人工智能: 自动寻路算法实现(四、D、D*算法)
博客转载自:https://blog.csdn.net/kongbu0622/article/details/1871520
据 Drew 所知最短路经算法现在重要的应用有计算机网络路由算法,机器人探路,交通路线导航,人工智能,游戏设计等等。美国火星探测器核心的寻路算法就是采用的D*(D Star)算法。最短路经计算分静态最短路计算和动态最短路计算。静态路径最短路径算法是外界环境不变,计算最短路径。主要有Dijkstra算法,A*(A Star)算法。 动态路径最短路是外界环境不断发生变化,即不能计算预测的情况下计算最短路。如在游戏中敌人或障碍物不断移动的情况下。典型的有D*算法。

这是Drew程序实现的10000个节点的随机路网三条互不相交最短路
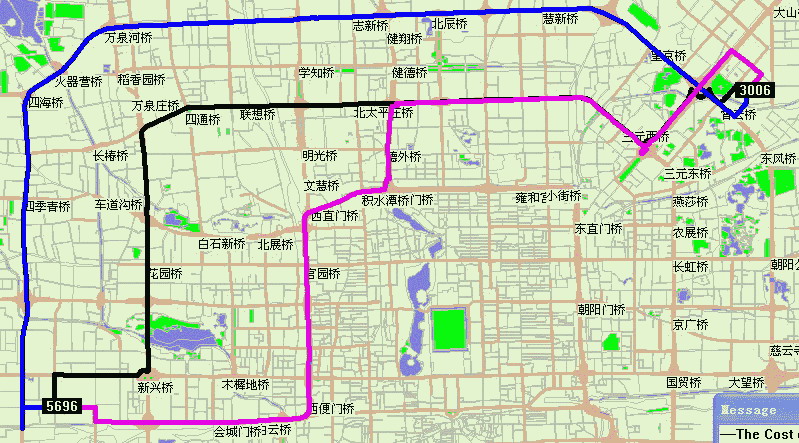
真实路网计算K条路径示例:节点5696到节点3006,三条最快速路,可以看出路径基本上走环线或主干路。黑线为第一条,兰线为第二条,红线为第三条。约束条件系数为1.2。共享部分路段。 显示计算部分完全由Drew自己开发的程序完成。
参见 K条路算法测试程序
Dijkstra算法求最短路径
Dijkstra算法是典型最短路算法,用于计算一个节点到其他所有节点的最短路径。主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。Dijkstra算法能得出最短路径的最优解,但由于它遍历计算的节点很多,所以效率低。Dijkstra算法是很有代表性的最短路算法,在很多专业课程中都作为基本内容有详细的介绍,如数据结构,图论,运筹学等等。Dijkstra一般的表述通常有两种方式,一种用永久和临时标号方式,一种是用OPEN, CLOSE表方式,Drew为了和下面要介绍的 A* 算法和 D* 算法表述一致,这里均采用OPEN,CLOSE表的方式。
大概过程:
创建两个表,OPEN, CLOSE。OPEN表保存所有已生成而未考察的节点,CLOSED表中记录已访问过的节点。
1. 访问路网中里起始点最近且没有被检查过的点,把这个点放入OPEN组中等待检查。
2. 从OPEN表中找出距起始点最近的点,找出这个点的所有子节点,把这个点放到CLOSE表中。
3. 遍历考察这个点的子节点。求出这些子节点距起始点的距离值,放子节点到OPEN表中。
4. 重复2,3,步。直到OPEN表为空,或找到目标点。
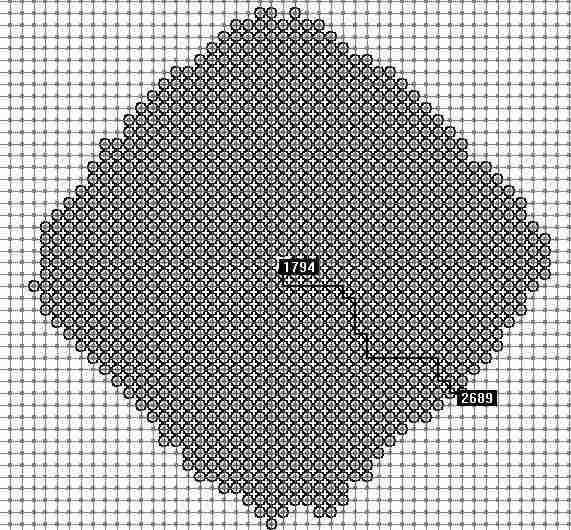
这是在drew 程序中4000个节点的随机路网上Dijkstra算法搜索最短路的演示,黑色圆圈表示经过遍历计算过的点由图中可以看到Dijkstra算法从起始点开始向周围层层计算扩展,在计算大量节点后,到达目标点。所以速度慢效率低。提高Dijkstra搜索速度的方法很多,据Drew所知,常用的有数据结构采用Binary heap的方法,和用Dijkstra从起始点和终点同时搜索的方法。
推荐网页:http://www.cs.ecnu.edu.cn/assist/js04/ZJS045/ZJS04505/zjs045050a.htm,简明扼要介绍Dijkstra算法,有图解显示和源码下载。
A*算法 -- 启发式(heuristic)算法
A*(A-Star)算法是一种静态路网中求解最短路最有效的方法。公式表示为:
f(n)=g(n)+h(n)
其中f(n) 是节点n从初始点到目标点的估价函数,g(n) 是在状态空间中从初始节点到n节点的实际代价,h(n)是从n到目标节点最佳路径的估计代价。保证找到最短路径(最优解的)条件,关键在于估价函数h(n)的选取:估价值h(n) <= n到目标节点的距离实际值,这种情况下,搜索的点数多,搜索范围大,效率低。但能得到最优解。如果 估价值 > 实际值, 搜索的点数少,搜索范围小,效率高,但不能保证得到最优解。估价值与实际值越接近,估价函数取得就越好。
例如对于几何路网来说,可以取两节点间欧几理德距离(直线距离)做为估价值,即f=g(n)+sqrt((dx-nx)*(dx-nx)+(dy-ny)*(dy-ny));这样估价函数f在g值一定的情况下,会或多或少的受估价值h的制约,节点距目标点近,h值小,f值相对就小,能保证最短路的搜索向终点的方向进行。明显优于Dijstra算法的毫无无方向的向四周搜索。
主要搜索过程:
创建两个表,OPEN表保存所有已生成而未考察的节点,CLOSED表中记录已访问过的节点。遍历当前节点的各个节点,将n节点放入CLOSE中,取n节点的子节点X并算X的估价值。
While(OPEN != NULL)
{
从OPEN表中取估价值f最小的节点n;
if(n节点 == 目标节点)
break;
else
{
if(X in OPEN) 比较两个X的估价值f //注意是同一个节点的两个不同路径的估价值
if( X的估价值小于OPEN表的估价值 )
更新OPEN表中的估价值; //取最小路径的估价值 if(X in CLOSE) 比较两个X的估价值 //注意是同一个节点的两个不同路径的估价值
if( X的估价值小于CLOSE表的估价值 )
更新CLOSE表中的估价值; 把X节点放入OPEN //取最小路径的估价值 if(X not in both)
求X的估价值;
并将X插入OPEN表中; //还没有排序
} 将n节点插入CLOSE表中;
按照估价值将OPEN表中的节点排序; //实际上是比较OPEN表内节点f的大小,从最小路径的节点向下进行。
}
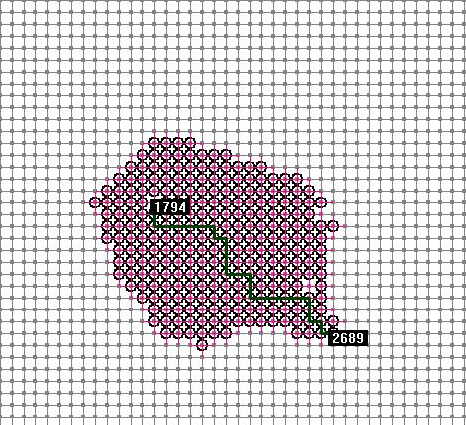
上图是和上面Dijkstra算法使用同一个路网,相同的起点终点,用A*算法的情况,计算的点数从起始点逐渐向目标点方向扩展,计算的节点数量明显比Dijkstra少得多,效率很高,且能得到最优解。A*算法和Dijistra算法的区别在于有无估价值,Dijistra算法相当于A*算法中估价值为0的情况。
推荐文章链接:Amit 斯坦福大学一个博士的游戏网站,上面有关于A*算法介绍和不少有价值的链接 http://theory.stanford.edu/~amitp/GameProgramming/
Sunway写的两篇很好的介绍启发式和A*算法的中文文章并有A*源码下载:初识A*算法 http://creativesoft.home.shangdu.net/AStart1.htm和深入A*算法 http://creativesoft.home.shangdu.net/AStart2.htm
需要注意的是Sunway上面文章“深入A*算法”中引用了一个A*的游戏程序进行讲解,并有这个源码的下载,不过它有一个不小的Bug, 就是新的子节点放入OPEN表中进行了排序,而当子节点在Open表和Closed表中时,重新计算估价值后,没有重新的对Open表中的节点排序,这个问题会导致计算有时得不到最优解,另外在路网权重悬殊很大时,搜索范围不但超过Dijkstra,甚至搜索全部路网, 使效率大大降低。Drew 对这个问题进行了如下修正,当子节点在Open表和Closed表中时,重新计算估价值后,删除OPEN表中的老的节点,将有新估价值的节点插入OPEN表中,重新排序,经测试效果良好,修改的代码如下,红色部分为Drew添加的代码.添加进程序的相应部分即可。
在函数GenerateSucc()中 ...................................
g=BestNode->g+1; /* g(Successor)=g(BestNode)+cost of getting from BestNode to Successor */
TileNumS=TileNum((int)x,(int)y); /* identification purposes */
if ((Old=CheckOPEN(TileNumS)) != NULL)
{
for(c=0;c<8;c++)
if(BestNode->Child[c] == NULL) /* Add Old to the list of BestNode's Children (or Successors). */
break;
BestNode->Child[c]=Old; if (g < Old->g)
{
Old->Parent=BestNode;
Old->g=g;
Old->f=g+Old->h; //Drew 在该处添加如下红色代码
//Implement by Drew
NODE *q,*p=OPEN->NextNode, *temp=OPEN->NextNode;
while(p!=NULL && p->NodeNum != Old->NodeNum)
{
q=p;
p=p->NextNode;
}
if(p->NodeNum == Old->NodeNum)
{
if(p==OPEN->NextNode)
{
temp = temp->NextNode;
OPEN ->NextNode = temp;
}
else
q->NextNode = p->NextNode;
}
Insert(Old); // Insert Successor on OPEN list wrt f
}
......................................................
A*(A Star)算法与D算法的转换
这种算法可以不直接用估价值,直接用Dijkstra算法程序实现A*算法,Drew对它进行了测试,达到和A*完全一样的计算效果,且非常简单。以邻接矩阵为例,更改原来邻接矩阵i行j列元素Dij为 Dij+Djq-Diq; 起始点到目标点的方向i->j, 终点q. Dij为(i到j路段的权重或距离)其中:Djq,Diq的作用相当于估价值 Djq=(j到q的直线距离);Diq=(i到q的直线距离)原理:i 到q方向符合Dij+Djq > Diq ,取Dij+Djq-Diq 小,如果是相反方向Dij+Djq-Diq会很大。因此达到向目标方向寻路的作用。
动态路网 -- 最短路径算法 D*
A* 在静态路网中非常有效(very efficient for static worlds),但不适于在动态路网,环境如权重等不断变化的动态环境下。 D*是动态A*(D-Star,Dynamic A Star) 卡内及梅隆机器人中心的Stentz在1994和1995年两篇文章提出,主要用于机器人探路。是火星探测器采用的寻路算法,见附录1,2.
主要方法(这些完全是Drew在读了上述资料和编制程序中的个人理解,不能保证完全正确,仅供参考)
1.先用Dijstra算法从目标节点G向起始节点搜索。储存路网中目标点到各个节点的最短路和该位置到目标点的实际值h,k(k为所有变化h之中最小的值,
当前为k=h。每个节点包含上一节点到目标点的最短路信息1(2),2(5),5(4),4(7)。则1到4的最短路为1-2-5-4。原OPEN和CLOSE中节点信息保存。
2.机器人沿最短路开始移动,在移动的下一节点没有变化时,无需计算,利用上一步Dijstra计算出的最短路信息从出发点向后追述即可,当在Y点探测
到下一节点X状态发生改变,如堵塞。机器人首先调整自己在当前位置Y到目标点G的实际值h(Y),h(Y)=X到Y的新权值c(X,Y)+X的原实际值h(X).X为下一
节点(到目标点方向Y->X->G),Y是当前点。k值取h值变化前后的最小。
3.用A*或其它算法计算,这里假设用A*算法,遍历Y的子节点,点放入CLOSE,调整Y的子节点a的h值,h(a)=h(Y)+Y到子节点a的权重C(Y,a),比较a点是否存
在于OPEN和CLOSE中,方法如下:
while()
{
从OPEN表中取k值最小的节点Y;
遍历Y的子节点a,计算a的h值 h(a)=h(Y)+Y到子节点a的权重C(Y,a)
{
if(a in OPEN) 比较两个a的h值
if( a的h值小于OPEN表a的h值 )
{
更新OPEN表中a的h值;k值取最小的h值
有未受影响的最短路经存在
break;
}
if(a in CLOSE) 比较两个a的h值 //注意是同一个节点的两个不同路径的估价值
if( a的h值小于CLOSE表的h值 )
{
更新CLOSE表中a的h值; k值取最小的h值;将a节点放入OPEN表
有未受影响的最短路经存在
break;
}
if(a not in both)
将a插入OPEN表中; //还没有排序
}
放Y到CLOSE表;
OPEN表比较k值大小进行排序;
}
机器人利用第一步Dijstra计算出的最短路信息从a点到目标点的最短路经进行。
D*算法在动态环境中寻路非常有效,向目标点移动中,只检查最短路径上下一节点或临近节点的变化情况,如机器人寻路等情况。对于距离远的最短路径上发生的变化,则感觉不太适用。
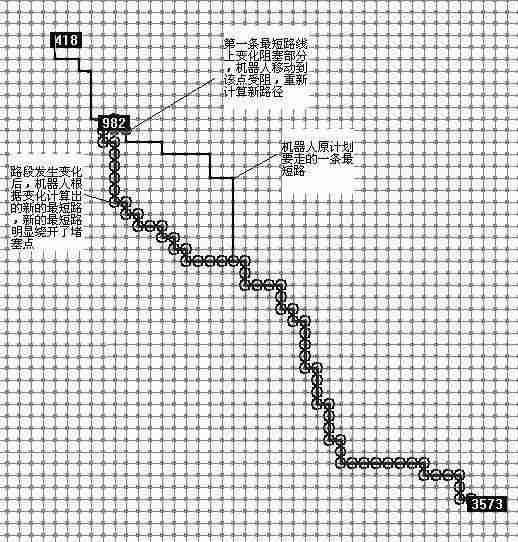
上图是Drew在4000个节点的随机路网上做的分析演示,细黑线为第一次计算出的最短路,红点部分为路径上发生变化的堵塞点,当机器人位于982点时,检测到前面发生路段堵塞,在该点重新根据新的信息计算路径,可以看到圆圈点为重新计算遍历过的点,仅仅计算了很少得点就找到了最短路,说明计算非常有效,迅速。绿线为计算出的绕开堵塞部分的新的最短路径。
附录
1. Optimal and Efficient Path Planning for Partially-Known Environments
2. The Focussed D* Algorithm for Real-Time Replanning
人工智能: 自动寻路算法实现(四、D、D*算法)的更多相关文章
- 图论算法(四)Dijkstra算法
最短路算法(三)Dijkstra算法 PS:因为这两天忙着写GTMD segment_tree,所以博客可能是seg+图论混搭着来,另外segment_tree的基本知识就懒得整理了-- Part 1 ...
- 游戏人工智能 读书笔记 (四) AI算法简介——Ad-Hoc 行为编程
本文内容包含以下章节: Chapter 2 AI Methods Chapter 2.1 General Notes 本书英文版: Artificial Intelligence and Games ...
- 数据挖掘算法(四)Apriori算法
参考文献: 关联分析之Apriori算法
- 人工智能: 自动寻路算法实现(三、A*算法)
博客转载自:https://blog.csdn.net/kwame211/article/details/78139506 本篇文章是机器人自动寻路算法实现的第三章.我们要讨论的是一个在一个M×N的格 ...
- 数据结构与算法JavaScript (四) 串(BF)
串是由零个或多个字符组成的有限序列,又叫做字符串 串的逻辑结构和线性表很相似的,不同的是串针对是是字符集,所以在操作上与线性表还是有很大区别的.线性表更关注的是单个元素的操作CURD,串则是关注查找子 ...
- php 冒泡 快速 选择 插入算法 四种基本算法
php四种基础算法:冒泡,选择,插入和快速排序法 来源:PHP100中文网 | 时间:2013-10-29 15:24:57 | 阅读数:120854 [导读] 许多人都说 算法是程序的核心,一个程序 ...
- Atitti knn实现的具体四个距离算法 欧氏距离、余弦距离、汉明距离、曼哈顿距离
Atitti knn实现的具体四个距离算法 欧氏距离.余弦距离.汉明距离.曼哈顿距离 1. Knn算法实质就是相似度的关系1 1.1. 文本相似度计算在信息检索.数据挖掘.机器翻译.文档复制检测等领 ...
- PHP四种基础算法详解
许多人都说 算法是程序的核心,一个程序的好于差,关键是这个程序算法的优劣.作为一个初级phper,虽然很少接触到算法方面的东西 .但是对于冒泡排序,插入排序,选择排序,快速排序四种基本算法,我想还是要 ...
- 算法第四版 在Eclipse中调用Algs4库
首先下载Eclipse,我选择的是Eclipse IDE for Java Developers64位版本,下载下来之后解压缩到喜欢的位置然后双击Eclipse.exe启动 然后开始新建项目,File ...
随机推荐
- log4j 输入不同日志文件
log4j的强大功能无可置疑,但实际应用中免不了遇到某个功能需要输出独立的日志文件的情况,怎样才能把所需的内容从原有日志中分离,形成单独的日志文件呢?其实只要在现有的log4j基础上稍加配置即可轻松实 ...
- 求第N个回文数 模板
备忘. /*看到n可以取到2*10^9.说明普通方法一个个暴力计算肯定会超时的,那打表呢?打表我们要先写个打表的代码,这里不提供.打完表观察数据,我们会发现数据其实是有规律的.完全不需要暴力的把所有数 ...
- NYOJ 914 Yougth的最大化【二分/最大化平均值模板/01分数规划】
914-Yougth的最大化 内存限制:64MB 时间限制:1000ms 特判: No 通过数:3 提交数:4 难度:4 题目描述: Yougth现在有n个物品的重量和价值分别是Wi和Vi,你能帮他从 ...
- 2018 ACM-ICPC 沈阳网络赛
Problem A Problem B Problem C Problem D Problem E Problem F Problem G Problem H Problem I Problem J ...
- linux程序与进程内存结构
1.可执行文件结构: 1)代码区:包含操作码和操作对象.常量数据(const声明).立即数,代码区是共享的, 只提供只读. 2)全局/静态数据区:包含被初始化的全局数据和初始化静态数据. 3)未初始化 ...
- 对Array.prototype.slice.call()方法的理解在看别人代码时,发现有这么个写法:[].slice.call(arguments, 0),这到底是什么意思呢?
1.基础 1)slice() 方法可从已有的数组中返回选定的元素. start:必需.规定从何处开始选取.如果是负数,那么它规定从数组尾部开始算起的位置.也就是说,-1 指最后一个元素,-2 指倒数第 ...
- jvm-监视管理控制台-jconsole
命令: jconsole 作用: jvm进程运行状态的实时.可视化工具 效果: 连接远程jvm进程: 1.首先远程jvm进程,开启了jmx服务: -Dcom.sun.management.jmxrem ...
- linux-排序-sort
命令格式: sort [参数][源文件][-o 输出文件] 参数: -b 忽略每行前面开始出的空格字符. -c 检查文件是否已经按照顺序排序. -f 排序时,忽略大小写字母. -M ...
- java对象详解
java对象及线程详解 内存布局 普通对象布局 数组的内存布局 内部类的内存布局 对象分解 对象头-mark word(8字节) 实例数据 对齐填充(可选) java锁分析 volatile关键字 v ...
- 使用FluentValidation来进行数据有效性验证
之前我介绍过了使用系统自带的Data Annotations来进行数据有效性验证,今天在CodePlex上逛的时候,发现了一个非常简洁好用的库:FluentValidation 由于非常简洁,就直接拿 ...