hadoop 中balance 机制
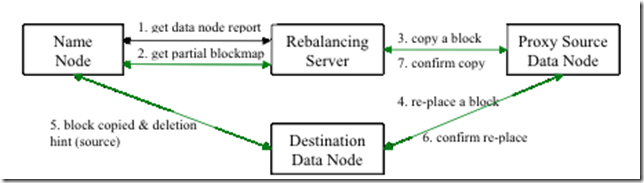
hadoop 中balance 机制的更多相关文章
- hbase中balance机制
HBase是一种支持自动负载均衡的分布式KV数据库,在开启balance的开关(balance_switch)后,HBase的HMaster进程会自动根据指定策略挑选出一些Region,并将这些Reg ...
- 3 weekend110的hadoop中的RPC框架实现机制 + hadoop中的RPC应用实例demo
hadoop中的RPC框架实现机制 RPC是Remotr Process Call, 进程间的远程过程调用,不是在一个jvm里. 即,Controller拿不到Service的实例对象. hadoop ...
- 1 weekend110的复习 + hadoop中的序列化机制 + 流量求和mr程序开发
以上是,weekend110的yarn的job提交流程源码分析的复习总结 下面呢,来讲weekend110的hadoop中的序列化机制 1363157985066 13726230503 ...
- HADOOP高可用机制
HADOOP高可用机制 HA运作机制 什么是HA HADOOP如何实现HA HDFS-HA详解 HA集群搭建 目标: 掌握分布式系统中HA机制的思想 掌握HADOOP内置HA的运作机制 掌握HADOO ...
- Hadoop中客户端和服务器端的方法调用过程
1.Java动态代理实例 Java 动态代理一个简单的demo:(用以对比Hadoop中的动态代理) Hello接口: public interface Hello { void sayHello(S ...
- MapReduce中作业调度机制
MapReduce中作业调度机制主要有3种: 1.先入先出FIFO Hadoop 中默认的调度器,它先按照作业的优先级高低,再按照到达时间的先后选择被执行的作业. 2.公平调度器(相当于时间 ...
- Hadoop 中疑问解析
Hadoop 中疑问解析 FAQ问题剖析 一.HDFS 文件备份与数据安全性分析1 HDFS 原理分析1.1 Hdfs master/slave模型 hdfs采用的是master/slave模型,一个 ...
- hadoop 错误处理机制
hadoop 错误处理机制 1.硬件故障 硬件故障是指jobtracker故障或TaskTracker 故障 jobtracker是单点,若发生故障,目前hadoop 还无法处理,唯有选择最牢靠的硬件 ...
- Hadoop 中 IPC 的源码分析
最近开始看 Hadoop 的一些源码,展开hadoop的源码包,各个组件分得比较清楚,于是开始看一下 IPC 的一些源码. IPC模块,也就是进程间通信模块,如果是在不同的机器上,那就可以理解为 RP ...
随机推荐
- [iOS]被忽略的main函数
如同任何基于C的应用程序,程序启动的主入口点为iOS应用程序的main函数.在iOS应用程序,main函数的作用是很少的.它的主要工作是控制UIKit framework.因此,你在Xcode中创建任 ...
- linux下安装protobuf及cmake编译
一.protobuf 安装 protobuf版本:2.6.1 下载地址:https://github.com/google/protobuf/archive/v2.6.1.zip 解压之后进入目录 修 ...
- flAbsPath on /var/lib/dpkg/status failed 解决 Cydia 红字
越狱之后抹掉所有数据,然后再使用 doubleH3lix 越狱成功后,打开 Cydia 会提示如下错误: flAbsPath on /var/lib/dpkg/status failed - real ...
- 需求:加一个下拉框选择条件改变饼图内外环 饼图:百度echarts提供
1.1:下拉框条件:后台取得ViewBag传给前台 MonitorController: public ActionResult BigData(): //下拉框筛选条件 var result = M ...
- pycharm社区版新建django文件不友好操作
一.cmd操作 1.django-admin startproject (新建project名称) 2.在pycharm打开project,运行终端输入:python manage.py starta ...
- 基于visual studio 2017 以及cubemx 搭建stm32的开发环境(0)
(1)安装visual studio 2017 官网下载安装即可 (2)安装visual GDB 链接:https://pan.baidu.com/s/1TgXI1BRQLAWiWlqCcIS9TA ...
- A.Activity planning
题目描述There is a collection of n activities E={1,2,..,n}, each of which requires the same resource, su ...
- Python之文件及文件系统
open() 方法: Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError. 注意:使用 open( ...
- 2016-2017-2 20155322 实验三 敏捷开发与XP实践
2016-2017-2 20155322 实验三 敏捷开发与XP实践 实验内容 XP基础 XP核心实践 相关工具 实验知识点 敏捷开发(Agile Development)是一种以人为核心.迭代.循序 ...
- #20155327 2016-2017-2 《Java程序设计》第三周学习总结
20155327 2016-2017-2 <Java程序设计>第三周学习总结 教材学习内容总结 一.三种重要的数字表示 无符号:编码基于传统的二进制表示法,表示大于或者等于零的数字. 补码 ...