R语言学习4:函数,流程控制,数据框重塑
本系列是一个新的系列,在此系列中,我将和大家共同学习R语言。由于我对R语言的了解也甚少,所以本系列更多以一个学习者的视角来完成。
参考教材:《R语言实战》第二版(Robert I.Kabacoff),书中所提到的John Cook的优秀博文,关于代码规范的《来自Google的R语言编码风格指南》。
Part 1:函数
Section 1:数学与统计函数
数学函数用于对数据作变换。
| 函数 | 描述 |
|---|---|
abx(x) |
绝对值 |
sqrt(x) |
平方根 |
ceiling(x) |
天花板,不小于x的最小整数 |
floor(x) |
地板,不大于x的最大整数 |
trunc(x) |
截尾,向\(0\)的方向截取x的整数部分 |
round(x, digits=n) |
四舍五入,保留\(n\)位小数 |
signif(x, digits=n) |
四舍五入,保留\(n\)位有效数字 |
cos(x), sin(x), tan(x) |
三角函数 |
acos(x), asin(x), atan(x) |
反三角函数 |
cosh(x), sinh(x), tanh(x) |
双曲三角函数 |
acosh(x), asinh(x), atanh(x) |
反双曲余弦函数 |
log(x, banse=n) |
对数\(\log_{n}(x)\) |
log(x), log10(x) |
自然对数\(\ln(x)\)和常用对数\(\lg(x)\) |
exp(x) |
指数函数 |
统计函数常用于对数据作变换或统计,以下函数,许多都有如na.rm之类的可选参数,可以使用?function来查询。
| 函数 | 描述 | 应用 |
|---|---|---|
mean(x) |
平均数 | mean(c(1, 2, 3, 4))返回2.5 |
median(x) |
中位数 | median(c(1, 2, 3, 4))返回2.5 |
sd(x) |
标准差 | sd(c(1, 2, 3, 4))返回1.29 |
var(x) |
方差 | var(c(1, 2, 3, 4))返回1.67 |
mad(x) |
绝对中位差 | mad(c(1, 2, 3, 4))返回1.48 |
quantile(x, probs) |
求分位数 | x是数值向量,probs是概率值向量 |
range(x) |
求值域 | range(c(1, 2, 3, 4))返回c(1, 4) |
sum(x) |
求和 | sum(c(1, 2, 3, 4))返回10 |
diff(x, lag=n) |
滞后差分 | diff(c(1, 5, 23, 29))返回c(4, 18, 6) |
min(x) |
求最小值 | min(c(1, 2, 3, 4))返回1 |
max(x) |
求最大值 | max(c(1, 2, 3, 4))返回4 |
scale(x, center=TRUE, scale=TRUE) |
按列标准化 | center进行中心化,scale进行标准化 |
这里方差的计算是无偏的,即
\]
Section 2:概率函数
在R语言中,概率函数是由d, p, q, r再加上分布的名字缩写所构成的函数,这四个字母分别具有如下的意义:
d:密度函数(density)。p:分布函数(distribution function)。q:分位数函数(quantile function),第一个参数为q,代表要求的(下侧)分位点\(\alpha\)。r:生成随机数,第一个参数为n,代表要生成的随机数个数。
分布的名字如下表所示,按字母顺序排序:
| 分布名 | R中缩写 |
|---|---|
| Beta分布 | beta |
| 二项分布 | binom |
| 柯西分布 | cauchy |
| 卡方分布 | chisq |
| 指数分布 | exp |
| F分布 | t |
| Gamma分布 | gamma |
| 几何分布 | geom |
| 超几何分布 | hyper |
| 对数正态分布 | lnorm |
| Logistic分布 | logis |
| 多项分布 | multinom |
| 负二项分布 | nbinom |
| 正态分布 | norm |
| 泊松分布 | pois |
| Wilcoxon符号秩分布 | signrank |
| t分布 | t |
| 均匀分布 | unif |
| Weibull分布 | weibull |
| Wilcoxon秩和分布 | wilcox |
每个分布都有其可选参数,可以通过?function查询。
设定种子可以让结果可复现,在R语言中,set.seed()函数可以显式指定这个种子。
生成多元正态随机数,可以使用mvrnorm(n, mean, sigma)函数,这里mean是均值向量,sigma是协方差矩阵或相关矩阵。
Section 3:其他实用函数
这里介绍一些其他实用的函数。
length(x)返回对象x的长度。如果x是向量,则返回向量长度;如果x是数据框,则返回变量个数(而不是观测个数),不过要返回数据框的相关信息,最好使用ncol来返回变量个数,nrow来返回观测个数。
seq(from, to, by)函数用于生成一个等差序列,包含from和to,这里by是间距;rep(x, n)将对象x重复n次用于生成一个重复序列;pretty(x, n)将一个连续型变量x通过美观的分割点,分割为近似n个区间。
cut(x, n)将连续型变量x分割成有n个水平的因子,使用选项ordered_result=TRUE可以创建有序型因子。
cat(...)连接...中的对象,并将其输出到屏幕上或文件中,常用于打印字符串,可以用sep指定分隔符,默认为空格。字符串中具有如下的转义字符:\n换行、\t制表符、\'单引号,\b退格等等。
apply(x, MARGIN, FUN, ...)函数允许将任意一个函数应用到矩阵、数组、数据框的任何维度上,这里x是数据对象,MARGIN是维度的下标,矩阵和数据框中MARGIN=1代表行,MARGIN=2代表列,FUN是要运用的函数名。如果要运用的函数还有其他参数,可以在...处指定。
t(x)可以对数据框或者矩阵x进行转置,当x为数据框时,行名将成为转置后的变量名。aggregate(x, by, FUN)是整合函数,类似于SQL中的GROUP BY,这里by是待折叠的变量名,必须在一个列表中(即使只有一个变量),FUN是用于处理整合的函数。
Part 2:其他控制
Section 1:循环与条件结构
循环结构for的语法是:
for (var in seq){
statement
}
循环结构while的语法是:
while (cond){
statement
}
在处理大数据集中的行和列时,R中的循环比较低效费时,最好联合使用R的内置函数和apply族函数。
条件结构if-else的语法是:
if (cond){
statement1
}
else{
statement2
}
else的部分可以没有。以上结构可以紧凑地写成ifelse版本,语法为:
ifelse(cond, statement1, statement2)
这类似于一个三目运算符,如果生成的结果都是向量,使用ifelse更合适。
条件结构switch可以根据一个表达式的值来选择语句执行,语法为:
switch(
expr,
value1 = statement1,
value2 = statement2,
...
)
需要注意的是,如果expr的值是一个字符串,则value1, value2等值的内容也是字符串,但是不需要加引号。
Section 2:自编函数
R中使用function函数来自编函数,为了尽可能返回丰富的信息,返回值经常是一个列表,用于存储一系列对象。语法如下:
myfunction <- function(arg1, arg2, ...){
statement
object <- list(value1=value1, value2=value2, ...) # 这句是不一定需要的
return(object) # 如果没有return()则最后一行代码的返回值作为return的内容
}
Section 3:使用reshape2重构数据集
reshape2包是一套重构和整合数据集的万能工具,需要使用前安装:
install.package("reshape2")
library(reshape2)
将使用如下的数据框进行处理。
ID <- c(1, 1, 2, 2)
Time <- c(1, 2, 1, 2)
X1 <- c(5, 3, 6, 2)
X2 <- c(6, 5, 1, 4)
mydata <- data.frame(ID, Time, X1, X2)
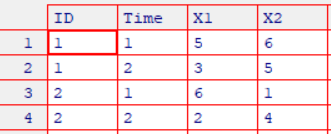
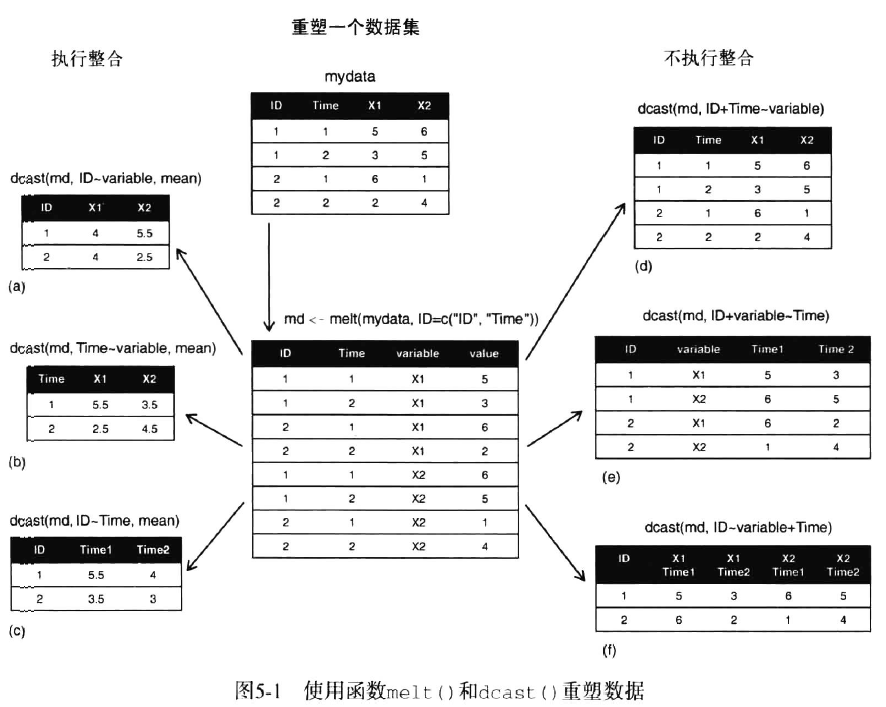
使用该包对数据集进行处理,需要先对数据集进行融合(melt),再进行重铸(cast)。融合使用函数melt(x, id),x是待融合的数据框,id则是数据框的主键,输出一个新的数据框:每个测量变量独占一行,行中包含确定这个测量变量所需的标识符。此时,融合数据框操作的代码为
md <- melt(mydata, id=c("ID", "Time"))
得到的结果是
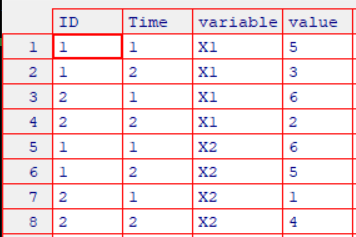
可以对融合后的数据框使用dcast()函数进行重铸,调用格式是dcast(md, formula, fun.aggregate),这里md是已融合的数据,formula接受一个公式,描述了最后的想要结果,公式的形式是
\]
这里,rowvar中的变量作为主键,colvar中的变量作为数据框的值,返回的数据框包含所有的rowvar和colvar作为变量。fun.aggregate参数是可选的整合函数。
R语言学习4:函数,流程控制,数据框重塑的更多相关文章
- R语言学习 第三篇:数据框
数据框(data.frame)是最常用的数据结构,用于存储二维表(即关系表)的数据,每一列存储的数据类型必须相同,不同数据列的数据类型可以相同,也可以不同,但是每列的行数(长度)必须相同.数据框的每列 ...
- R语言数据分析利器data.table包—数据框结构处理精讲
R语言数据分析利器data.table包-数据框结构处理精讲 R语言data.table包是自带包data.frame的升级版,用于数据框格式数据的处理,最大的特点快.包括两个方面,一方面是写的快,代 ...
- Go语言学习之3 流程控制、函数
主要内容: 1. strings和strconv使用2. Go中的时间和日期类型3. 指针类型4. 流程控制5. 函数详解 1. strings和strconv使用 //strings . strin ...
- R语言数据分析利器data.table包 —— 数据框结构处理精讲
R语言data.table包是自带包data.frame的升级版,用于数据框格式数据的处理,最大的特点快.包括两个方面,一方面是写的快,代码简洁,只要一行命令就可以完成诸多任务,另一方面是处理 ...
- R语言学习 第四篇:函数和流程控制
变量用于临时存储数据,而函数用于操作数据,实现代码的重复使用.在R中,函数只是另一种数据类型的变量,可以被分配,操作,甚至把函数作为参数传递给其他函数.分支控制和循环控制,和通用编程语言的风格很相似, ...
- R语言学习笔记之: 论如何正确把EXCEL文件喂给R处理
博客总目录:http://www.cnblogs.com/weibaar/p/4507801.html ---- 前言: 应用背景兼吐槽 继续延续之前每个月至少一次更新博客,归纳总结学习心得好习惯. ...
- 利用R语言制作出漂亮的交互数据可视化
利用R语言制作出漂亮的交互数据可视化 利用R语言也可以制作出漂亮的交互数据可视化,下面和大家分享一些常用的交互可视化的R包. rCharts包 说起R语言的交互包,第一个想到的应该就是rCharts包 ...
- R语言学习 第九篇:plyr包
在数据分析中,整理数据的本质可以归纳为:对数据进行分割(Split),然后应用(Apply)某些处理函数,最后将结果重新组合(Combine)成所需的格式返回,简单描述为:Split - Apply ...
- R语言学习笔记:向量
向量是R语言最基本的数据类型. 单个数值(标量)其实没有单独的数据类型,它只不过是只有一个元素的向量. x <- c(1, 2, 4, 9) x <- c(x[1:3], 88, x[4] ...
- R语言学习笔记(八):零碎知识点(16-20)
16--complete.cases( ) complete.case()可以判断对象中是否数据完全,然后返回TRUE, FALSE 这一函数在去除数据框中缺失值时很有用. > d kids a ...
随机推荐
- 在.NetCore(C#)中使用ODP.NET Core+Dapper操作Oracle数据库
前言 虽然一直在说"去IOE化",但是在国企和政府,Oracle的历史包袱实在太重了,甚至很多业务逻辑都是写在Oracle的各种存储过程里面实现的-- 我们的系统主要的技术栈是Dj ...
- Sqoop import export参数
通用参数 import export 通用通用参数选项 含义说明–connect 指定JDBC连接字符串–connection-manager 指定要使用的连接管理器类–dri ...
- SPOJ Favorite Dice(概率dp)
题意: 一个骰子,n个面,摇到每一个面的概率都一样.问你把每一个面都摇到至少一次需要摇多少次,求摇的期望次数 题解: dp[i]:已经摇到i个面,还需要摇多少次才能摇到n个面的摇骰子的期望次数 因为我 ...
- POJ_2112 二分图多重匹配
题意: //题意就是给你k个挤奶池和c头牛,每个挤奶池最多可以来m头牛,而且每头牛距离这k这挤奶池//有一定的距离,题目上给出k+c的矩阵,每一行代表某一个物品距离其他物品的位置//这里要注意给出的某 ...
- HDU - 2159 dp
题目: 最近xhd正在玩一款叫做FATE的游戏,为了得到极品装备,xhd在不停的杀怪做任务.久而久之xhd开始对杀怪产生的厌恶感,但又不得不通过杀怪来升完这最后一级.现在的问题是,xhd升掉最后一级还 ...
- 迷宫城堡 HDU - 1269 判断有向图是否是强连通图
为了训练小希的方向感,Gardon建立了一座大城堡,里面有N个房间(N<=10000)和M条通道(M<=100000),每个通道都是单向的,就是说若称某通道连通了A房间和B房间,只说明可以 ...
- AtCoder Beginner Contest 173 C - H and V (二进制枚举)
题意:有一张图,.表示白色,#表示黑色,每次可以将多行和多列涂成红色(也可不涂),问有多少种方案,使得剩下黑点的个数为\(k\). 题解:又学到了新的算法qwq,因为这题的数据范围很小,所以可以用二进 ...
- 分块 && 例题 I Hate It HDU - 1754
分块算法: 分块就是对暴力方法的一种优化: _ 假设我们总共的序列长度为n,然后我们把它切成√n 块,然后把每一块里的东西当成一个整体来看,完整块:被 ...
- 六、Python集合定义和基本操作方法
一.集合的定义方法及特点 1.特点: (1)由不同元素组成 #集合由不同元素构成 s={1,2,3,3,4,3,3,} print(s)#运行结果:{1, 2, 3, 4} (2)集合无序 #集合无序 ...
- PowerShell随笔3 ---别名
上一篇提到了别名,这个有必要说一下,因为我们常常会遇到以下两种情况: 自己写脚本,想快速一些,使用命名 看别人的脚本,发现别人和你想的一样,用了别名,但是你忘记了这个别名是什么意思. 我们可以通过Ge ...