(PatchGANs)Pecomputed Real-time Texture Synthesis With Markovian Generative Adversarial Networks
Introduction:
Deconvolution; Computational costs; Strided convolutional nets; Markov patches;
1. Q: The task of texture synthesis have considerable computational costs becuase of a numerical deconvolution in previous work.
2. A: the author propose to procompute a feed-forwaed, strided convolutional network :
This framework can -
1. capture statistics of Markov patches.
2. directly generate output of arbitrary dimensions.
3. this method have considerable advantage in the fact of time-computation.
4. traditional complexity constraints(复杂性约束) using Markov random field that characterizes(表征) images by statistics of local patches of pixels(局部像素快的统计信息).
5. Deep architectures capture appearance variations in object classes beyond the abilities of pixel-level ap-
proaches.(深层架构能够捕获外表形状的变化的能力超过了基于像素水平的方法)
6.two main class of deep generative models:
1. full images models, often including specially trained 'auto-encoder', which limited fidelity(精确度) in details.
2. deep Markov models, capture the statistics of local patches, and assemble them to high-resolution.
Advantage:Markov model have good fidelity of details.
Disadvantage:
如果不重要的的全局结构要被产生, 则需要额外的辅助指导;
high time computation
这自然地提供了the blending of patches,并允许重用复杂的、紧急的多层特征表示的 大 型、有区别地训练的神经网络,如VGG网络[30],重新利用它们进行图像合成wih deconvolution framwork.
Objective: to improve the effciency of deep Markovian texture synthesis.
The key idea:
To precompute the inversion of strided the network by fitting a convolutional network [31,29] to the inversion process, which operates purely in a feed-forward fashion.(关键思想是通过将跨步卷积网络拟合到反演过程来预先计算网络的反演,该反演过程纯粹以前馈方式运行)
尽管在固定大小的patch上进行训练,得到的网络可以生成任意尺寸的连续图像,而不需要任何额外的优化或混合,从而产生一个具有特殊风格和高性能的高质量纹理合成器.
The model:
the framework of DCGANs is applied, nonetheless(然而).相同(be equivalent to )
Related work
1.Xie et al. [34] have proved that a generative random field model can be derived from used discriminative networks, and show applications to unguided texture synthesis.(Xie等人的[34]已经证明了从所使用的判别网络中可以导出一个生成的随机场模型,并展示了它在非制导纹理合成中的应用。)
2.full image method with auto-encoders as generative nets.
DCGANs stabilzed the performance of GANs and shows the generator have vector arithmeric properties(向量运算性质).生成器具备了“向量运算”的神奇性质,类似于word embedding可以操纵向量,并且能够按照“语义”生成新内容。
Adversarial nets offer perceptual metrics(感知指标) that allow AEs to be trianing effciency.
3. this PatchGANs is the use of feature-patch statistics rather than learn Gaussian distributions of individual feature vectors.(本文的主要概念差异是使用了Li等人的[21]特征-patch统计量,而不是学习单个特征向量的高斯分布,这在更忠实地再现纹理方面提供了一些好处。)
Model

Motivation:
1.As figure shown,real data does not always comly with(遵守) a Gaussian distribution(a), but a complex nonlinear monifold(复杂的非线性流体)(b), We adversarially learn a mapping to project contextually related patches to that manifold.
2. Statistics based mehods match the disribution of input and target with a Gaussian model.
3. Adversarial training (GANs) can recognize such manifold with its discriminative network. and strengthen its generative power with a projection on the manifold.
4. to improve adversarial training with contextually corresponding Markovian patches(上下文对应的马尔可夫patches),to focus on depictions(描述) of same context.
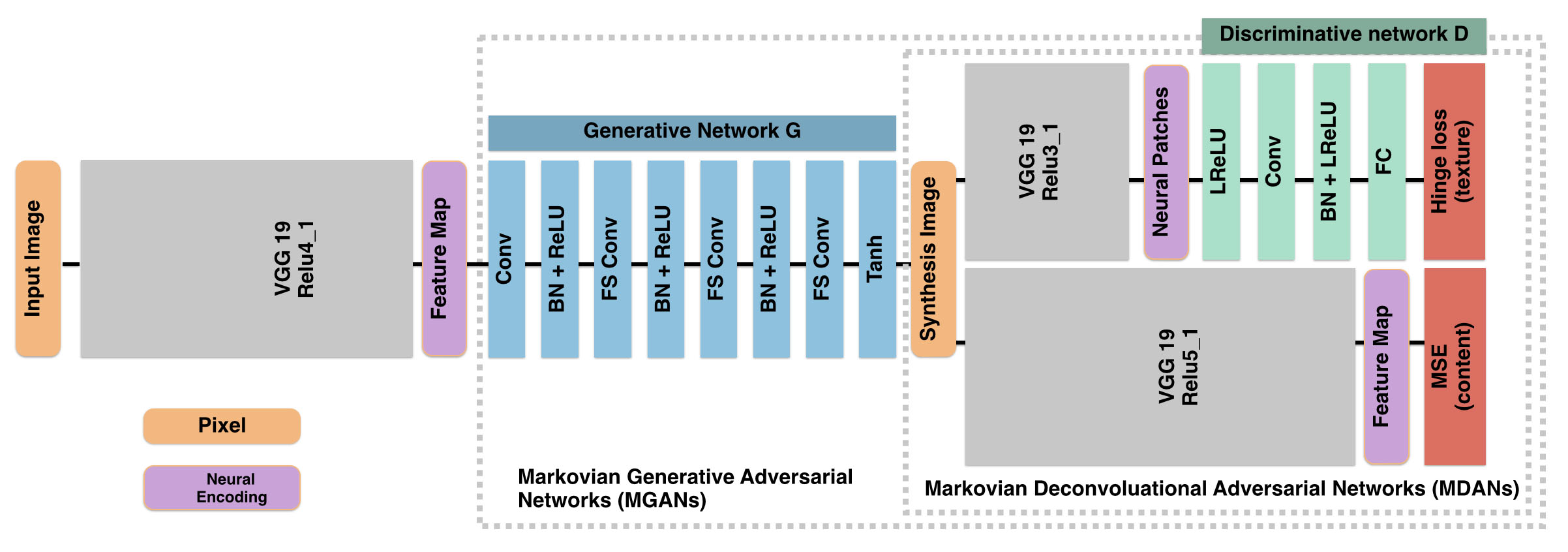
Model Depictions:
for D:
D (green blocks) that learns to distinguish actual feature patches (on VGG 19 layer Relu3 1, purple block) from inappropriately synthesized ones(不当的合成的patches).
第二次比较(管道下面的D)与VGG 19编码相同的图像在较高的,更抽象的层Relu5 1可以选择用于指导the distinguish of content.
for G:
encoding with VGG19_Relu4_1 and decodes it to pixels of the synthesis image
for MDANs: with a deconvolutional process is driven by adversarial traning
1. D (green blocks) is trained to distinguish between "neural patches" sampled from the synthesis image and sampled from the example image.
2. the score (1-s) is its texture loss.
with loss function:
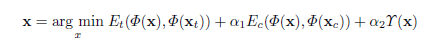
$E_{t}$ denotes the loss between example texture image and synthsized image.
We initialize $x$ with random noise for un-guided synthesis, or an content image $x_{c}$ for guided synthesis.
with Hinge loss :
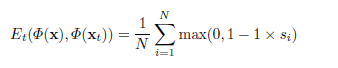
Here $s_{i}$ denotes the classication score of i-th neural patch, and $N$ is the total
number of sampled patches.
for MGANs
1. G decodes a picture through a ordinary convolution followed by a cascade(级联) of fractional-strided convolutions(分数阶跃卷积) (FS Conv).
Although being trained with fixed size input, the generator naturally extends to arbitrary size images.
2. 欧式距离的损失函数会使 产生(yield)的图像过于平滑(over-smooth)
3.compared with GANs, PatchGans do not operate on full images, but neural patches. in order to make learning easier with contextual correspondence between the patches
4. replace sigmoid by hinge loss.
Experiment detail
1. augment dataset with rotations and scales
2. samle subwindow of 128-by-128, where neural patches are sampled from its relu3_1 encoding as the input of D.
for Training
The training process has three main steps:
- Use MDAN to generate training images (MDAN_wrapper.lua).
- Data Augmentation (AG_wrapper.lua).
- Train MGAN (MDAN_wrapper.lua).
(PatchGANs)Pecomputed Real-time Texture Synthesis With Markovian Generative Adversarial Networks的更多相关文章
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 论文笔记
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks 本文将利 ...
- 语音合成论文翻译:2019_MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
论文地址:MelGAN:条件波形合成的生成对抗网络 代码地址:https://github.com/descriptinc/melgan-neurips 音频实例:https://melgan-neu ...
- 【Paper Reading】Improved Textured Networks: Maximizing quality and diversity in Feed-Forward Stylization and Texture Synthesis
Improved Textured Networks: Maximizing quality and diversity in Feed-Forward Stylization and Texture ...
- 卷积神经网络图像纹理合成 Texture Synthesis Using Convolutional Neural Networks
代码实现 概述 这是关于Texture Synthesis Using Convolutional Neural Networks论文的tensorflow2.0代码实现,使用keras预训练的VGG ...
- 论文笔记之:Generative Adversarial Text to Image Synthesis
Generative Adversarial Text to Image Synthesis ICML 2016 摘要:本文将文本和图像练习起来,根据文本生成图像,结合 CNN 和 GAN 来有效的 ...
- 《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》论文笔记
Code Address:https://github.com/junyanz/CycleGAN. Abstract 引出Image Translating的概念(greyscale to color ...
- Generative Adversarial Nets[CycleGAN]
本文来自<Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks>,时间线为2017 ...
- Generative Adversarial Nets[pix2pix]
本文来自<Image-to-Image Translation with Conditional Adversarial Networks>,是Phillip Isola与朱俊彦等人的作品 ...
- Awesome Torch
Awesome Torch This blog from: A curated list of awesome Torch tutorials, projects and communities. T ...
随机推荐
- spring aop原理和实现
一.aop是什么 1.AOP面向方面编程基于IoC,是对OOP的有益补充: 2.AOP利用一种称为"横切"的技术,剖解开封装的对象内部,并将那些影响了 多个类的公共行为封装到一个可 ...
- Java源码赏析(一)Object 类
写这个系列的原因,其实网上已经有无数源码分析的文章了,多一篇不多,少一篇不少,但为什么还要写这部分文章呢?于私,其一,上班族已经很久没有打过完整的一整段有意义的话,算是锻炼个人的书写.总结能力,其二, ...
- 从SpringBoot源码看资源映射原理
前言 很多的小伙伴刚刚接触SpringBoot的时候,可能会遇到加载不到静态资源的情况. 比如html没有样式,图片无法加载等等. 今天王子就与大家一起看看SpringBoot中关于资源映射部分的主要 ...
- tf.app.flags与argparse功能类似
https://blog.csdn.net/ei1990/article/details/76423277 tensorflow中tf.app.flags与argparse模块有点类似,通过它们都可以 ...
- hystrix ,feign,ribbon的超时时间配置,以及原理分析
背景,网上看到很多关于hystrix的配置都是没生效的,如: 一.先看测试环境搭建: order 服务通过feign 的方式调用了product 服务的getProductInfo 接口 //---- ...
- Go-常量-const
常量:只能读,不能修改,编译前就是确定的值 关键字: const 常量相关类型:int8,16,32,64 float32,64 bool string 可计算结果数学表达式 常量方法 iota pa ...
- Leetcode-dfs & bfs
102. 二叉树的层次遍历 https://leetcode-cn.com/problems/binary-tree-level-order-traversal/ 给定一个二叉树,返回其按层次遍历的节 ...
- HTML中css水平居中的几种方式
1. 子元素为行内元素时,父元素使用 text-align: center; 实现子元素的水平居中: 2. 子元素为块级元素时, 2.1. 将子元素设置 margin: 0 auto; 实现居中: 2 ...
- 发现3 .js与Android和英特尔XDK
下载example3.zip - 456.5 KB 下载apk14.zip - 6.8 MB 下载apk13.zip - 6.8 MB Introduction 本文是关于使用Intel XDK和t ...
- [KMP]字符串匹配算法
算法介绍: KMP是一种用来处理字符串匹配问题的算法,给你两个字符串A.B,让你回答B是否为A的子串,或者A中有多少子串等于B. 这题最暴力的做法是:枚举A中与B相等的子串的左端点,再判断是否与B相等 ...