Apache Beam的API设计
不多说,直接上干货!
Apache Beam的API设计
Apache Beam还在开发之中,后续对应的API设计可能会有所变化,不过从当前版本来看,基于对数据处理领域对象的抽象,API的设计风格大量使用泛型来定义,具有很高的抽象级别。下面我们分别对感兴趣的的设计来详细说明。
- Source
Source表示数据输入的抽象,在API定义上分成两大类:一类是面向数据批处理的,称为BoundedSource,它能够从输入的数据集读取有限的数据记录,知道数据具有有限性的特点,从而能够对输入数据进行切分,分成一定大小的分片,进而实现数据的并行处理;另一类是面向数据流处理的,称为UnboundedSource,它所表示的数据是连续不断地进行输入,从而能够实现支持流式数据所特有的一些操作,如Checkpointing、Watermarks等。
Source对应的类设计,如下类图所示:
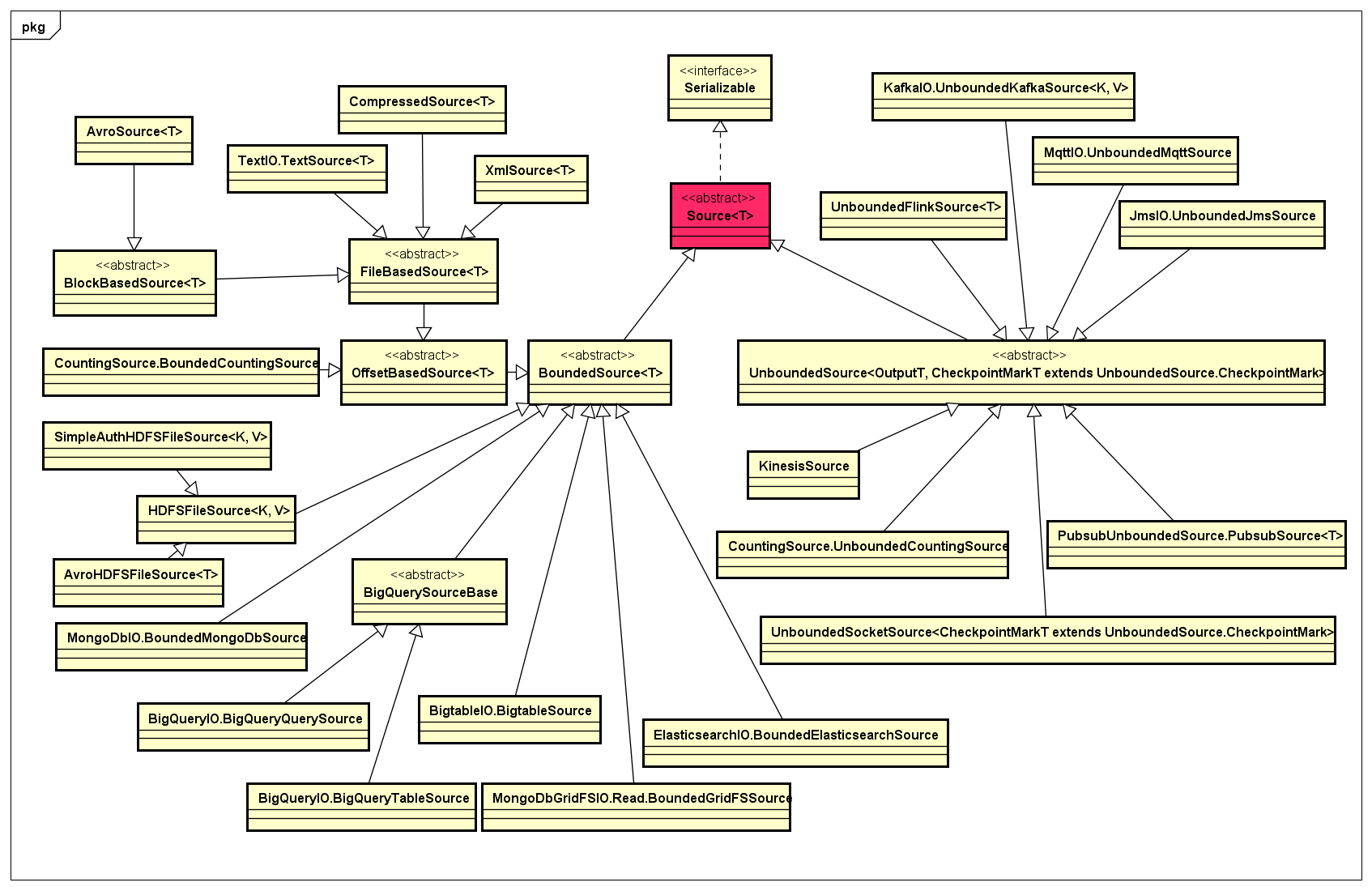
目前,Apache Beam支持BoundedSource的数据源主要有:HDFS、MongoDB、Elasticsearch、File等,支持UnboundedSource的数据源主要有:Kinesis、Pubsub、Socker等。未来,任何具有Bounded或Unbounded两类特性的数据源都可以在Apache Beam的抽象基础上实现对应的Source。
- Sink
Sink表示任何经过Pipeline中一个或多个PTransform处理过的PCollection,最终会输出到特定的存储中。与Source对应,其实Sink主要也是具有两种类型:一种是直接写入特定存储的Bounded类型,如文件系统;另一种是写入具有Unbounded特性的存储或系统中,如Flink。在API设计上,Sink的类图如下所示:

可见,基于Sink的抽象,可以实现任意可以写入的存储系统。
- PipelineRunner
下面,我们来看一下PipelineRunner的类设计以及目前开发中的PipelineRunner,如下图所示:
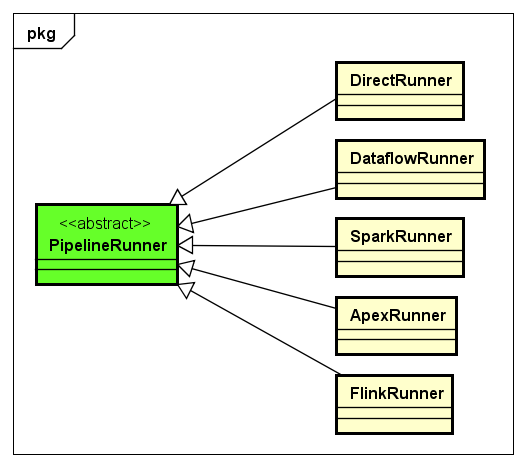
目前,PipelineRunner有DirectRunner、DataflowRunner、SparkRunner、ApexRunner、FlinkRunner,待这些主流的PipelineRunner稳定以后,如果有其他新的计算引擎框架出现,可以在PipelineRunner这一层进行扩展实现。
这些PipelineRunner中,DirectRunner是最简单的PipelineRunner,它非常有用,比如我们实现了一个从HDFS读取数据,但是需要在Spark集群上运行的ETL程序,使用DirectRunner可以在本地非常容易地调试ETL程序,调试到程序的数据处理逻辑没有问题了,再最终在实际的生产环境Spark集群上运行。如果特定的PipelineRunner所对应的计算引擎没有很好的支撑调试功能,使用DirectRunner是非常方便的。
- PCollection
PCollection是对分布式数据集的抽象,主要用作输入、输出、中间结果集。其中,在Apache Beam中对数据及其数据集的抽象有几类,我们画到一张类图上,如下图所示:
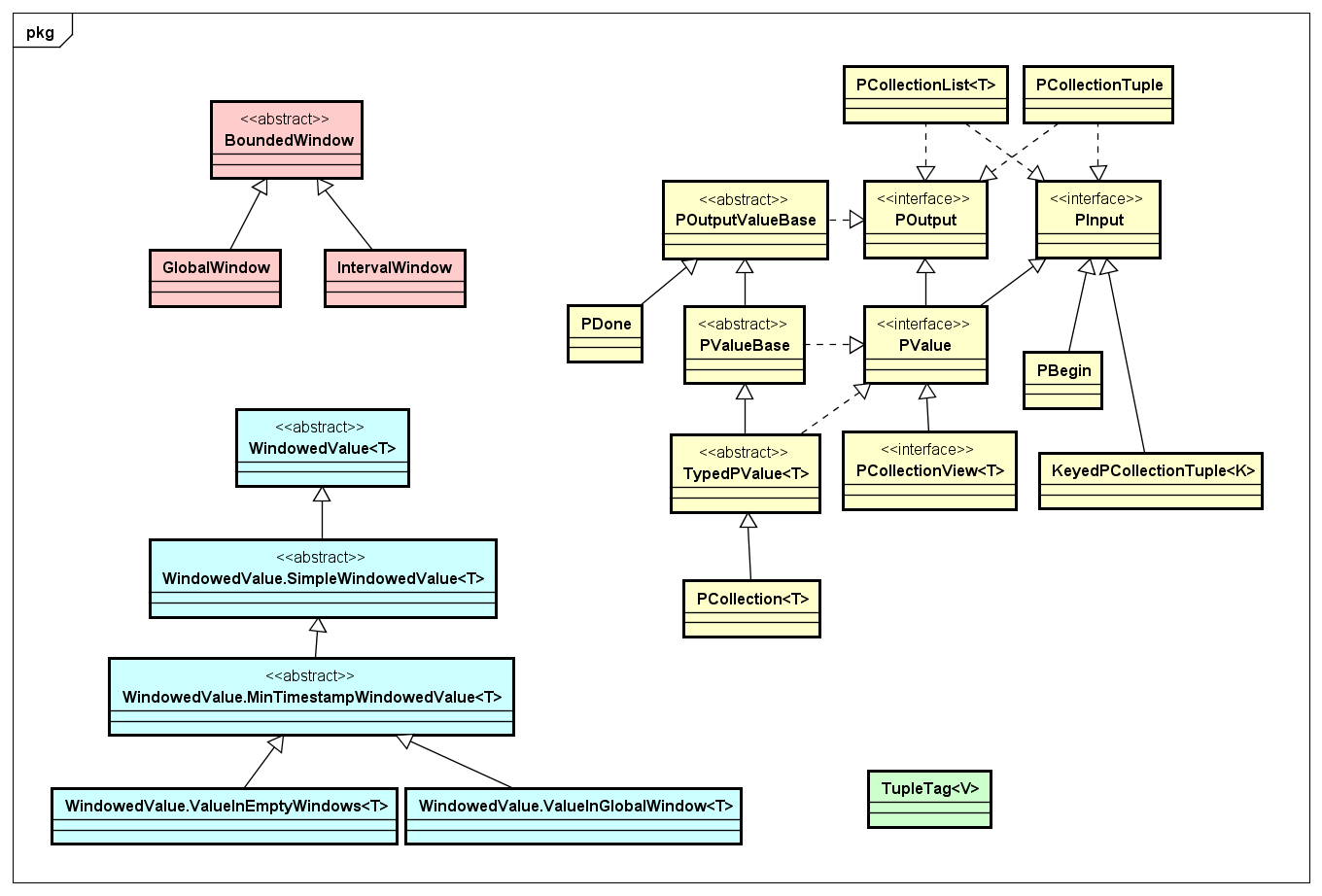
PCollection是对数据集的抽象,包括输入输出,而基于Window的数据处理有对应的Window相关的抽象,还有一类就是TupleTag,针对具有CoGroup操作的情况下用来标记对应数据中的Tuple数据,具体如何使用可以后面我们实现的Join的例子。
- PTransform
一个Pipeline是由一个或多个PTransform构建而成的DAG图,其中每一个PTransform都具有输入和输出,所以PTransform是Apache Beam中非常核心的组件,我按照PTransform的做了一下分类,如下类图所示:
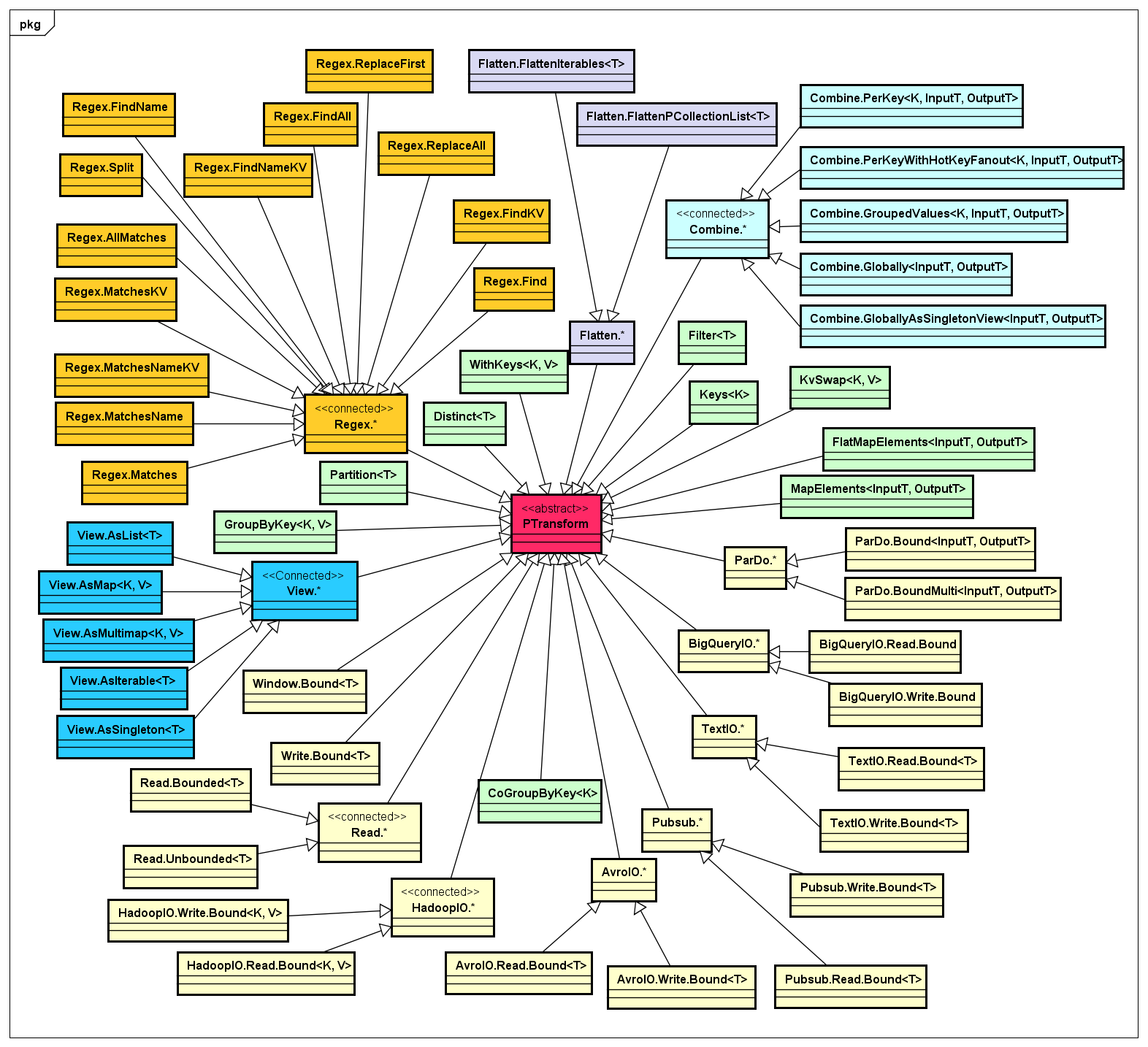
通过上图可以看出,PTransform针对不同输入或输出的数据的特征,实现了一个算子(Operator)的集合,而Apache Beam除了期望实现一些通用的PTransform实现来供数据处理的开发人员开箱即用,同时也在API的抽象级别上做的非常Open,如果你想实现自己的PTransform来处理指定数据集,只需要自定义即可。而且,随着社区的活跃及其在实际应用场景中推广和使用,会很快构建一个庞大的PTransform实现库,任何有数据处理需求的开发人员都可以共享这些组件。
- Combine
这里,单独把Combine这类合并数据集的实现拿出来,它的抽象很有趣,主要面向globally 和per-key这两类抽象,实现了一个非常丰富的PTransform算子库,对应的类图如下所示:
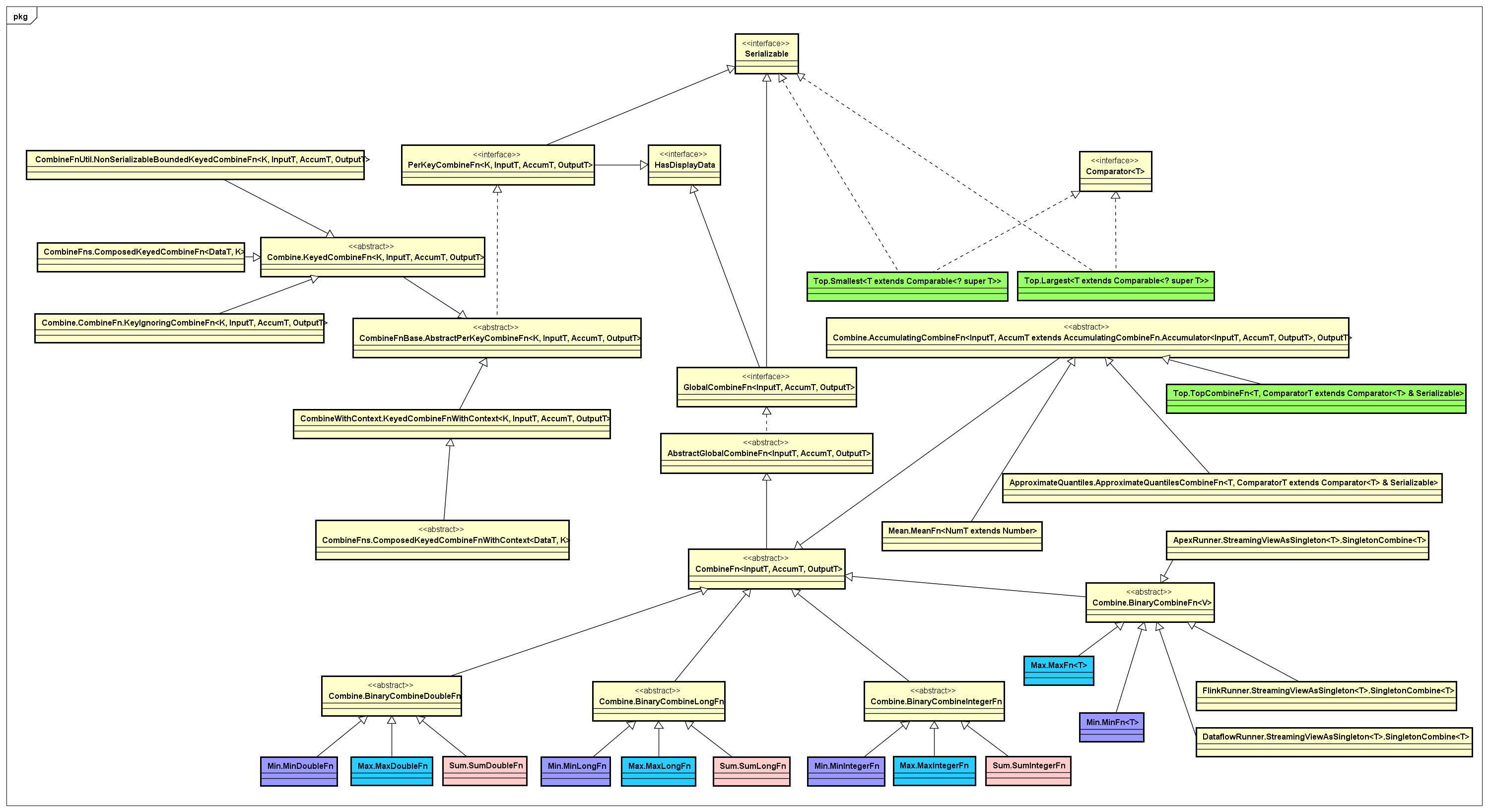
通过上图可以看出,作用在一个数据集上具有Combine特征的基本操作:Max、Min、Top、Mean、Sum、Count等等。
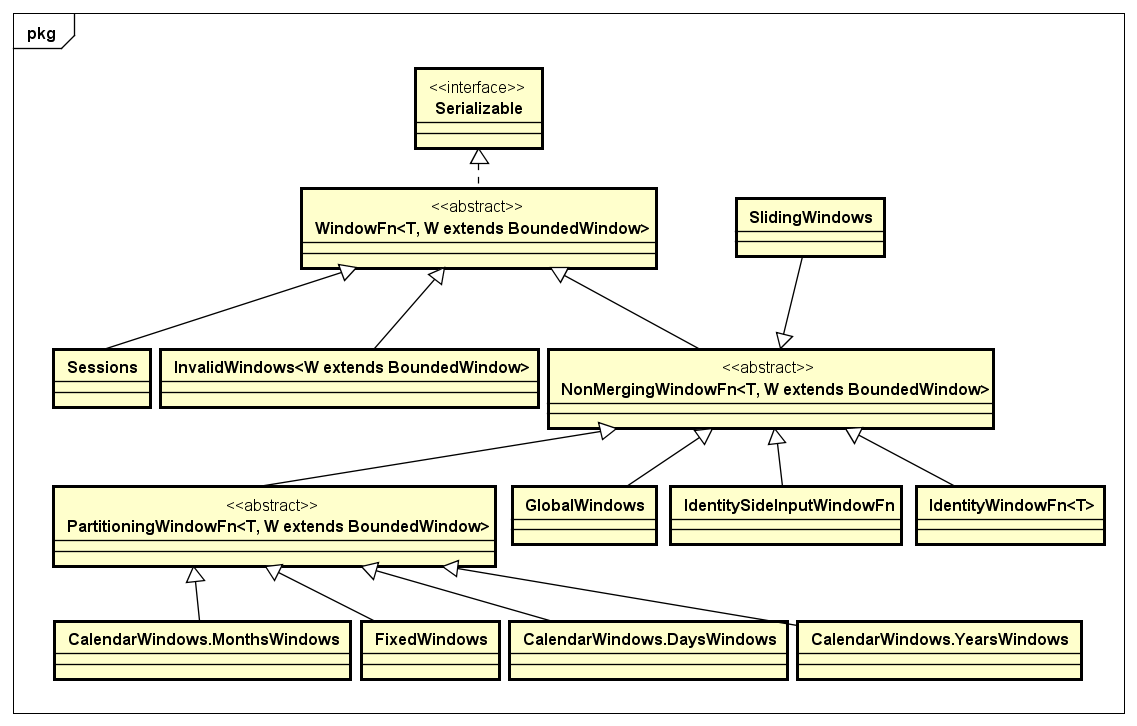
- Window
Window是用来处理某一个Micro batch的数据记录可以进行Merge这种场景的需求,通常用在Streaming处理的情况下。Apache Beam也提供了对Window的抽象,其中对于某一个Window下的数据的处理,是通过WindowFn接口来定义的,与该接口相关的处理类,如下类图所示:
Apache Beam的API设计的更多相关文章
- Apache Beam实战指南 | 大数据管道(pipeline)设计及实践
Apache Beam实战指南 | 大数据管道(pipeline)设计及实践 mp.weixin.qq.com 策划 & 审校 | Natalie作者 | 张海涛编辑 | LindaAI 前 ...
- Why Apache Beam? A data Artisans perspective
https://cloud.google.com/dataflow/blog/dataflow-beam-and-spark-comparison https://github.com/apache/ ...
- Apache Beam—透视Google统一流式计算的野心
Google是最早实践大数据的公司,目前大数据繁荣的生态很大一部分都要归功于Google最早的几篇论文,这几篇论文早就了以Hadoop为开端的整个开源大数据生态,但是很可惜的是Google内部的这些系 ...
- Apache Beam实战指南 | 手把手教你玩转KafkaIO与Flink
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247492538&idx=2&sn=9a2bd9fe2d7fd6 ...
- Apache Beam编程指南
术语 Apache Beam:谷歌开源的统一批处理和流处理的编程模型和SDK. Beam: Apache Beam开源工程的简写 Beam SDK: Beam开发工具包 **Beam Java SDK ...
- Apache Beam是什么?
Apache Beam 的前世今生 1月10日,Apache软件基金会宣布,Apache Beam成功孵化,成为该基金会的一个新的顶级项目,基于Apache V2许可证开源. 2003年,谷歌发布了著 ...
- Apache Beam: 下一代的大数据处理标准
Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后 ...
- Apache Beam的架构概览
不多说,直接上干货! Apache Beam是一个开源的数据处理编程库,由Google贡献给Apache的项目,前不久刚刚成为Apache TLP项目.它提供了一个高级的.统一的编程模型,允许我们通过 ...
- Apache Beam,批处理和流式处理的融合!
1. 概述 在本教程中,我们将介绍 Apache Beam 并探讨其基本概念. 我们将首先演示使用 Apache Beam 的用例和好处,然后介绍基本概念和术语.之后,我们将通过一个简单的例子来说明 ...
随机推荐
- 一步之遥——第七届蓝桥杯C语言B组(国赛)第一题
原创 一步之遥 从昏迷中醒来,小明发现自己被关在X星球的废矿车里.矿车停在平直的废弃的轨道上.他的面前是两个按钮,分别写着“F”和“B”. 小明突然记起来,这两个按钮可以控制矿车在轨道上前进和后退.按 ...
- 使用C#代码发送邮件,不完整的demo
作为一只入行不久的小菜鸟,最近接触到利用C#代码发送邮件,做了一点小的demo练习.首先,需要配置,这边我做的是QQ邮箱的相关的练习,练习之前,首先应该解决的问题肯定是关于服务器的配置,这边偷一个懒, ...
- 以太坊系列之四: 使用atomic来避免lock
使用atomic来避免lock 在程序中为了互斥,难免要用锁,有些时候可以通过使用atomic来避免锁, 从而更高效. 下面给出一个以太坊中的例子,就是MsgPipeRW,从名字Pipe可以看出, 他 ...
- 定时器timer类
timer类 Timer(定时器)是Thread的派生类,用于在指定时间后调用一个方法. 构造方法: Timer(interval, function, args=[], kwargs={}) in ...
- 命令行里打 cd 简直是浪费生命
简评:作为工程师,你在命令行下最常打的命令无非就是 cd 与 ls.这些年你浪费了多少时间? 作为一个程序员或者在 shell 中花费大量时间的人,你可能会经常以一种低效率的方式在目录中来回移动,特别 ...
- IK分词器原理与源码分析
原文:http://3dobe.com/archives/44/ 引言 做搜索技术的不可能不接触分词器.个人认为为什么搜索引擎无法被数据库所替代的原因主要有两点,一个是在数据量比较大的时候,搜索引擎的 ...
- 怎样将结构完全一样的两个表的内容合并到一个表中,SQL语句
标签: SQL合并数据 2013-08-21 10:41 489人阅读 评论(0) 收藏 举报 分类: Oracle数据库(14) select * into 新表名 from (select ...
- Android newsClient 小实例应用
1.newsClient新闻客户端涉及知识点汇总: (1)ListView(用来显示消息) (2)开子线程去服务器取数据 (3)解析xml文件 (4)利用handler或者runOnUiThread( ...
- Python web前端 07 函数及作用域
Python web前端 07 函数及作用域 一.函数 1.有名函数和匿名函数 #函数是由事件驱动的或者当它被调用时执行的可重复使用的代码块 #函数就是包裹在花括号里面的代码块,前面使用了关键字fun ...
- 洛谷 P3616 富金森林公园题解(树状数组)
P3616 富金森林公园 题目描述 博艾的富金森林公园里有一个长长的富金山脉,山脉是由一块块巨石并列构成的,编号从1到N.每一个巨石有一个海拔高度.而这个山脉又在一个盆地中,盆地里可能会积水,积水也有 ...