Spark之编程模型RDD
前言:Spark编程模型两个主要抽象,一个是弹性分布式数据集RDD,它是一种特殊集合,支持多种数据源,可支持并行计算,可缓存;另一个是两种共享变量,支持并行计算的广播变量和累加器。
1.RDD介绍
Spark大数据处理平台建立在RDD之上,RDD是Spark的核心概念,最主要的抽象之一。RDD和Spark之间的关系是,RDD是一种基于内存的具有容错性的集群抽象方法,Spark是这个抽象方法的实现。
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
1.1 RDD的特征
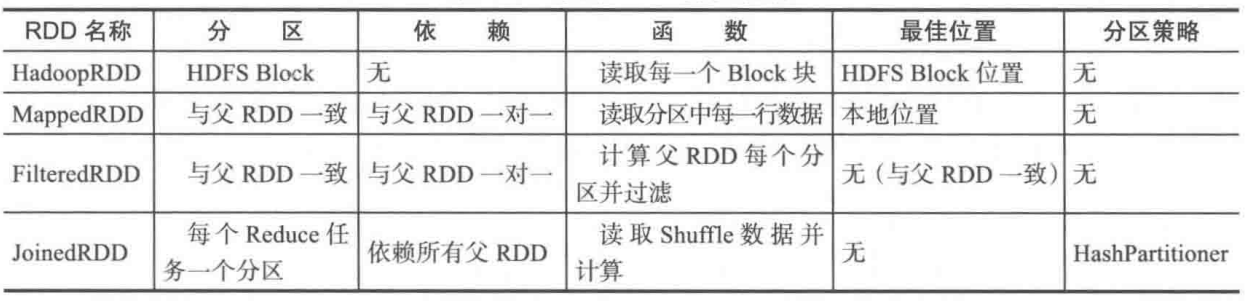
(1)分区(Partition):一个数据分片列表。能够将数据切分,切分好的数据能够进行并行计算,是数据集的原子组成部分。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)函数(Compute):一个计算RDD每个分片的函数。RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)依赖(Dependency):RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)优先位置(可选):一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
(5)分区策略(可选):一个Partitioner,即RDD的分片函数,描述分区的模式和数据存放的位置。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
常见的RDD有很多种,每个Transformation操作都会产生一种RDD,一下是各种RDD特征比较。
1.2 RDD依赖
Spark之编程模型RDD的更多相关文章
- Spark核心编程---创建RDD
创建RDD: 1:使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用流程. 2:使用本地文件创建RDD,主要用于临时性地处 ...
- spark wordcount 编程模型详解
spark wordcount中一共经历多少个RDD?以及RDD提供的toDebugString 在控制台输入spark-shell 系统会默认创建一个SparkContext sc h ...
- Spark 编程模型(上)
Spark的编程模型 核心概念(注意对比MR里的概念来学习) Spark Application的组成 Spark Application基本概念 Spark Application编程模型 回顾sc ...
- Spark编程模型(博主推荐)
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- Spark1.0.0 编程模型
Spark Application能够在集群中并行执行,其关键是抽象出RDD的概念(详见RDD 细解),也使得Spark Application的开发变得简单明了.下图浓缩了Spark的编程模型. w ...
- Spark编程模型(RDD编程模型)
Spark编程模型(RDD编程模型) 下图给出了rdd 编程模型,并将下例中用 到的四个算子映射到四种算子类型.spark 程序工作在两个空间中:spark rdd空间和 scala原生数据空间.在原 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- Spark:Spark 编程模型及快速入门
http://blog.csdn.net/pipisorry/article/details/52366356 Spark编程模型 SparkContext类和SparkConf类 代码中初始化 我们 ...
随机推荐
- CocoaPods安装指定版本
Cocoapods目前最新的正式版本是0.35.0,如果升级到这个版本,并且在project中使用XMPPFramework,在pod install之后会出现如下循环依赖的问题 There is a ...
- HDU 3038 How Many Answers Are Wrong(带权并查集,真的很难想到是个并查集!!!)
How Many Answers Are Wrong Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Ja ...
- Linux Shell常用技巧(十二)
二十三. Bash Shell编程: 1. 读取用户变量: read命令是用于从终端或者文件中读取输入的内建命令,read命令读取整行输入,每行末尾的换行符不被读入.在read命令后面,如果 ...
- 搭建springboot项目
1.搭建环境windows10+jdk1.8+eclipse4.8+maven 2.为了学习微服务架构学习搭建基础项目 3.分为两种搭建方式为maven项目和单独建立springboot项目(ecli ...
- Linux-- 目录基本操作(2)
cp 复制文件或目录 用法:cp [OPTION] SOURCE源文件 DIRECTORY目标文件,具体可以查看 man cp 以常用的参数举例 [root@hs-192-168-33-206 tom ...
- iOS audio不支持循环播放
解决办法:监听播放完成事件(注意点,audio标签不能设置循环播放,去除标签 loop="loop"或者 loop="false",不然不走播放完成事件) $( ...
- linux 学习第十六天(Samba配置)
Samba 服务 yum install samba mv smb.conf smb.conf.bak cat smb.conf.bak | grep -v "#" | grep ...
- MySQLFront导入SQL文件报#1113错误解决
- Kafka监控与调优
Kafka监控 五个维度来监控Kafka 监控Kafka集群所在的主机 监控Kafka broker JVM的表现 监控Kafka Broker的性能 监控Kafka客户端的性能.这里的所指的是广义的 ...
- gulp 输出到同一目录
gulp.task('jsx', function () { var src='app/script/**/*.jsx'; // src='app/script/components/selloff/ ...