Cassandra + JSON?答案就是Stargate Documents API
JSON已经被开发者在很多场景中频繁使用,但是其实将Cassandra用于JSON或其他面向文档的用例并不容易。
为了让开发者在使用原生的JSON的同时还能享受Cassandra带来的可靠性和伸缩性,我们开发了Stargate Cassandra Documents API——它使得绝大多数的Cassandra发行版本都能通过一个REST API使用JSON。
如果你像我一样,当你开始编写一些新应用程序时,你可能会发现你自己在使用JSON。也许你正在使用Node.js或Python或任何其他动态编程语言(dynamic programming language),这些语言原生的数据格式正巧与JSON类似;或者你正使用从REST API中拉取的数据。
无论是哪种情况,越来越多的情况是所有的新应用程序都会在某个点与JSON汇合。大多数时候这不是个问题,这只是我们如今建构软件的方式而已。然而有一个问题——Cassandra其实不是特别擅长处理JSON……
如果深入了解一下,你会知道问题并不在于JSON这种数据格式本身,虽然Cassandra并没有让JSON变得更易于使用;问题在于大多数程序员在建构程序时使用JSON的方式。
迭代开发意味着计划经常会改变。比如用户注册表格需要一些新的条目,前端开发人员就率先加入了这些条目。当我们使用这个API时,就会有一些额外的数据被返回。欢迎来到这个松耦合(loosely coupled)的世界,所有的一切都是开心和有趣的——直到我的应用程序需要把这些数据发送到数据库。
其实早期的Cassandra版本要做到这件事很容易,但是随着这个项目逐渐成熟,像是对企业友好的类SQL查询语言以及更好的索引等功能被加入之后,意味着我们需要Cassandra数据库要有一个固定的模式(schema)。逐渐地,将Cassandra用于类似JSON的事情或其他面向文档的用例变得越来越困难。
进入Stargate(意为“星际之门”)——如果你只需知道一件关于Stargate团队的事情,那应该就是:我们的个人使命是让Cassandra变得对于每个开发人员来说都易于使用。想办法让Javascript的开发者在使用原生的JSON的同时还能享受Cassandra带来的可靠性和伸缩性——这是一个我们不能错过的挑战。
也正是这个想法催生了Stargate Documents API——它使得绝大多数的Cassandra发行版本(Cassandra 3.11, Cassandra 4.0, and DataStax Enterprise 6.8)都能通过一个REST API使用JSON。
01 Stargate Documents API的特点和设计
当我们刚开始构建这个API的框架时,我们意识到Cassandra完全不像是一个文档数据库。
表达一行一行的数据是非常直观简单的,但是表达树状结构的JSON数据就没那么容易了。另外如果还想做到将JSON数据映射到Stargate管理的数据库表,并保证读取和写入的速度还保持在相当快的水准,这就更是复杂了。
基于这些,为了能够达成目标,我们详细计划了三个主要的设计考量:基于Cassandra的文档建模、高效处理读写请求,以及合理处理删除操作。
接下来,这篇文章将介绍我们是如何构想每一个设计以及解决遇到的一些小问题的。
02 基于文档切分(Document Shredding)在Cassandra中进行文档建模
我们要决定的第一件事就是管理基于文档集合(document collection)的数据库表的模式(schema)。在与几位Cassandra专家进行了有建设性的讨论后,我们决定当用户创建一个文档,就会用下面的语句创建一个相应的数据库表:
create table <name> (
key text,
p0 text,
… p[N] text,
bool_value boolean,
txt_value text,
dbl_value double,
leaf text
)
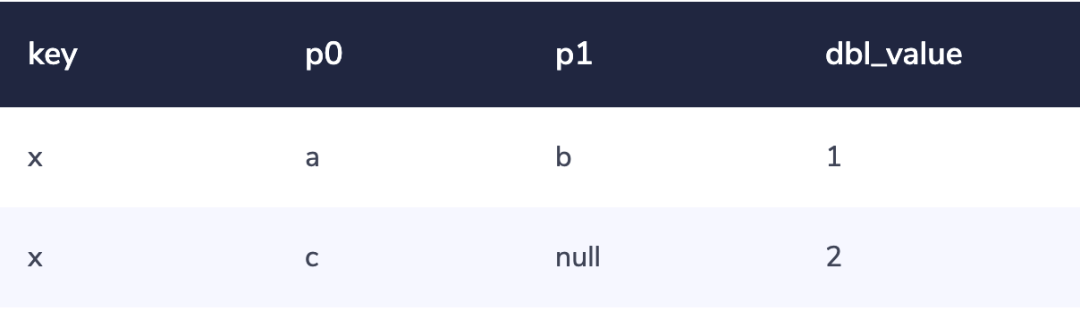
到这里,我们得要解决长度无上限的数据模型带来的问题。因为所有有[N]或更少深度的JSON文档都可以被加入到这个表中,JSON中的每一个值将会在表中存储为一行。所以如果我想表示一个叫做“x”的含有JSON的文档:
{"a": { "b": 1 }, "c": 2}
这个文档将会被“切分”成像这样的行:
对于包含数组(array)的数据,比如:
{"a": { "b": 1 }, "c": [{"d": 2}]}
就会被拆分成这样的两行:
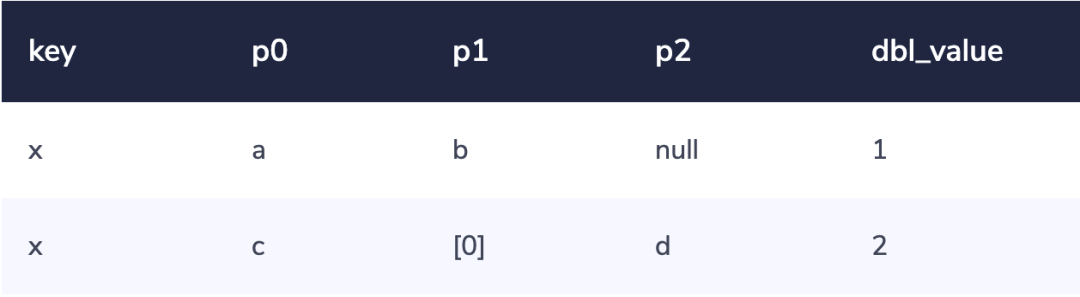
数组元素在存储时,会在一列中被方括号括起来。
03 高效处理读写请求
下一个出现的问题是:想要更新一个文档,自然而然就要先从数据库中读取已有的文档,看看要对其做些什么改变,然后再写入更新的数据。
对大多数数据存储来说,这个“写前读(read-before-write)”的过程是臭名昭著的影响性能和一致性的问题的根源。因此,我们决心要不惜一切避免任何“写前读”的操作。
有一个具体的实现细节很有意思——当你向文档写入一些数据时,这个写入操作其实只是一个包含了一些插入操作和删除操作的简单的批处理。在某些情况下,这会导致文档在数据库中对应的行针对同一个JSON数据域,可能会显示出两种不同的状态。
然后,当这些行都被读取出来之后,Stargate的Cassandra Documents API就会选取写入时间戳比较新的数据,从而调和冲突的信息(这和Cassandra本身的原理很类似)。
这让我们的写入操作变得很快,同时不必在读取操作方面牺牲太多——因为前面所说的这种需要冲突调和的情况并不多见,即使出现,也会很快被解决。对于我们基础的读写操作,这也奠定了非常重要的核心原则:
每一个向一个单独的文档所做的写入操作,都是一个单独的、含有多个语句的批处理。
每一个向一个单独的文档所做的读取操作,都是一个单独的SELECT语句。
读操作和写操作都准备就绪了,那删除操作呢?
04 合理处理删除
由于Cassandra数据库本身的分布式属性,在Cassandra中做删除操作其实与插入操作很类似。不过删除操作所做的,是在特定的写入时间通过写入“tombstone(墓碑)”来标志一行数据的死亡。
入土为安吧……等等,事情其实还没结束——
Cassandra会周期性地做压实(compaction)操作(这个频率取决于你的压实策略和/或集群负载),从而删除墓碑并释放压力。所以避免让Cassandra过载的唯一方法就是确保删除操作的频率足够的低。
由于数组的存在,删除操作给Stargate的Cassandra Documents API带来了一个问题。现在让我们来谈谈这点。
想象一下,如果你有一个行,其中的某个单元是一个长度为十万个元素的数组。然后如果你进行一个更新操作(通过HTTP中的PUT方法)并决定给这个单元赋值为一个新的数组。结果就是整个十万行的数据都要被删除,也就是说整整十万个墓碑要被写入系统。
这么多墓碑在一次操作中被写入,其数量相当之大。如果你再多这么操作几次,Cassandra很可能会变得非常之慢。所以,我们还需要对每个表的数据结构再做一次大的调整。
我们前面提到过,存在数据库中的数组访问路径(array path)是带方括号的。比如数组序列为0的元素会被存储为[0]。这将意味着像下面这样删除100,000个元素:
DELETE FROM <name> where p0 in ('[0]', '[1]', '[2]', …, '[99999]')
这就导致了100,000个墓碑将被写入。
相比这么做,我们决定向所有的数组元素的开头都充填多个0——也就是说索引序号为0的元素会被记作[000000],而索引序号为99999的元素会被表示记作[099999]。通过这种方式,我们可以将删除语句改成这样:
DELETE FROM <name> where p0 >= '[000000]' and p0 <= '[999999]'
相比100,000个单元的墓碑,这种方式会使得只有一个所谓的“区间”墓碑(range tombstone)会被写入(提示:在Cassandra中,大于号和小于号可以依照字典顺序作用于字符串类型的数据)。这也将数组长度限制放宽至一百万个元素,这可真是相当巧妙!
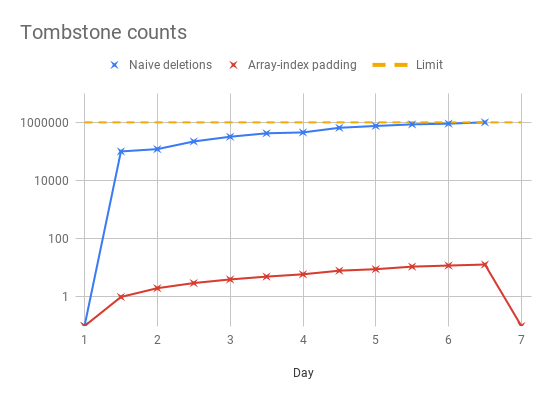
下方的时间序列图显示了在你以每周一次的频率做压实操作的前提下,旧方法和新方法的效果对比:
相比100,000个单元的墓碑,这种方式会使得只有一个所谓的“区间”墓碑(range tombstone)会被写入(提示:在Cassandra中,大于号和小于号可以依照字典顺序作用于字符串类型的数据)。这也将数组长度限制放宽至一百万个元素,这可真是相当巧妙!
下方的时间序列图显示了在你以每周一次的频率做压实操作的前提下,旧方法和新方法的效果对比:
05 简单了解此API的性能
️在开始这个部分之前,我们想先提一下:虽然基准测试是非常好的工具,但并非能绝对说明一个系统在自然条件和真实负载下的表现。另外,我们也还没在同一硬件上,将拥有此API加成的Cassandra与其它文档数据库进行对比……是的,还没有。好吧,让我们现在就来看看它的性能!
为了测试我们的Cassandra Documents API是否足够的快,我们用一个单独的Cassandra存储节点和一个单独的Stargate节点进行了一次基准测试(Stargate是包含了Cassandra Documents API的API)。
然后我们进行了两个不同的基准测试,一个用HTTP GET重复地在一个文档中随机获取路径,另一个用HTTP POST重复地创建新的文档。这两个操作都分别进行了100,000次,下面的图中展示了这次测试的结果。
简单来说,由于现在并没有可以用于对比的基准数据,这次基准测试中分为这样三种情况:一次只有一个用户、稍微多一些并发操作(一次10个用户)、更多的并发操作(一次100个用户)。
需注意,此处我们在后端只有一个节点,更多的并发操作会引起性能的退化(degradation in performance)。如果想要承载更高程度的并发请求,你应该使用多个节点。
下面的是读操作的测试结果:
️在开始这个部分之前,我们想先提一下:虽然基准测试是非常好的工具,但并非能绝对说明一个系统在自然条件和真实负载下的表现。另外,我们也还没在同一硬件上,将拥有此API加成的Cassandra与其它文档数据库进行对比……是的,还没有。好吧,让我们现在就来看看它的性能!
为了测试我们的Cassandra Documents API是否足够的快,我们用一个单独的Cassandra存储节点和一个单独的Stargate节点进行了一次基准测试(Stargate是包含了Cassandra Documents API的API)。
然后我们进行了两个不同的基准测试,一个用HTTP GET重复地在一个文档中随机获取路径,另一个用HTTP POST重复地创建新的文档。这两个操作都分别进行了100,000次,下面的图中展示了这次测试的结果。
简单来说,由于现在并没有可以用于对比的基准数据,这次基准测试中分为这样三种情况:一次只有一个用户、稍微多一些并发操作(一次10个用户)、更多的并发操作(一次100个用户)。
需注意,此处我们在后端只有一个节点,更多的并发操作会引起性能的退化(degradation in performance)。如果想要承载更高程度的并发请求,你应该使用多个节点。
下面的是读操作的测试结果:

下面的是写操作的测试结果:
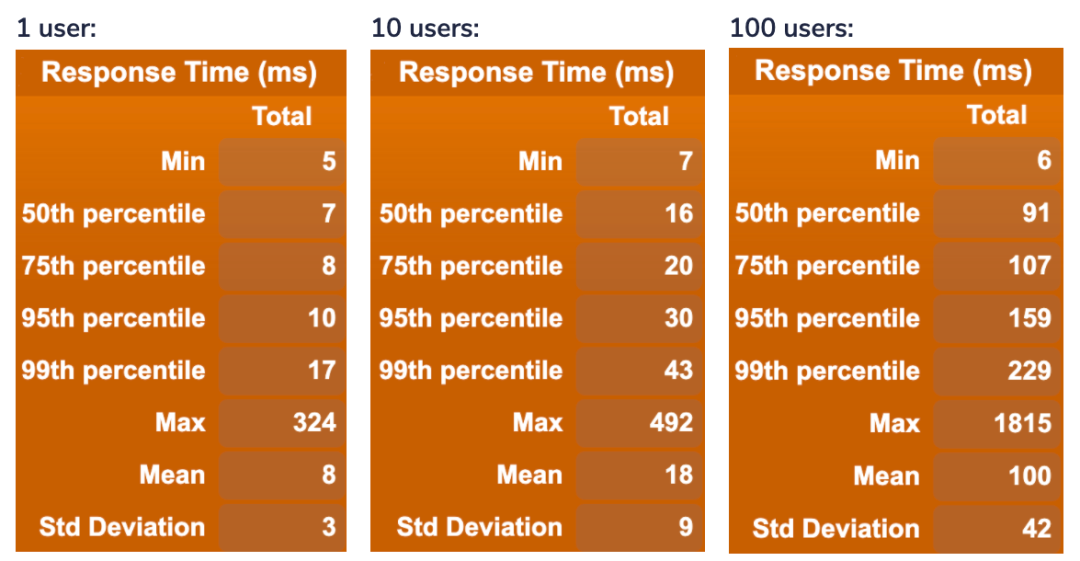
从上面的结果中,我们可以看到在我们设置的一定程度上的并发操作下,Stargate的Cassandra Documents API表现相当不错。
06 结束语
我们希望你享受这篇对于Stargate Cassandra Documents API的快速介绍。如果你对使用这个API有兴趣,不妨点击文末“阅读原文”前往Stargate.io查看更多相关信息,看看如何将这个API用在你自己的Cassandra系统中。
来加入我们的Discord Community,你可以在此获取Stargate的最新动态,并且最先使用Stargate的新功能
https://discord.com/invite/5gY8GDB
如果你有任何问题或是想要提交任何代码,来看看我们的GitHub仓库吧
https://github.com/stargate/stargate
Stargate的Cassandra Documents API正在被积极开发中,我们盼望着很快带给你有关更多提升改进的新消息!
Cassandra + JSON?答案就是Stargate Documents API的更多相关文章
- 使用Jil序列化JSON提升Asp.net web api 性能
JSON序列化无疑是Asp.net web api 里面性能提升最重要的一环. 在Asp.net web api 里面我们可以插入自定义的MediaTypeFormatter(媒体格式化器), 说白了 ...
- 对象转换为json格式,类似中间层API
<一头扎进SpringMvc视频教程\<一头扎进SpringMvc>第四讲 源码\> 对象自动转换为json格式要在 spring-mvc.xml添加一个东西 ,和对应的命名空 ...
- 技术基础 | 用JSON在抖音上发布动态——使用Stargate即可轻松实现
Cassandra是世界上经受住最多实战考验的数据库,通过其快速且易于使用的数据API,让你的程序开发升级. 本文将介绍什么是Stargate以及Stargate的最新进展,如果您想快速浏览相关代码和 ...
- [译] 在Web API 2 中实现带JSON的Patch请求
原文链接:The Patch Verb in Web API 2 with JSON 我想在.NET4.6 Web API 2 项目中使用Patch更新一个大对象中的某个字断,这才意识到我以前都没有用 ...
- gRPC helloworld service, RESTful JSON API gateway and swagger UI
概述 本篇博文完整讲述了如果通过 protocol buffers 定义并启动一个 gRPC 服务,然后在 gRPC 服务上提供一个 RESTful JSON API 的反向代理 gateway,最后 ...
- [py]requests+json模块处理api数据,flask前台展示
需要处理接口json数据,过滤字段,处理字段等. 一大波json数据来了 参考: https://stedolan.github.io/jq/tutorial/ https://api.github. ...
- ASP.NET Core WebApi使用Swagger生成api说明文档看这篇就够了
引言 在使用asp.net core 进行api开发完成后,书写api说明文档对于程序员来说想必是件很痛苦的事情吧,但文档又必须写,而且文档的格式如果没有具体要求的话,最终完成的文档则完全取决于开发者 ...
- PJSUA2开发文档--第十二章 PJSUA2 API 参考手册
12 PJSUA2 API 参考手册 12.1 endpoint.hpp PJSUA2基本代理操作. namespace pj PJSUA2 API在pj命名空间内. 12.1.1 class En ...
- ASP.NET Core WebApi使用Swagger生成api
引言 在使用asp.net core 进行api开发完成后,书写api说明文档对于程序员来说想必是件很痛苦的事情吧,但文档又必须写,而且文档的格式如果没有具体要求的话,最终完成的文档则完全取决于开发者 ...
随机推荐
- css选择器 兄弟选择器 相邻兄弟选择器 子元素选择器
1.兄弟选择器: ~ 该选择器会选择当前元素之后的所有相邻指定元素(具有相同父元素的兄弟元素): .p ~ li{ color: blue; } <div> <p class=&qu ...
- C# 将Excel里面的数据填充到DataSet中
/// <summary> /// 将Excel表里的数据填充到DataSet中 /// </summary> /// <param name="filenam ...
- linux(CentOS7)_离线_mysql安装
注意:本文系统环境 CentOS 7.7 64位 MySQL Community Server 5.7.32 一丶卸载CentOS7系统中默认的数据库mariadb 原因一:ps原作者的话介绍下背景: ...
- linux上安装mitmproxy
一.去git上下载安装包 下载mitmproxy二进制安装包:https://github.com/mitmproxy/mitmproxy/releases/ 二.安装 #上传 rz 安装包的本地路径 ...
- slf4j -->log4j --> logback -->log4j2
slf4j是一个接口:log4j\logback\log4j2是slf4j接口的持续更新的日志框架实现类:按照面向接口编程,java中导入slf4j最好,可以持续更新日志框架实现类. 详细情况见链接 ...
- JUC---11单例模式
一.什么是单例模式 单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一.这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式.这种模式涉及到一个单一的类,该 ...
- python爬虫 学习1
1 import requests 2 from bs4 import BeautifulSoup 3 import bs4 4 def gethtmltext(url): #获取html内容,利用t ...
- Java安全之Commons Collections7分析
Java安全之Commons Collections7分析 0x00 前言 本文讲解的该链是原生ysoserial中的最后一条CC链,但是实际上并不是的.在后来随着后面各位大佬们挖掘利用链,CC8,9 ...
- StrongArray
* System类中包含了一个static void arraycopy(object src,int srcops,object dest ,int destpos, int length )方法, ...
- git提交后文件夹显示灰色无法打开的解决办法
上传完本地文件到gitee线上后发现如下情况,文件夹显示为灰色并且无法访问. xxx@xxx 的灰色文件 问题原因 : 无法点击的灰色文件夹中含有 .git 文件 即在本地初始化的仓库(使用 git ...