Elasticsearch入门和查询语法分析(ik中文分词)
全文搜索现在已经是很常见的功能了,当然你也可以用mysql加Sphinx实现。但开源的Elasticsearch(简称ES)目前是全文搜索引擎的首选。目前像GitHub、维基百科都使用的是ES,它可以快速的存储,搜索和分析数据。
一、安装与启动
ES的运行需要依赖java环境,可以在命令行运行 java --version 。如果出现

说明已经安装了,否则你就需要安装下java环境。
然后我们就可以开始装ES了。1、可以用docker容器安装。2、用压缩包安装。
我是用压缩包安装的。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.1.tar.gz
tar -xzf elasticsearch-6.3..tar.gz
cd elasticsearch-6.3./
然后输入 ./bin/elasticsearch 就可以启动ES了。在浏览器上输入 localhost: ,如果出现
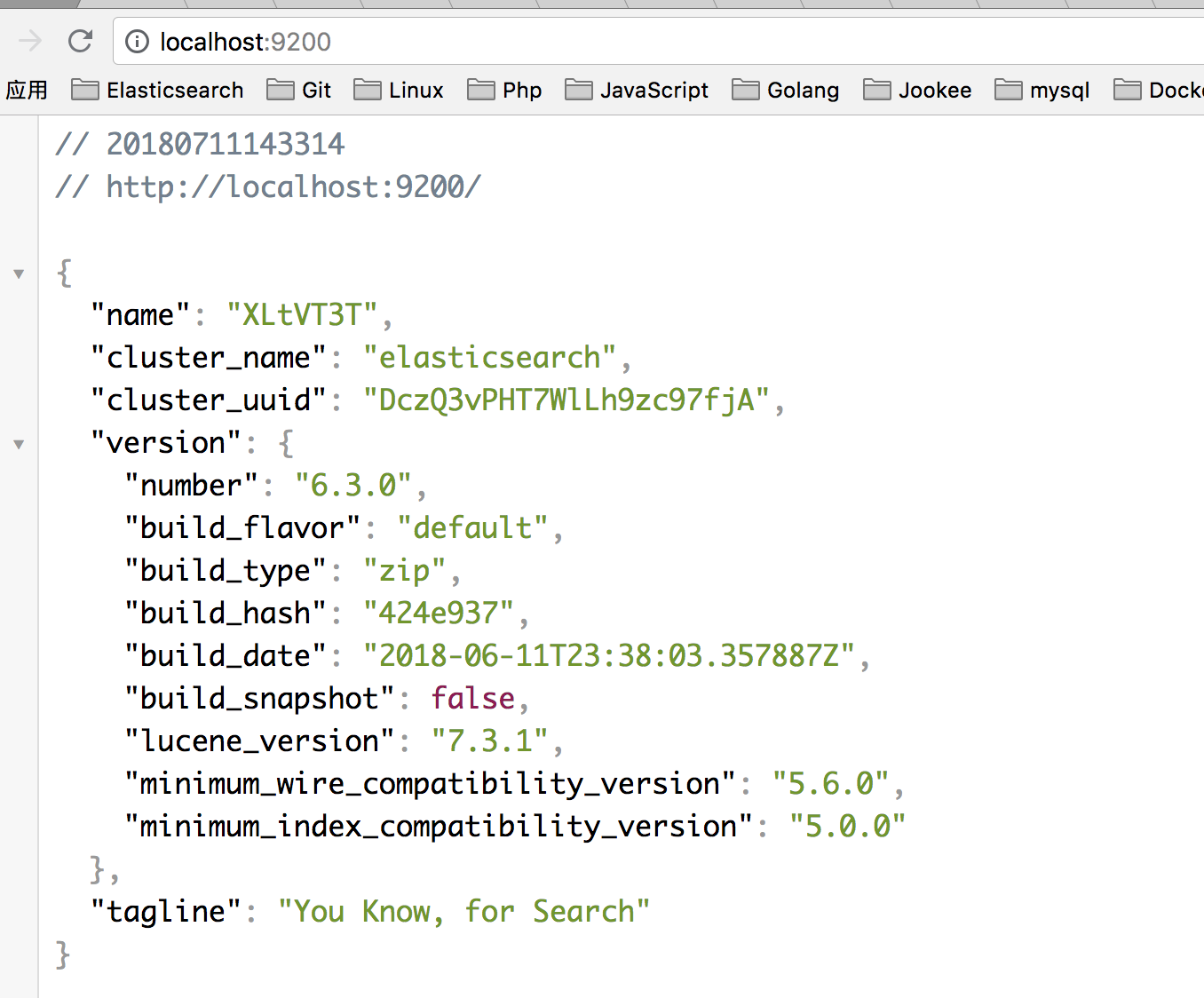
就说明ES成功跑起来了。
不了解ES的同学可以去看看阮老师的这篇文章http://www.ruanyifeng.com/blog/2017/08/elasticsearch.html。
二、IK分词
ES默认的分词是英文分词,对中文分词支持的并不好。所以我们就需要安装ik中文分词。让我们看看区别。
在这里需要说明的一点时,ES很多API请求都是GET带上了Request Body。所以通过浏览器或者postman等工具发起GET请求时会报错。有两种方法可以解决。
1、通过命令含的curl请求。
curl -X GET "localhost:9200/_analyze" -H 'Content-Type: application/json' -d'
{
"analyzer" : "standard",
"text" : "this is a test"
}
'
2、在代码中通过curl请求。
// 通过php的guzzle包发起的请求
$client = new Client();
$response = $client->get('localhost:9200/_analyze', [
'json' => [
'analyzer' => 'standard',
'text' => "功能进阶",
]
]); $res = ($response->getBody()->getContents());
然后我们来看看ik中文分词和ES默认的分词区别。同样是上面的请求
ES默认分词结果
{
"tokens": [
{
"token": "功",
"start_offset": ,
"end_offset": ,
"type": "<IDEOGRAPHIC>",
"position":
},
{
"token": "能",
"start_offset": ,
"end_offset": ,
"type": "<IDEOGRAPHIC>",
"position":
},
{
"token": "进",
"start_offset": ,
"end_offset": ,
"type": "<IDEOGRAPHIC>",
"position":
},
{
"token": "阶",
"start_offset": ,
"end_offset": ,
"type": "<IDEOGRAPHIC>",
"position":
}
]
}
ik中文分词结果
ik分词也分两种分析器。ik_smart:尽可能少的进行中文分词。ik_max_word:尽可能多的进行中文分词。
$response = $client->get('localhost:9200/_analyze', [
'json' => [
'analyzer' => 'ik_max_word',
'text' => "功能进阶",
]
]);
得到的结果为:
{
"tokens": [
{
"token": "功能",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "能进",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "进阶",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
而ik_smart
$response = $client->get('localhost:9200/_analyze', [
'json' => [
'analyzer' => 'ik_smart',
'text' => "功能进阶",
]
]);
的结果为
{
"tokens": [
{
"token": "功能",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "进阶",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
其实他们的区别通过名字你也可以略知一二。哈哈。。。
假如有人想问,我就想把“功能进阶”当成一个词来搜索,可以吗?
Of course!!
这时候我们就要自定义分词。进入你的ES目录,运行 cd config/analysis-ik/ 进去ik分词的配置。找到IKAnalyzer.cfg.xml文件,然后 vi IKAnalyzer.cfg.xml 。

我在 elasticsearch-6.3./config/analysis-ik 目录下,创建了 custom/mydict.dic ,然后添加到上图的红色框框中,这就是你自定义分词的文件。如果有多个文件,可以用英文分号(;)隔开。

可以看到,我在自定义中文分词文件中添加了“功能进阶”这个词。这时候用ik_smart分析器的结果是:
{
"tokens": [
{
"token": "功能进阶",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
很好,这就是我们想要的。
三、Query DSL
- match
查询语法如下:title是需要查询的字段名,可以被替换成任何字段。query对应的是所需的查询。比如这里会被拆分成‘php’和‘后台’,应为operator是or,所以ES会去所有数据里的title字段查询包含‘后台’和‘php’的,如果operator为and,这查询的是即包含‘后台’又有‘php’的数据,这应该很好理解。
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'match' => [
'title' => [
'query' => '后台php',
'operator' => 'or',
]
]
]
]
]);
- multi_match
如果想在多个字段中查找,那就需要用到multi_match查询,语法如下:
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'multi_match' => [
'query' => '张三 php',
'fields' => ['title', 'desc', 'user']
]
]
]
]);
- query_string
查询语法如下:类似match查询的operator,在这里需要在query中用OR或AND实现。
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'query_string' => [
'query' => '(张三) OR (php)',
'default_field' => 'title',
]
]
]
]);
多字段查询如下:
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'query_string' => [
'query' => '(张三) OR (php)',
'fields' => ['title', 'user'],
]
]
]
]);
- range query
这是范围查询,例如查询年龄在10到20岁之间的。查询语法如下:
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'range' => [
'age' => [
'gte' => 10,
'lte' => 20,
],
]
]
]
]);
gte表示>=,lte表示<=,gt表示>,lt表示<。
- bool查询
bool查询的语法都是一样的。如下:
$response = $client->get('localhost:9200/accounts/person/_search', [
'json' => [
'query' => [
'bool' => [
'must/filter/should/must_not' => [
[
'query_string' => [
'query' => '研发',
]
],
[
'range' => [
'age' => [
'gt' => 20
]
]
],
],
]
]
]
]);
1)must:must查询是查询字段中必须满足上面两个条件,并且会计算到score中。
2)filter:filter查询与must一样,都必须满足上面两个条件,只不过查询结果不会计算score,也就是score始终为0.
3)should:should查询只需要满足上面两种查询条件中的一种即可。
4)must_not:must_not查询是必须不满足上面两个查询条件。
以上也是我看文档总结出来的,如有不对的地方,望大神指点。
Elasticsearch入门和查询语法分析(ik中文分词)的更多相关文章
- elasticsearch ik中文分词器安装
特殊说明:灰色文字用来辅助理解的. 安装IK中文分词器 我在百度上搜索了下,大多介绍的都是用maven打包下载下来的源码,这种方法也行,但是不够方便,为什么这么说? 首先需要安装maven吧?其次需要 ...
- ElasticSearch速学 - IK中文分词器远程字典设置
前面已经对”IK中文分词器“有了简单的了解: 但是可以发现不是对所有的词都能很好的区分,比如: 逼格这个词就没有分出来. 词库 实际上IK分词器也是根据一些词库来进行分词的,我们可以丰富这个词库. ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
- elasticsearch使用ik中文分词器
elasticsearch使用ik中文分词器 一.背景 二.安装 ik 分词器 1.从 github 上找到和本次 es 版本匹配上的 分词器 2.使用 es 自带的插件管理 elasticsearc ...
- Elasticsearch:IK中文分词器
Elasticsearch内置的分词器对中文不友好,只会一个字一个字的分,无法形成词语,比如: POST /_analyze { "text": "我爱北京天安门&quo ...
- Solr5.5.1 IK中文分词配置与使用
前言 用过Lucene.net的都知道,我们自己搭建索引服务器时和解决搜索匹配度的问题都用到过盘古分词.其中包含一个词典. 那么既然用到了这种国际化的框架,那么就避免不了中文分词.尤其是国内特殊行业比 ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- 对本地Solr服务器添加IK中文分词器实现全文检索功能
在上一篇随笔中我们提到schema.xml中<field/>元素标签的配置,该标签中有四个属性,分别是name.type.indexed与stored,这篇随笔将讲述通过设置type属性的 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
随机推荐
- 使用button的open-type="getUserInfo"引导用户进行授权
https://blog.csdn.net/weixin_39602178/article/details/80295684 一. 前言 小程序官方文档,上面说明 > wx.getUserInf ...
- Oracle - ORA-28547: Connection to server failed,probable Oracle Net admin error (Navicat)
一.异常 用Navicat连接Oracle数据库时抛出的异常 二.方案 使用 Oracle 安装目录 \Oracle\product\11.2.0\dbhome_1\BIN 下的 oci.dll 替换 ...
- [翻译] JTSlideShadowAnimation
JTSlideShadowAnimation 效果图: JTSlideShadowAnimation allow you to reproduce the famous "slide to ...
- 3D旋转相册的实现
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Win10设置多时区时钟方法技巧
Win10设置多时区时钟方法技巧,本文小编将向大家介绍如何设置多个时区时钟,以及如何使用「闹钟和时钟」应用跟踪更多时区,感兴趣的朋友可以参考下面教程操作. Win10系统允许用户配置最多3个不同的时钟 ...
- Undirected Graphs
无向图 Introduction 图是由边连接的点的集合,有着广泛的应用空间. 一些图的术语,点,边,路径,环(圈),连通分量(子图). 简单路径不重复经过点,简单环不含有重复点和边,简单图不含自环和 ...
- Java 多态(接口)
有两种意义的多态,一是操作名称的多态,即有多个操作具有相同的名字,但这些操作所接收的消息类型必须不同(方法重载).另一种多态是和继承有关的多态,是指同一个操作被不同类型对象调用时可能产生不同的行为(方 ...
- 中石油大学统考(大学英语B)押题笔记
二. 词汇与结构 1. I will.意为“我会的”,固定搭配. 2. get tired of 是词组“对…厌烦了”的意思. 3. — ________ is your girl friend li ...
- 30、springboot与检索(2)
项目中进行整合: 1.整合 新建项目加入依赖(NoSql) springboot默认使用SpringDate ElasticSearch模块进行操作 查看自动配置类: SpringBoot默认支持 ...
- PHP延迟静态绑定(本文属于转发)
这段时间看项目后台的PHP代码,看到了类似于以下的一段代码,我把它抽出来: <?php class DBHandler { function get() {} } class MySQLHand ...