.cn
https://github.com/Mrrrrr10/Bilibili_Spider 哔哩哔哩
https://blog.csdn.net/weixin_42471384/article/details/83049336
爬虫入门六 总结 资料 与Scrapy实例-bibibili番剧信息的更多相关文章
- Python爬虫入门六之Cookie的使用
大家好哈,上一节我们研究了一下爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 6.Python爬虫入门六之Cookie的使用
大家好哈,上一节我们研究了一下爬虫的异常处理问题,那么接下来我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在 ...
- python爬虫入门六:Selenium库
在我们爬取网页过程中,经常发现我们想要获得的数据并不能简单的通过解析HTML代码获取,这些数据是通过AJAX异步加载方式或经过JS渲染后才呈现在页面上显示出来. selenuim是一种自动化测试工具, ...
- Python爬虫入门之Cookie的使用
本节我们一起来看一下Cookie的使用. 为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要 ...
- 爬虫练习四:爬取b站番剧字幕
由于个人经常在空闲时间在b站看些小视频欢乐一下,这次就想到了爬取b站视频的弹幕. 这里就以番剧<我的妹妹不可能那么可爱>第一季为例,抓取这一番剧每一话对应的弹幕. 1. 分析页面 这部番剧 ...
- 爬虫入门三 scrapy
title: 爬虫入门三 scrapy date: 2020-03-14 14:49:00 categories: python tags: crawler scrapy框架入门 1 scrapy简介 ...
- 爬虫入门scrapy
Python之路[第十九篇]:爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用 ...
- Python爬虫入门教程 37-100 云沃客项目外包网数据爬虫 scrapy
爬前叨叨 2019年开始了,今年计划写一整年的博客呢~,第一篇博客写一下 一个外包网站的爬虫,万一你从这个外包网站弄点外快呢,呵呵哒 数据分析 官方网址为 https://www.clouderwor ...
随机推荐
- C# datagridview设置标题为汉语
正常情况下,在给datagridview绑定数据源之后,显示的是SQL语句中的栏位,如下 我们想让标题显示汉语,可以有一下两种方法 1.在SQL中设置列别名 SELECT TITLE AS '报警标题 ...
- 萌新入门之python基础语法
首先我们先了解一些python最最基础的入门 1.标识符 定义:我们写代码的时候自己取得名字比如项目名,包名,模块名这些: 规范:1.数字/字母/下划线组成,不能以数字开头 2.起名字要见名知意 3. ...
- 误删除SAP ECC中的profile文件
环境:ECC6.0 EHP4 FOR ORACLE ON WINDWS X64下 今天在RZ10配置系统参数文件的时候,不小心错删除了instance profile文件,这下惨了,这是操作系统层级 ...
- 判断最长回文串——暴力、延展、Manacher
1. 暴力 时间复杂度O(n^3). 2. 延展 以某一字符为中心,设置left, right两个变量同时向外扩,判断他们指向字符是否相同.注意分奇偶讨论.时间复杂度O(n^2). 3. Manach ...
- HTML基础复习2
6.表格 6.1建立表格: 表格由<table></table>标签来定义 每行由<tr></tr>来定义,每行被分割为若干单元格,由<td> ...
- 如何在C#中使用MSMQ
MSMQ (Microsoft消息队列)是Windows中默认可用的消息队列.作为跨计算机系统发送和接收消息的可靠方法,MSMQ提供了一个可伸缩.线程安全.简单和使用方便的队列,同时为你提供了在Win ...
- 解决Python内CvCapture视频文件格式不支持问题
解决Python内CvCapture视频文件格式不支持问题 在读取视频文件调用默认的摄像头cv.VideoCapture(0)会出现下面的视频格式问题 CvCapture_MSMF::initStre ...
- Py装饰器
装饰器: 1.定义,什么是装饰器 装饰器本质是一个函数,它是为了给其他函数添加附加功能 2.装饰器的两个原则 原则1 不修改被修饰函数的源代码原则2 不修改被修饰函数的调用方式 3.首先来看一 ...
- (03)-Python3之--元组(tuple)操作
1.定义 元组的关键字:tuple 元组以()括起来,数据之间用 , 隔开.元组当中的数据,可以是任意类型.数值是可以重复的. 元组元素是 不可变的,顺序是 有序的. 例如: b = ("萝 ...
- 阿姆达尔定律 Amdahl's law
Amdahl's law - Wikipedia https://en.wikipedia.org/wiki/Amdahl%27s_law 阿姆达尔定律(英语:Amdahl's law,Amdahl' ...