使用cookie登陆知乎
只是想说明一个问题,Cookie可以维持登录状态,有些网页当中,访问之后的cookie里面带有登陆账号,和登陆密码,这样可以使用cookie直接访问网页,如知乎,首先登录知乎,将Headers中的Cookie内容复制下来
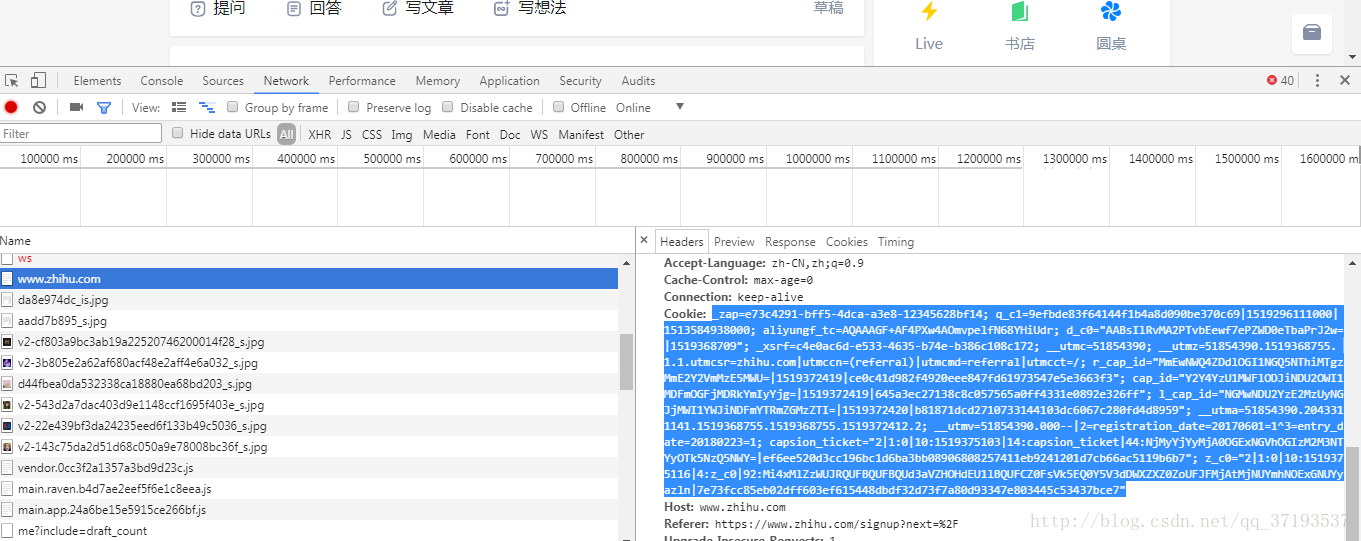
这个需要替换成你自己的Cookie,将其设置到Headers里面,然后发送请求,示例如下:
import requests
headers = {
'Cookie': '_zap=e73c4291-bff5-4dca-a3e8-12345628bf14; q_c1=9efbde83f64144f1b4a8d090be370c69|1519296111000|1513584938000; aliyungf_tc=AQAAAGF+AF4PXw4AOmvpelfN68YHiUdr; d_c0="AABsIlRvMA2PTvbEewf7ePZWD0eTbaPrJ2w=|1519368709"; _xsrf=c4e0ac6d-e533-4635-b74e-b386c108c172; __utmc=51854390; __utmz=51854390.1519368755.1.1.utmcsr=zhihu.com|utmccn=(referral)|utmcmd=referral|utmcct=/; r_cap_id="MmEwNWQ4ZDdlOGI1NGQ5NThiMTgzMmE2Y2VmMzE5MWU=|1519372419|ce0c41d982f4920eee847fd61973547e5e3663f3"; cap_id="Y2Y4YzU1MWFlODJiNDU2OWI1MDFmOGFjMDRkYmIyYjg=|1519372419|645a3ec27138c8c057565a0ff4331e0892e326ff"; l_cap_id="NGMwNDU2YzE2MzUyNGJjMWI1YWJiNDFmYTRmZGMzZTI=|1519372420|b81871dcd2710733144103dc6067c280fd4d8959"; __utma=51854390.2043311141.1519368755.1519368755.1519372412.2; __utmv=51854390.000--|2=registration_date=20170601=1^3=entry_date=20180223=1; capsion_ticket="2|1:0|10:1519375103|14:capsion_ticket|44:NjMyYjYyMjA0OGExNGVhOGIzM2M3NTYyOTk5NzQ5NWY=|ef6ee520d3cc196bc1d6ba3bb08906808257411eb9241201d7cb66ac5119b6b7"; z_c0="2|1:0|10:1519375116|4:z_c0|92:Mi4xMlZzWUJRQUFBQUFBQUd3aVZHOHdEU1lBQUFCZ0FsVk5EQ0Y5V3dDWXZXZ0ZoUFJFMjAtMjNUYmhNOExGNUYyazln|7e73fcc85eb02dff603ef615448dbdf32d73f7a80d93347e803445c53437bce7"',
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
}
r = requests.get('https://www.zhihu.com', headers=headers)
print(r.text)使用cookie登陆知乎的更多相关文章
- Python3 使用selenium库登陆知乎并保存cookie为本地文件
Python3 使用selenium库登陆知乎并保存cookie为本地文件 学习使用selenium库模拟登陆知乎,并将cookie保存为本地文件,然后供以后(requests模块)使用,用selen ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- 第十二篇 requests模拟登陆知乎
了解http常见状态码 可以通过输入错误的密码来找到登陆知乎的post:url 把Headers拉到底部,可以看到form data _xsrf是需要发送的,需要发送给服务端,否则会返回403错误,提 ...
- python selenium-webdriver 通过cookie登陆(十一)
上节介绍了浏览器的常用方法,涉及到了cookie的使用,本节介绍一下如何利用cookie进行登陆系统,这里使用到了request模块,我们首先利用request模块,请求登陆地址进行登陆,登陆成功以后 ...
- RFS实例登录126邮箱/利用cookie登陆百度
可以直接添加用户关键字,也可以新建资源,将用户关键字添加入资源,然后导入整个资源文件 用户关键字内部实现如下: 打开126邮箱首页: Open Browser Http://mail.126.com ...
- 使用OKHttp模拟登陆知乎,兼谈OKHttp中Cookie的使用!
本文主要是想和大家探讨技术,让大家学会Cookie的使用,切勿做违法之事! 很多Android初学者在刚开始学习的时候,或多或少都想自己搞个应用出来,把自己学的十八般武艺全都用在这个APP上,其实这个 ...
- Scrapy 模拟登陆知乎--抓取热点话题
工具准备 在开始之前,请确保 scrpay 正确安装,手头有一款简洁而强大的浏览器, 若是你有使用 postman 那就更好了. Python 1 scrapy genspid ...
- HttpClient 模拟登陆知乎
最近做爬虫相关工作,我们平时用HttpWebRequest 比较多,每一个Url都要创建一个HttpWebRequest实例, 而且有些网站验证比较复杂,在登陆及后续抓取数据的时候,每次请求需要把上次 ...
- (八)爬虫之js调试(登陆知乎)
上次爬取网易云音乐,折腾js调试了好久,难受....今天继续练练手,研究下知乎登陆,让痛苦更猛烈些. 1.简单分析 很容易就发现登陆的url=“https://www.zhihu.com/api/v3 ...
随机推荐
- 斗鱼扩展--notifications提示(十二)
来说下 桌面通知 Notification,HTML5支持 Web Notifications 的实例,但是要经过用户允许, chrome://settings/content/notificati ...
- 硬盘的基础知识-SSD
硬盘有三类:HDD(机械硬盘),SSD(固态硬盘),HHD(混合硬盘) 原理: HDD:磁性碟片 SSD: 闪存颗粒 HHD:磁性碟片的基础上加上了闪存颗粒. 这里对HDD,HHD不加说明,只对SSD ...
- 如何在Chrome粘贴图片直接上传
背景 截图或页面复制图片,可以直接通过Ctrl+v 粘贴上传图片 原理 操作:复制(截图)=>粘贴=>上传 监听粘贴事件=>获取剪贴板里的内容=>发请求上传 浏览器:Chrom ...
- 1.字符串池化(intern)机制及拓展学习
1.字符串intern机制 用了这么久的python,时刻和字符串打交道,直到遇到下面的情况: a = "hello" b = "hello" print(a ...
- Cordova各个插件使用介绍系列(七)—$cordovaStatusbar手机状态栏显示
在项目中发现Android和iOS在手机状态栏样式不一样,然后就查到有一个cordova插件可以解决这个问题 1.下载插件$cordovaStatusbar命令: cordova plugin add ...
- MYSQL:随机抽取一条数据库记录
今天我们要实现从随机抽取一条数据库记录的功能,并且抽取出来的数据记录不能重复: 1.首先我们看文章表中的数据: 2.实现功能代码如下: 1 /** * 获取随机的N篇文篇 * @param int $ ...
- webpack整体了解
一.下载 新建一个文件夹,在cmd中npm init->npm install->npm install webpack --save-dev 下载完成之后,新建一个webpack.con ...
- 计算时间 相加,相减 的方法,TimeSpan 数据转换
#region Time calculation method public static string DelayTypeTime_1(DateTime ArrivalTime_1, DateTim ...
- POJ - 3109 Inner Vertices
不存在-1的情况,而且最多一轮就结束了.如果新增加的黑点v0会产生新的黑点v1,那么v0和v1肯定是在一条轴上的,而原来这条轴上已经有黑点了. 离散以后扫描线统计,往线段上插点,然后查询区间上点数. ...
- mm_struct简要解析
http://blog.chinaunix.net/uid-20729583-id-1884615.html struct mm_struct { /* 指向线性区对象的链表头 ...