Ambari集群里操作时典型权限问题put: `/home/bigdata/1.txt': No such file or directory的解决方案(图文详解)
不多说,直接上干货!
问题详情
明明put该有的文件在,可是怎么提示的是文件找不到的错误呢?
我就纳闷了put: `/home/bigdata/1.txt': No such file or directory
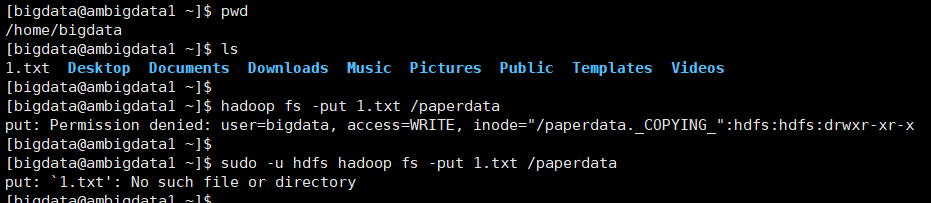
[bigdata@ambigdata1 ~]$ pwd
/home/bigdata
[bigdata@ambigdata1 ~]$ ls
.txt Desktop Documents Downloads Music Pictures Public Templates Videos
[bigdata@ambigdata1 ~]$
[bigdata@ambigdata1 ~]$ hadoop fs -put .txt /paperdata
put: Permission denied: user=bigdata, access=WRITE, inode="/paperdata._COPYING_":hdfs:hdfs:drwxr-xr-x
[bigdata@ambigdata1 ~]$
[bigdata@ambigdata1 ~]$ sudo -u hdfs hadoop fs -put .txt /paperdata
put: `.txt': No such file or directory
[bigdata@ambigdata1 ~]$
问题原因
其实是,权限的问题。
刚开始,我也纳闷,报没有文件错误,经过排查是权限问题,同时,在hdfs用户切换过来也得到了验证。
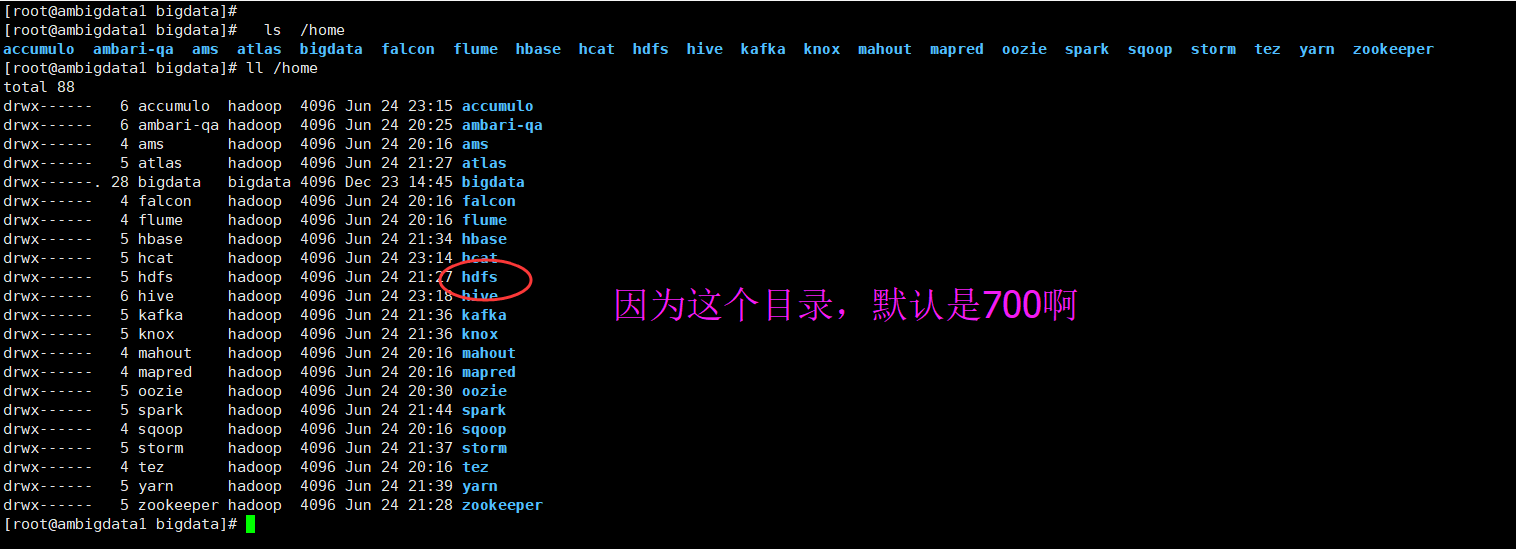
除了自己谁都 操作不了。
bigdata用户是我安装ambari集群时候的用户,是除了自己bigdata这个用户之外,以及root用户,其余全都无法操作。
问题解决办法
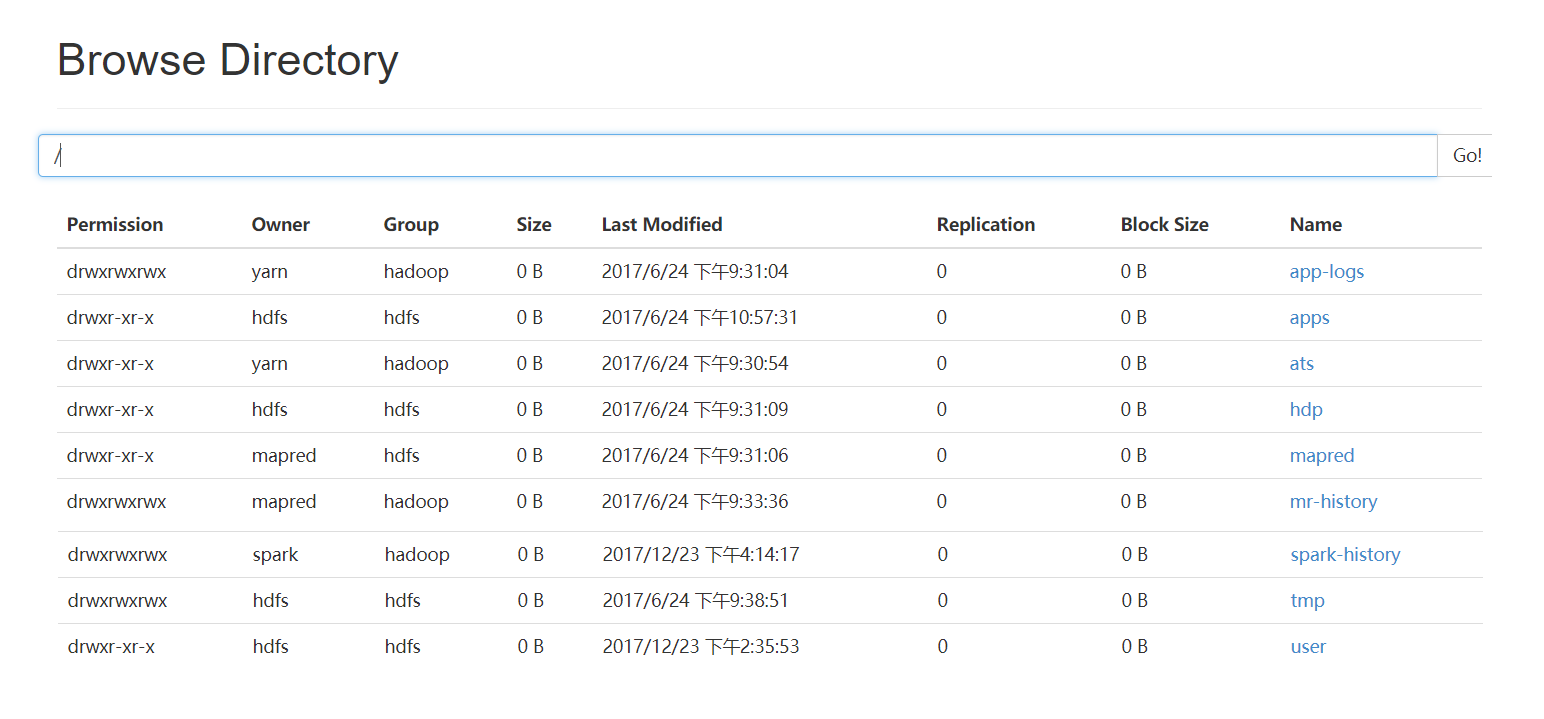
[bigdata@ambigdata1 ~]$ sudo -u hdfs hadoop fs -mkdir /papaerdata
[bigdata@ambigdata1 ~]$ sudo -u hdfs hadoop fs -chmod -R 777 /papaerdata
[root@ambigdata1 ~]# chmod 755 -R /root
[root@ambigdata1 bigdata]# sudo -u hdfs hadoop fs -chmod -R 777 /paperdata
[root@ambigdata1 bigdata]# hadoop fs -put 1.txt /paperdata
成功!
切换到hdfs上验证下(必须得先从)
[bigdata@ambigdata1 ~]$ su root
Password:
[root@ambigdata1 bigdata]# su hdfs
[hdfs@ambigdata1 bigdata]$
[hdfs@ambigdata1 ~]$ touch 2.txt
[hdfs@ambigdata1 ~]$ hadoop fs -put 2.txt /paperdata
[hdfs@ambigdata1 ~]$
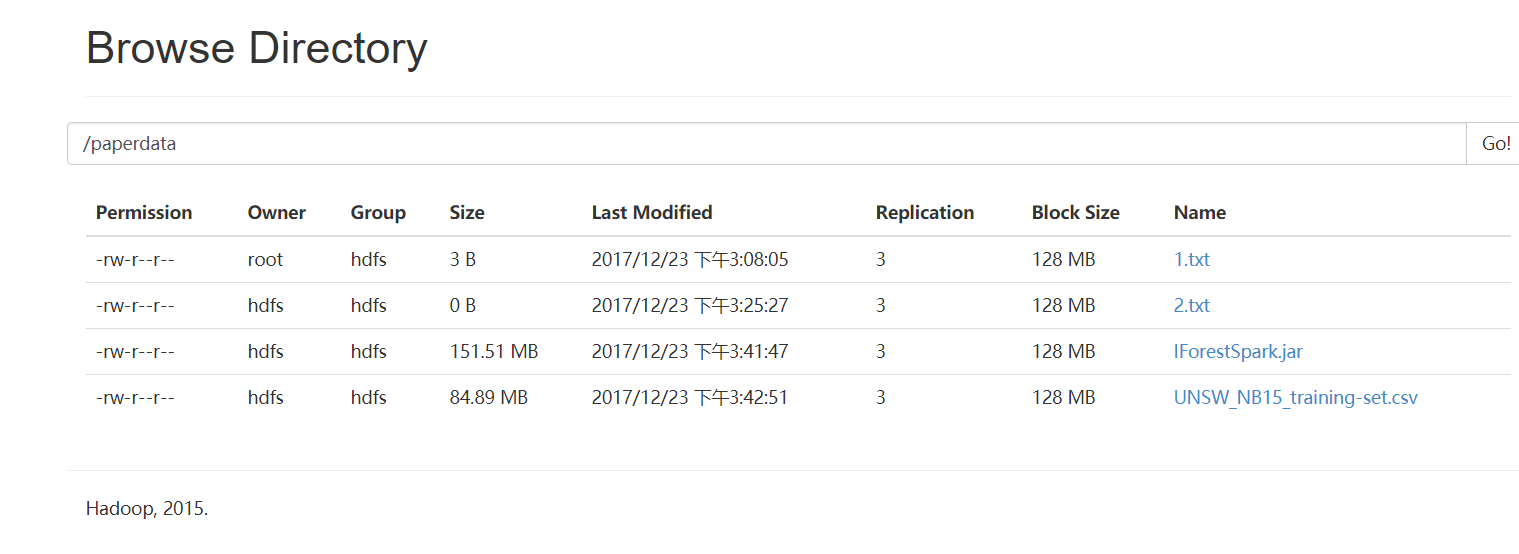
如果想删除,则
[root@ambigdata1 bigdata]# sudo -u hdfs hadoop fs -rm -r /paperdata/1.txt
17/12/23 16:50:18 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 360 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://ambigdata1:8020/paperdata1.txt' to trash at: hdfs://ambigdata1:8020/user/hdfs/.Trash/Current
[root@ambigdata1 bigdata]#
spark-submit --master yarn-cluster --num-executors 4 --driver-memory 4g --executor-memory 4g --executor-cores 4 --class iforest.TestIF hdfs://ambigdata1:9000/paperdata/IForestSpark.jar hdfs://ambigdata1:9000/paperdata/UNSW-NB15_change.csv hdfs://ambigdata1:9000/paperdata/out
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



Ambari集群里操作时典型权限问题put: `/home/bigdata/1.txt': No such file or directory的解决方案(图文详解)的更多相关文章
- 给Ambari集群里安装可视化分析利器工具Hue步骤(图文详解)
扩展博客 以下,是我在手动的CDH版本平台下,安装Hue. CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz) ...
- 给ambari集群里的kafka安装基于web的kafka管理工具Kafka-manager(图文详解)
不多说,直接上干货! 参考博客 基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8.0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口 ...
- 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
不多说,直接上干货! Impala和Hive的关系(详解) 扩展博客 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解) 参考 horton ...
- ambari集群里如何正确删除历史修改记录(图文详解)
不多说,直接上干货! 答:这些你想删除的话得得去数据库里删除,最好别删除 . 现在默认就是使用好的配置 欢迎大家,加入我的微信公众号:大数据躺过的坑 人工智 ...
- CentOS5/6/7系统下搭建安装Amabari大数据集群时出现SSLError: Failed to connect. Please check openssl library versions.错误的解决办法(图文详解)
不多说,直接上干货! ========================== Creating target directory... ========================== Comman ...
- ClouderManger搭建大数据集群时ERROR 2003 (HY000): Can't connect to MySQL server on 'ubuntucmbigdata1' (111)的问题解决(图文详解)
问题详情 相关问题的场景,是在我下面的这篇博客里 Cloudera Manager安装之利用parcels方式(在线或离线)安装3或4节点集群(包含最新稳定版本或指定版本的安装)(添加服务)(Ubun ...
- Spark Mllib里如何将如温度、湿度和风速等数值特征字段用除以***进行标准化(图文详解)
不多说,直接上干货! 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第18章 决策树回归分类Bike Sharing数据集
- 给Clouderamanager集群里安装可视化分析利器工具Hue步骤(图文详解)
扩展博客 以下,是我在手动的CDH版本,安装Hue. CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主 ...
- 给Clouderamanager集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
这个很简单,在集群机器里,选择就是了,本来自带就有Impala的. 扩展博客 给Ambari集群里安装基于Hive的大数据实时分析查询引擎工具Impala步骤(图文详解)
随机推荐
- 寻找最大的K个数(上)
这是一道很经典的题目,有太多方法了,今天写了两种方法,分别是快排和堆排序 #include <iostream> using namespace std; #define N 25 //初 ...
- Python学习-14.Python的输入输出(三)
在Python中写文件也是得先打开文件的. file=open(r'E:\temp\test.txt','a') file.write('append to file') file.close() 第 ...
- Linux Guard Service - 守护进程再次分裂子进程
当系统区内存不能再申请新进程的时候申请会失败 在512MB内存下最多分配的子进程数 3331 [root@localhost 05]# ./test5-1 50000 expect 50000 sub ...
- solr特点五: MoreLikeThis(查找相似页面)
在 Google 上尝试一个查询,您会注意到每一个结果都包含一个 “相似页面” 链接,单击该链接,就会发布另一个搜索请求,查找出与起初结果类似的文档.Solr 使用MoreLikeThisCompon ...
- 10-11Linux用户管理规则及用户管理函数
用户管理: useradd, userdel, usermod, passwd, chsh, chfn, finger, id, chage 组管理: groupadd, groupdel, grou ...
- AndroidSDK下载
C:\Windows\System32\drivers\etc\hosts74.125.237.1 dl-ssl.google.com
- 2、Windows下安装配置Redis
windows下redis软件开源安装包挂载到github上,下面将详细介绍如何在windows下安装redis服务器 下载地址:https://github.com/MSOpenTech/redis ...
- web负载均衡【总结归纳所有看过的资料的理论】
web负载均衡 在有些时候进行扩展是显而易见的,比如下载服务由于带宽不足而必须进行的扩展,但是,另一些时候,很多人一看到站点性能不尽如人意,就马上实施负载均衡等扩展手段,真的需要这样做吗?当然这个问题 ...
- 《快学Scala》第四章 映射与元组
- 通过Jenkins进行提权的一个思路
作者:欧根亲王号 所属团队:Arctic Shell Jenkins是一款由Java编写的开源的持续集成工具,其本身具有执行脚本的功能 在Jenkins的说明信息中列出我们可以使用任意Groovy ...