Flume是什么

分布式流式实时收集日志文件系统,便于实时在线的流式计算,常配合 Storm 和 spark streming 使用。
Flume is a distributed分布式的, reliable可靠的, and available可用的 service for efficiently高效 collecting收集, aggregating聚合, and moving移动 large amounts of log data.
It has a simple简单 and flexible灵活 architecture结构 based on streaming流式 data flows. It is robust健壮 and fault tolerant容错 with tunable可调 reliability mechanisms机制 and many failover and recovery mechanisms. It uses a simple extensible可拓展 data model that allows for online analytic application.
架构图如下
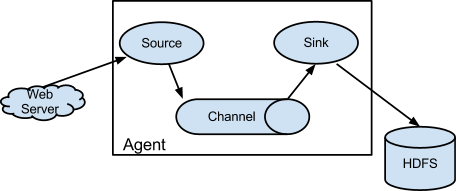

| 角色 | 作用 |
|---|---|
| Agent | Flume的客户端 |
| Event | Flume 数据传输的基本单元,由 [Header] 和 数据的 byte Array 构成,载有数据对Flume不透明;Header 是容纳了KEY_VALUE对的无序集合(Key是唯一的);Header 可以在上下文路由中使用拓展 |
| Source | 用于收集数据,产生数据源的地方,并主动推送数据到 Channel 中 |
| Channel | 数据管道,用于连接 sources 和 sinks ,可以连接多个Source(所谓的分布式),在管道前后增加过滤器可以清洗数据 |
| Sink | 主动到 Channel 拉取数据,向目标源写数据,目标源可以使HDFS、HBase 也可以是下一个Source |
Flume 配置
编辑配置文件的 $JAVA_PATH 就可以使用了
Flume是什么的更多相关文章
- Flume1 初识Flume和虚拟机搭建Flume环境
前言: 工作中需要同步日志到hdfs,以前是找运维用rsync做同步,现在一般是用flume同步数据到hdfs.以前为了工作简单看个flume的一些东西,今天下午有时间自己利用虚拟机搭建了 ...
- Flume(4)实用环境搭建:source(spooldir)+channel(file)+sink(hdfs)方式
一.概述: 在实际的生产环境中,一般都会遇到将web服务器比如tomcat.Apache等中产生的日志倒入到HDFS中供分析使用的需求.这里的配置方式就是实现上述需求. 二.配置文件: #agent1 ...
- Flume(3)source组件之NetcatSource使用介绍
一.概述: 本节首先提供一个基于netcat的source+channel(memory)+sink(logger)的数据传输过程.然后剖析一下NetcatSource中的代码执行逻辑. 二.flum ...
- Flume(2)组件概述与列表
上一节搭建了flume的简单运行环境,并提供了一个基于netcat的演示.这一节继续对flume的整个流程进行进一步的说明. 一.flume的基本架构图: 下面这个图基本说明了flume的作用,以及f ...
- Flume(1)使用入门
一.概述: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统. 当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- flume使用示例
flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受 ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- Flume NG Getting Started(Flume NG 新手入门指南)
Flume NG Getting Started(Flume NG 新手入门指南)翻译 新手入门 Flume NG是什么? 有什么改变? 获得Flume NG 从源码构建 配置 flume-ng全局选 ...
随机推荐
- sass入门(一)
一].sass入门安装sass安装koala // sass中可以自定义变量 $fontStack: Microsoft Yahei; $primaryColor: #333; body { font ...
- 在C++Builder中定义事件的实现方法
++Builder是由Borland公司推出的一款可视化集成开发工具.C++Builder的集成开发环境(IDE)提供了一系列可视化快速应用程序开发(RAD)工具,让程序员可以很轻松地建立和管理自己的 ...
- Html + JS : 点击对应的按钮,进行选择是隐藏还是显示(用户回复功能)
例如: 当我点击按钮1时,点击第一下进行显示This is comment 01,点击第二下隐藏This is comment 01 当我点击按钮2时,点击第一下进行显示This is comment ...
- IOS NSThread(线程同步)
@interface HMViewController () /** 剩余票数 */ @property (nonatomic, assign) int leftTicketsCount; @prop ...
- Python 语法基础
之所以学习Python,第一个是他比较简单,寒假时间充裕,而且听说功能也很不错,最重要的是,我今年的项目就要用到它. 而且刘汝佳的书上说到,一个好的Acmer要是不会一点Python那就是太可惜了.废 ...
- CentOS 5.6怎么安装MongoDB数据库?
1. 下载Linux版本的 MongoDB 数据库 到官方的下载页面下载mongodb的Linux版本,32位还是64位根据自己的情况自行选择 http://www.mongodb.org/downl ...
- Xamarin.Forms随手记
1. 更新Android SDK要从VS的工具栏上SDK Manager那里更新,不要像我一样之前搞了好几份SDK放在不同的地方,结果把自己搞糊涂了,更新了半天(真的是花了半天时间)才发现更新的地方不 ...
- JS面向对象、prototype、call()、apply()
一. 起因 那天用到prototype.js于是打开看看,才看几行就满头雾水,原因是对js的面向对象不是很熟悉,于是百度+google了一把,最后终于算小有收获,写此纪念一下^_^. prototyp ...
- python非字符串与字符产链连接
第一种办法: "hello" +' '+str(110) 输出结果: 'hello 110' 第二种办法: import numpy x = 110 print 'hello(%d ...
- System.Web.UI
类: System.Web.UI.Page 所以窗体继承的类