给ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager(图文详解)
不多说,直接上干货!
参考博客
基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8、0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口)
但是,要注意的是,因为在amabri集群里啊,10000端口默认是给了oozie的。
然而,我上述的博客,是当时手动临时给的10000端口给kafka-manager,所以,对此,我这里改变端口,具体如下。
一、给基于Ubuntu14.04的ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager
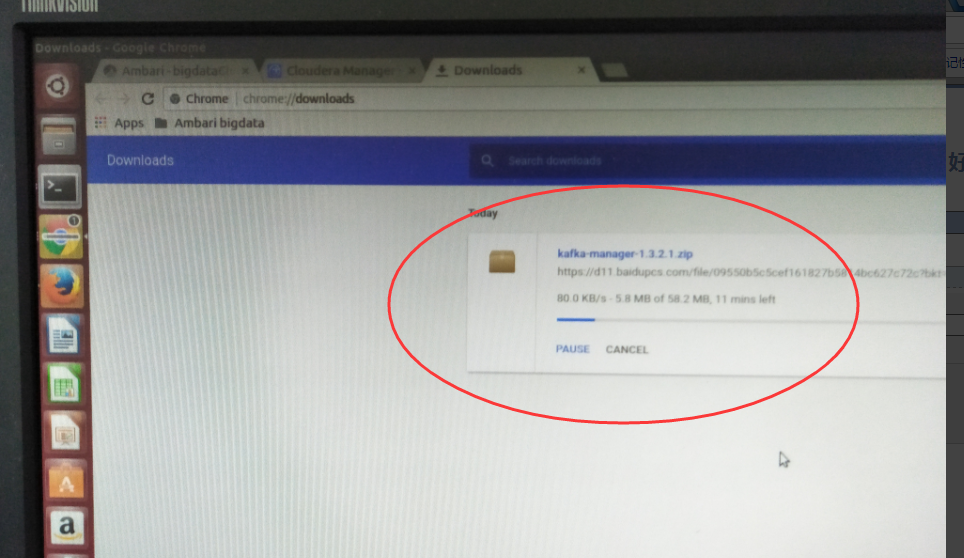
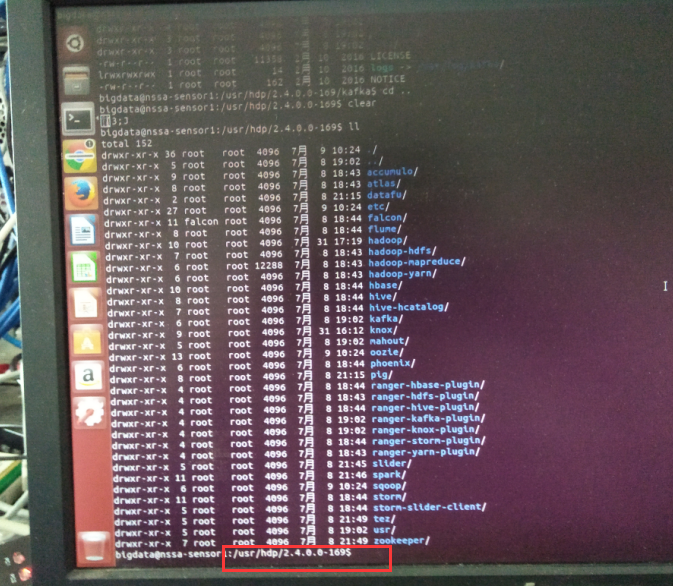
我这里,打算为了目录管理方便起见,安装Kafka-manager在/usr/hdp/2/4.0.0-169目录下。
具体过程见基于centos6.5,我这里就不贴图了,过程是完全一样的。
二、给基于CentOS6.5的ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager
下载
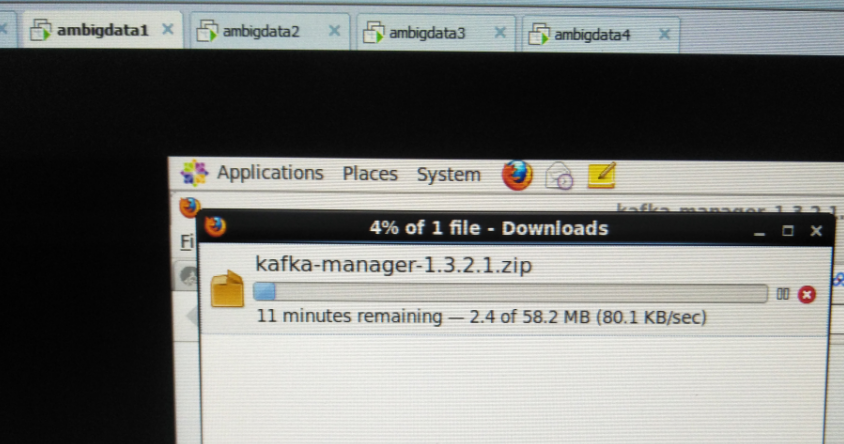

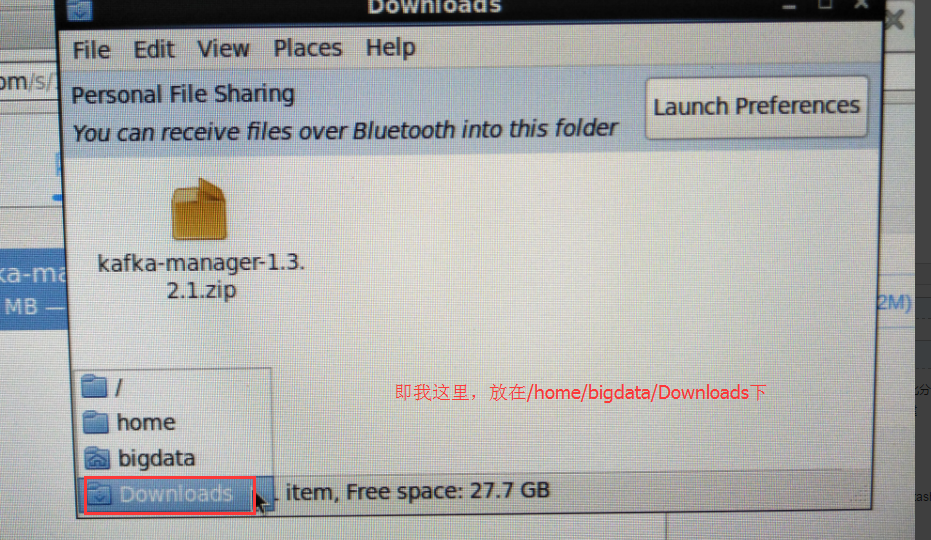

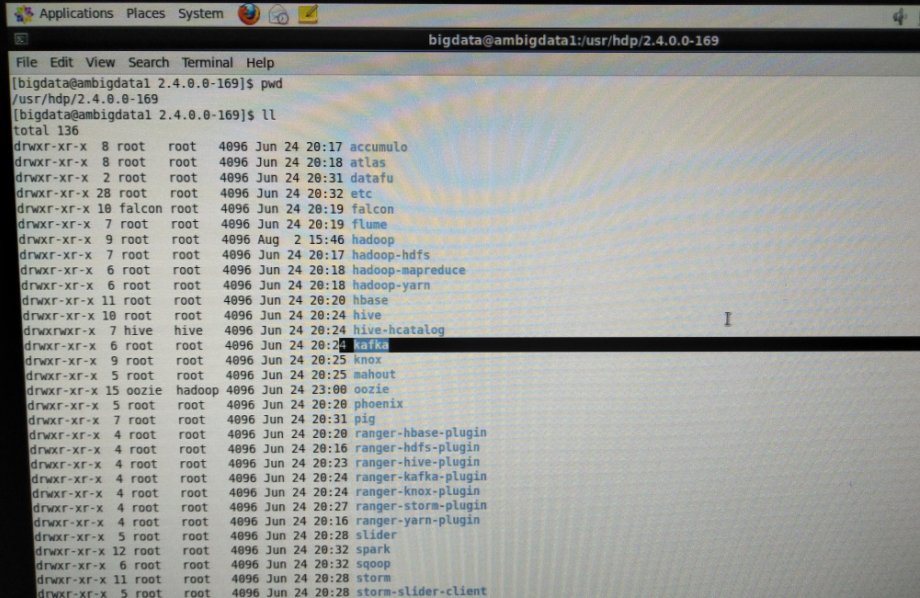
我这里,打算为了目录管理方便起见,安装Kafka-manager在/usr/hdp/2/4.0.0-169目录下。

[hadoop@ambigdata1 2.4.0.0.-]$ unzip kafka-manager-1.3.2.1.zip

[hadoop@ambigdata1 2.4.0.0-169]$ rm kafka-manager-1.3.2.1.zip
[hadoop@ambigdata1 2.4.0.0-169]$ cd kafka-manager-1.3.2.1/
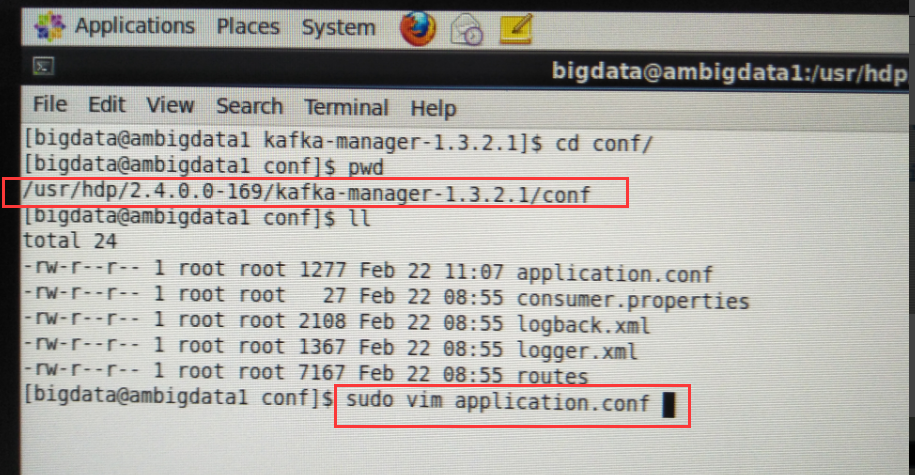
[hadoop@ambigdata1 conf]$ pwd
/usr/hdp/2.4.0.0-169/kafka-manager-1.3.2.1/conf
[hadoop@ambigdata1 conf]$ ll
total
-rw-r--r-- hadoop hadoop Feb : application.conf
-rw-r--r-- hadoop hadoop Feb : consumer.properties
-rw-r--r-- hadoop hadoop Feb : logback.xml
-rw-r--r-- hadoop hadoop Feb : logger.xml
-rw-r--r-- hadoop hadoop Feb : routes
[hadoop@ambigdata1 conf]$ vim application.conf
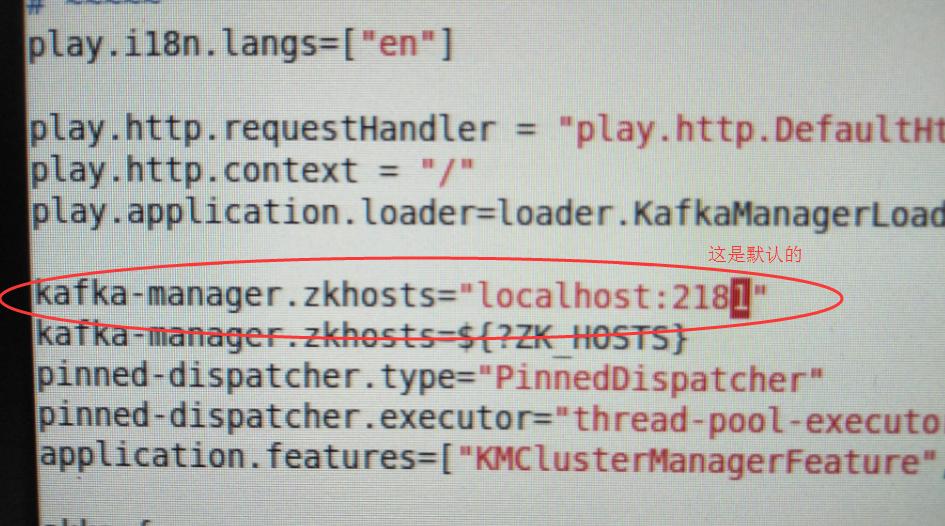
这是默认的
# Copyright Yahoo Inc. Licensed under the Apache License, Version 2.0
# See accompanying LICENSE file. # This is the main configuration file for the application.
# ~~~~~ # Secret key
# ~~~~~
# The secret key is used to secure cryptographics functions.
# If you deploy your application to several instances be sure to use the same key!
play.crypto.secret="^<csmm5Fx4d=r2HEX8pelM3iBkFVv?k[mc;IZE<_Qoq8EkX_/7@Zt6dP05Pzea3U"
play.crypto.secret=${?APPLICATION_SECRET} # The application languages
# ~~~~~
play.i18n.langs=["en"] play.http.requestHandler = "play.http.DefaultHttpRequestHandler"
play.http.context = "/"
play.application.loader=loader.KafkaManagerLoader kafka-manager.zkhosts="localhost:2181"
kafka-manager.zkhosts=${?ZK_HOSTS}
pinned-dispatcher.type="PinnedDispatcher"
pinned-dispatcher.executor="thread-pool-executor"
application.features=["KMClusterManagerFeature","KMTopicManagerFeature","KMPreferredReplicaElectionFeature","KMReassignPartitionsFeature"] akka {
loggers = ["akka.event.slf4j.Slf4jLogger"]
loglevel = "INFO"
} basicAuthentication.enabled=false
basicAuthentication.username="admin"
basicAuthentication.password="password"
basicAuthentication.realm="Kafka-Manager" kafka-manager.consumer.properties.file=${?CONSUMER_PROPERTIES_FILE}

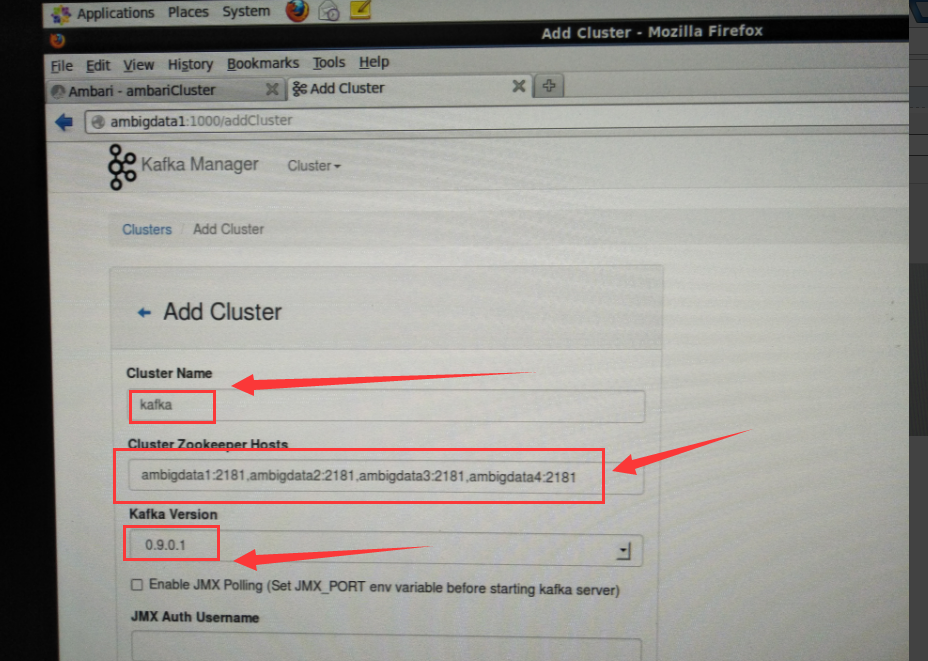
kafka-manager.zkhosts="ambigdata1:2181,ambigdata2:2181,ambigdata3:2181,ambigdata4:2181"

运行kafka manager
注意:默认启动端口为9000。
要到大家kafka-manager的安装目录下来执行。
如我这里是在/usr/hdp/2.4.0.0-169/kafka-manager-1.3.2.1
bin/kafka-manager -Dconfig.file=conf/application.conf
或者
nohup bin/kafka-manager -Dconfig.file=conf/application.conf & (后台运行)
当然,大家可以以这个端口为所用,大家也可以在启动的时候,开启另一个端口,比如我这里开启1000端口。
最好使用绝对路径。
要到大家kafka-manager的安装目录下来执行。
如我这里是在/usr/hdp/2.4.0.0-169/kafka-manager-1.3.2.1
nohup bin/kafka-manager -Dconfig.file=/usr/hdp/2.4.0.0-169/kafka-manager-1.3.2.1/conf/application.conf -Dhttp.port=1000 &
我这里, 为了避免跟ambari集群里默认的oozie端口为10000。所以特地开启1000端口。
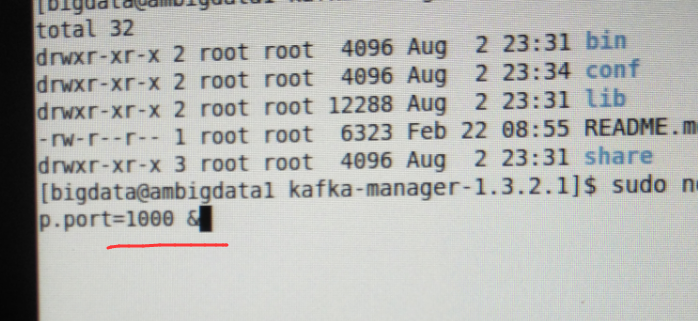

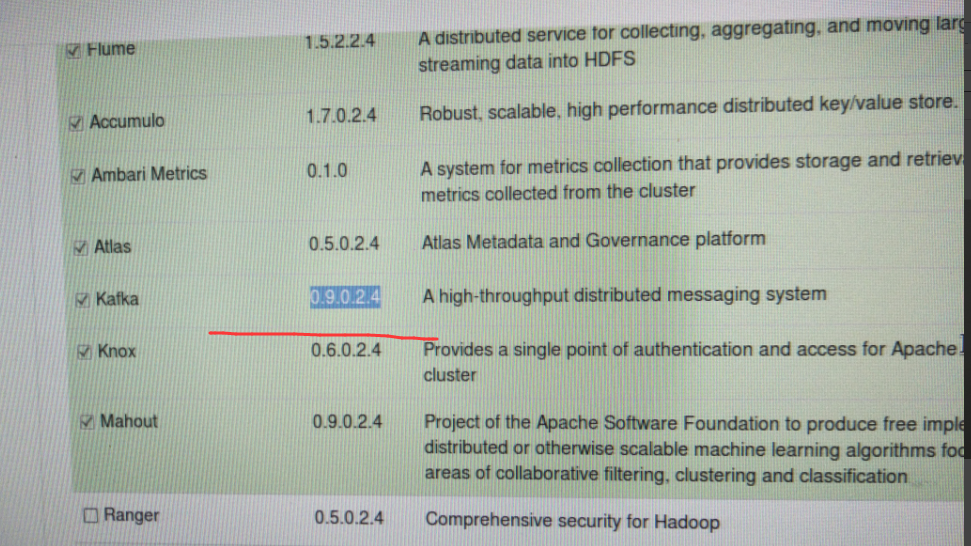
它会自动识别出,当前,你所用的kafka版本




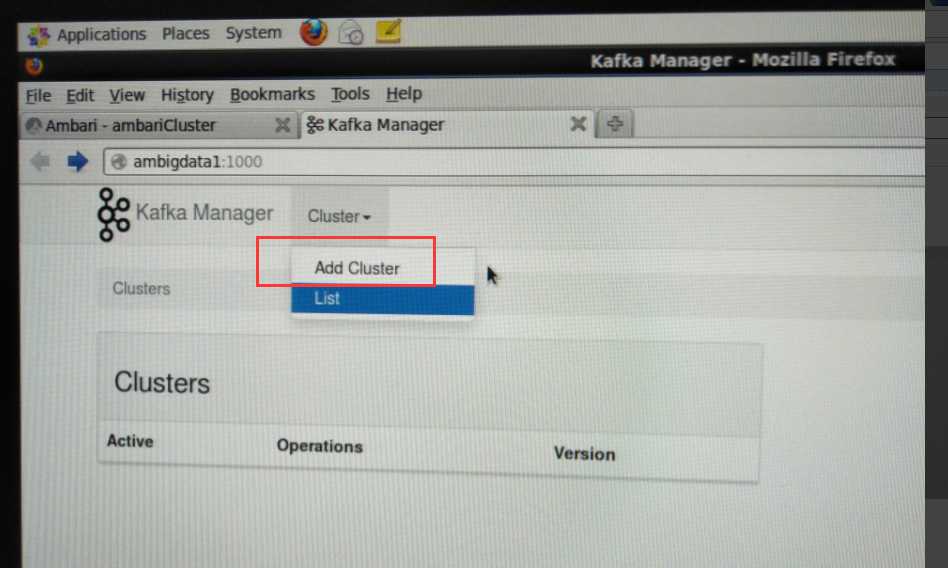
点击【Go to cluster view.】打开当前的集群界面。

成功!
更详细见,
基于Web的Kafka管理器工具之Kafka-manager安装之后第一次进入web UI的初步配置(图文详解)
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



给ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager(图文详解)的更多相关文章
- 安装Cloudera Manager集群时首次运行命令部署客户端设置失败的解决办法(图文详解)
不多说,直接上干货! 问题详情 解决办法 (1) 时间同步检查下(尤其是这个) (2) 防火墙是否关闭 (3) cloudera-scm-server 和 cloudera-scm-agent 是否启 ...
- 给Ambari集群里安装可视化分析利器工具Hue步骤(图文详解)
扩展博客 以下,是我在手动的CDH版本平台下,安装Hue. CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz) ...
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- Ambari集群里操作时典型权限问题put: `/home/bigdata/1.txt': No such file or directory的解决方案(图文详解)
不多说,直接上干货! 问题详情 明明put该有的文件在,可是怎么提示的是文件找不到的错误呢? 我就纳闷了put: `/home/bigdata/1.txt': No such file or dire ...
- Scala IDEA for Eclipse里用maven来创建scala和java项目代码环境(图文详解)
这篇博客 是在Scala IDEA for Eclipse里手动创建scala代码编写环境. Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群模式) ...
- 全网最详细的Windows系统里Oracle 11g R2 Database(64bit)的完全卸载(图文详解)
不多说,直接上干货! 前期博客 全网最详细的Windows系统里Oracle 11g R2 Database(64bit)的下载与安装(图文详解) 若你不想用了,则可安全卸载. 完全卸载Oracle ...
- 【适合公司业务】全网最详细的IDEA里如何正确新建【普通或者Maven】的Java web项目并发布到Tomcat上运行成功【博主强烈推荐】(类似eclipse里同一个workspace下【多个子项目】并存)(图文详解)
不多说,直接上干货! 首先,大家要明确,IDEA.Eclipse和MyEclipse等编辑器之间的新建和运行手法是不一样的. 如果是在Myeclipse里,则是File -> new -> ...
- ambari集群里如何正确删除历史修改记录(图文详解)
不多说,直接上干货! 答:这些你想删除的话得得去数据库里删除,最好别删除 . 现在默认就是使用好的配置 欢迎大家,加入我的微信公众号:大数据躺过的坑 人工智 ...
- 安装cloudermanager时出现Acquiring installation lock问题(图文详解)
不多说,直接上干货! 问题详情 解决办法 哪一个节点被锁就删除哪一个. 解决办法:进入/tmp 目录,ls -a查看,删除scm_prepare_node.*的文件,以及.scm_prepare_no ...
随机推荐
- coco2d-js demo程序之滚动的小球
近期有一个游戏叫围住神经猫,报道说是使用html5技术来做的. html5的跨平台的优良特性非常不错.对于人手不足,技术不足,选用html5技术实现跨平台的梦想真是不错. 近期在看coco2d-js这 ...
- js 判断对象中所有属性是否为空
测试: var obj = {a:"123",b:""}; for(var key in obj){ if(!obj[key]) return; } 函数封装: ...
- USACO castle
<pre name="code" class="cpp"><pre>USER: Kevin Samuel [kevin_s1] TASK ...
- kill mediaserver脚本
#!/bin/bash adb shell kill $(adb shell ps | grep mediaserver | awk '{print $2}') adb shell pm clear ...
- Android中个人推崇的数据库使用方式
手机应用开发中常常会使用到数据库存储一些资料或者进行数据缓存,android中为我们提供了一个轻量的数据库.在上层进行了一层封装,同一时候还为我们提供了ContentProvider的框架.方便我们进 ...
- java 报错非法的前向引用
今天在看<thinking in java>的时候,第四章提到了非法的前向引用,于是自己试了一下,书中的例子倒是一下就明白了,但是自己写的一个却怎么也不明白,于是上网问了一位前辈,终于明白 ...
- ffmpeg转码本地文件(一)
ffmpeg转码本地文件(一) 实现目标:输入本地文件.实现本地文件转码,里面包括mux层转码,codec层转码,视频格式转换,音频重採样等功能,功能点请看凝视.注意:凝视非常重要. #ifndef ...
- iPhone开发关于UDID和UUID的一些理解【转】
原文地址:http://blog.csdn.net/xunyn/article/details/13629071 一.UDID(Unique Device Identifier) UDID是Uniqu ...
- debian repository的成长过程
1 基本概念 1.1 健康的安装 在端系统中的一次健康的安装指的是,在安装的包的集合中,所有的依赖都满足,并且没有冲突存在. 这的健康的安装是相对于端系统而言的,并不是相对于整个repo而言的.对整个 ...
- JavaScript 图片广告自动与手动的切换
1.代码 <html> <head> <script type="text/javascript" src="jquery-1.8.j ...