NLP-特征选择
文本分类之特征选择
1 研究背景
对于高纬度的分类问题,我们在分类之前一般会进行特征降维,特征降维的技术一般会有特征提取和特征选择。而对于文本分类问题,我们一般使用特征选择方法。
- 特征提取:PCA、线性判别分析
- 特征选择:文档频数、信息增益、期望交叉熵、互信息、文本证据权、卡方等
特征选择的目的一般是:
- 避免过拟合,提高分类准确度
- 通过降维,大大节省计算时间和空间
特征选择基本思想:
1)构造一个评价函数
2)对特征空间的每个特征进行评分
3)对所有的特征按照其评估分的大小进行排序
4)从中选取一定数目的分值最高的特征项
2 常用特征选择方法
|
c |
~c |
|
|
t |
A |
B |
|
~t |
C |
D |
2.1文档频率(Document Frequency,DF)
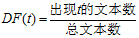
优点:实现简单,计算量小。
缺点:基于低频词不含分类信息或者只包含极少量分类信息,没有考虑类别信息,但实际并非如此。
2.2 互信息(Mutual Information, MI)
来自Claude Edwood Shannon的信息论,计算一个消息中两个信号之间的相互依赖程度。在文本分类中是计算特征词条与文本类的相互关联程度。
特征t在类别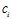 中MI公式:
中MI公式:
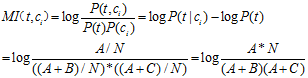
特征项t在整个样本中的互信息值:
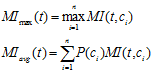
缺点:
对低频词十分敏感。若B为0时,无论A为多少算出来MI都一样,而且都很大。
2.3信息增益(Information Gain, IG)
来源于信息熵,公式:
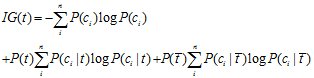
优点:信息增益考虑了特征未发生的情况,特征不出现的情况可能对文档类别具有贡献
缺点:对只出现在一类的低频词有一定程度的倚重,但这类低频词未必具有很好的分类信息。
2.4卡方检验(chi-square)
源于统计学的卡方分布(chi-square),从(类,词项)相关表出发,考虑每一个类和每一个词项的相关情况,度量两者(特征和类别)独立性的缺乏程度,卡方越大,独立性越小,相关性越大。
特征t在类别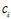 中的CHI公式:
中的CHI公式:
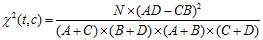
特征项t在整个样本中的卡方值:
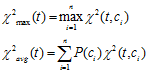
缺点:和IG一样,对低频词有一定程度的倚重。
3实验效果
任务:二元文本分类
数据集:
|
训练集 |
测试集 |
|
|
BCII |
5494篇文档(3536个正例,1959个负例) |
677篇文档(338个负例,339个负例) |
|
BCIII |
2280篇文档(1140个正例,1140个负例) |
6000篇文档(910个正例,5090个负例) |
实验方法:
- 文本预处理
- 特征选择:一元词特征
- 构建文本模型:BoW(布尔权值)
- 机器学习分类算法:SVM
- 评价指标:正类的F值
实验结果:
BCII结果
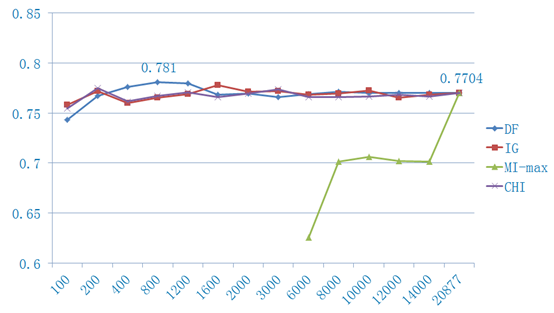
BCIII结果
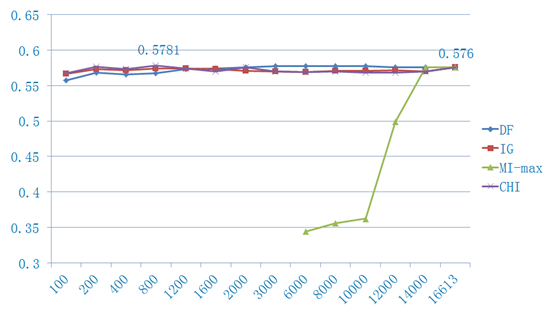 4 总结
4 总结
|
DF |
IG |
CHI |
MI |
|
|
倚重低频词 |
N |
Y |
Y |
Y |
|
考虑类别信息 |
N |
Y |
Y |
Y |
|
考虑特征不出现的情况 |
N |
Y |
Y |
N |
经验:
1)MI对于低频词过于敏感,对于特征出现频率差异较大的数据集,MI效果十分不理想。
2)DF的效果并没有想象中的差(除去停用词),和IG、CHI差不多,不过要是降到很低维的时候,一般还是IG和CHI的效果比较好。
3)若是数据集低频词数量比较多,DF效果甚至好于IG和CHI。
4)当数据集是均匀分布时,CHI的效果要略优于IG,而当数据集类别分布极为不均时,IG的效果要优于CHI。
5)不同的分类算法、评价指标等得到的效果可能会有所不同。
我们最好是根据自己的数据集分布,想达到的目的(降维?精确度?),来选择合适的特征选择方法。
参考文献:
[1] Y.Yang, J.Pedersen. A comparative study on feature selection in text categorization. 1997
[2] G. Foreman. An Extensive Empirical Study of Feature Selection Metrics for Text Classification. 2003
[3] 代六玲,黄河燕等. 中文文本分类中特征抽取方法的比较研究. 2004
NLP-特征选择的更多相关文章
- 【NLP】十分钟快览自然语言处理学习总结
十分钟学习自然语言处理概述 作者:白宁超 2016年9月23日00:24:12 摘要:近来自然语言处理行业发展朝气蓬勃,市场应用广泛.笔者学习以来写了不少文章,文章深度层次不一,今天因为某种需要,将文 ...
- NLP相关资源
一 NLP相关资源站点 Rouchester大学NLP/CL会议列表 一个非常好的会议时间信息网站,将自然语言处理和计算语言学领域的会议,按照时间月份顺序列出. NLPerJP 一个日本友好人士维护的 ...
- NLP系列(2)_用朴素贝叶斯进行文本分类(上)
作者:龙心尘 && 寒小阳 时间:2016年1月. 出处: http://blog.csdn.net/longxinchen_ml/article/details/50597149 h ...
- NLTK1及NLP理论基础
以下为Aron老师课程笔记 一.NLTK安装 1. 安装nltk https://pypi.python.org/pypi/nltk 把nltk-3.0.0解压到D:\Anacond3目录 打开cmd ...
- NLP知识十大结构
NLP知识十大结构 2.1形式语言与自动机 语言:按照一定规律构成的句子或者字符串的有限或者无限的集合. 描述语言的三种途径: 穷举法 文法(产生式系统)描述 自动机 自然语言不是人为设计而是自然进化 ...
- 利用Tensorflow进行自然语言处理(NLP)系列之一Word2Vec
同步笔者CSDN博客(https://blog.csdn.net/qq_37608890/article/details/81513882). 一.概述 本文将要讨论NLP的一个重要话题:Word2V ...
- 从NLP任务中文本向量的降维问题,引出LSH(Locality Sensitive Hash 局部敏感哈希)算法及其思想的讨论
1. 引言 - 近似近邻搜索被提出所在的时代背景和挑战 0x1:从NN(Neighbor Search)说起 ANN的前身技术是NN(Neighbor Search),简单地说,最近邻检索就是根据数据 ...
- 自然语言处理(NLP)知识结构总结
自然语言处理知识太庞大了,网上也都是一些零零散散的知识,比如单独讲某些模型,也没有来龙去脉,学习起来较为困难,于是我自己总结了一份知识体系结构,不足之处,欢迎指正.内容来源主要参考黄志洪老师的自然语言 ...
- NLP教程(4) - 句法分析与依存解析
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- 挑子学习笔记:特征选择——基于假设检验的Filter方法
转载请标明出处: http://www.cnblogs.com/tiaozistudy/p/hypothesis_testing_based_feature_selection.html Filter ...
随机推荐
- log4j分级别打印和如何配置多个Logger
log4j.rootLogger=dubug,info,warn,error 最关键的是log4j.appender.[level].threshold=[level] 这个是日志分级别打印的最关 ...
- 【BZOJ5056】OI游戏 最短路+有向图生成树计数
[BZOJ5056]OI游戏 Description 小Van的CP最喜欢玩与OI有关的游戏啦~小Van为了讨好她,于是冥思苦想,终于创造了一个新游戏. 下面是小Van的OI游戏规则: 给定一个无向连 ...
- Grafana---graph
主面板简单的命名为Graph.它提供了一组非常丰富的图形选项. 单击面板的标题将显示一个菜单.edit选项为面板打开了额外的配置选项. 一.General general允许定制面板的外观和菜单选项. ...
- JDBC请求
做JDBC请求,首先需要两个jar包:mysql驱动-mysql-connector-java-5.1.13-bin.jar 和 sqlServer驱动-sqljdbc4.jar,将这两个jar包放到 ...
- 修改mysql root的密码
use mysql:update user set Password = Password('newPwd') where user='root';//更改root用户的密码flush privile ...
- Slyce,这家硅谷创业公司的来头你知道吗
Slyce,也许你没听过,一家硅谷创业公司,旨在帮助运动员和其他社会名流组织.优化社交媒体,过滤粉丝的声音,让明星更好的在社交媒体上和他们互动.但是如果如果说库里,那你应该就知道了,拿到了上届NBA总 ...
- bootstrap模板
一.bootstrap基本介绍 1.什么是bootstrap? bootstrap就是个前端快速开发的工具,该工具是个简单.直观.强悍的前端开发框架,让web开发更加迅速简单,同时也是个响应式布局,兼 ...
- 剑指offer 面试4题
面试4题: 题目:在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数. 解题代码一:二 ...
- C语言预处理命令的使用
cppreference.com -> 预处理命令 -> 详细说明 预处理命令 #,## # 和 ## 操作符是和#define宏使用的. 使用# 使在#后的首个参数返回为一个带引号的字符 ...
- 【转】ModelAndView 学习
http://blog.csdn.net/wavaya/article/details/6185226 ModelAndView 类别就如其名称所示,是代表了Spring Web MVC程式中呈现画面 ...