在linux服务器上配置anaconda和Tensorflow,并运行
1. 查看服务器上的Python安装路径:
whereis python
2. 查看安装的Python版本号:
python -V
3. 安装Anaconda:
1)下载 Anaconda2-4.0.0-Linux-x86_64.sh安装文件;
直接在官网下载挺慢的,建议使用清华镜像(可以把pip的源也换成国内的,pip install也会快很多):https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
在最近的日期中,选择一个对应自己系统版本的Anaconda3安装包,x86_64表示兼容32位和64位系统。右键复制链接,在linux中使用wget下载。
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2019.03-Linux-x86_64.sh
如果提示没有wget,使用yum安装:
yum -y install wget
2)打开终端, 输入:
bash Anaconda3-2019.03-Linux-x86_64.sh
- 阅读license,一步步回车阅读(出现more时通过回车往下看)
- 输入yes,表示接受license
- 设置安装路径,这里使用默认安装路径,直接输入回车即可
- 确认是否将Anaconda的安装路径添加到环境变量中,输入yes

关于这里一定要注意:
如果在安装过程中,该步没有选择yes,那么Anaconda的安装路径不会被添加到环境变量中,安装结束后会出现如下信息:
Do you wish the installer to prepend the Anaconda2 install location
to PATH in your /home/tingting/.bashrc ? [yes|no]
[no] >>>
You may wish to edit your .bashrc or prepend the Anaconda2 install location:
$ export PATH=/home/tingting/anaconda2/bin:$PATH
Thank you for installing Anaconda2!
当时也没有注意这个信息,没有管,结果安装完anaconda后,发现根本不能使用,才注意到这条信息,原来,Anaconda的bin路径并没有被添加到PAHT环境变量中,所以需要在命令行中输入如下命令:
export PATH=/home/hwy/anaconda2/bin:$PATH

将anaconda的bin路径添加到环境变量PATH中。
对于环境变量的更改,必须要新打开一个terminal才能生效!
打开新的terminal,输入Jupyter notebook,发现jupyter被成功安装了。
source activate # 进入conda环境 出现(base)则说明安装成功
source deactivate # 退出conda环境
4. 利用anaconda安装tensorflow
1 建立一个 conda 计算环境
Create a conda environment called tensorflow:
conda create -n tensorflow python=3.7

2. 激活环境,使用 conda 安装 TensorFlow
Activate the environment and use pip to install TensorFlow inside it.
source activate tensorflow

- 安装不同版本的python:默认安装最新版本
对于GPU版本:
conda create --name tensorflow-gpu python=3.6
对于CPU版本:
conda create --name tensorflow python=3.6
- 指定安装tensorflow版本:
pip install tensorflow-gpu==1.4.
- 退出tensorflow环境
conda deactivate

3. 如何在jupyter中使用tensorflow
(1) 出现了问题
安装如上方法安装了jupyter和tensorflow,结果,利用jupyter无法使用tensorflow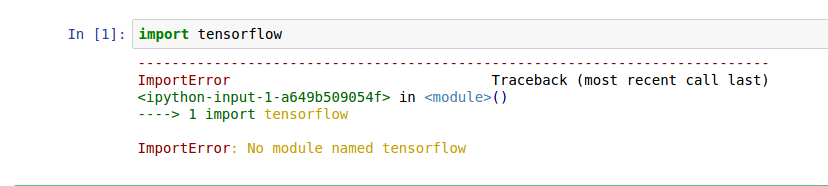
也没有查到特别有针对性的解决这个问题的资料,好像是因为jupyter的安装路径和tensorflow的路径之间的问题,具体的现在还不是很清楚
(2)如何解决?
应该是在conda的tensorflow环境下没有jupyter,它无法使用之前anaconda安装的jupyter,那么,简单粗暴的方法就是在当前的conda-tensorflow环境下,再安装一次jupyter:打开terminal
激活conda tensorflow环境:source activate tensorflow
安装notebook:conda install ipython
安装jupyter:conda install jupyter
安装完成,仍在conda tensorflow的环境下,输入jupyter notebook,打开http://localhost:8889/tree#
import tensorflow,发现tensorflow可以使用了参考:http://stackoverflow.com/questions/35771285/using-tensorflow-through-jupyter-python-3
(3)两个jupyter
在正常的ternimal中打开的是之前在安装anacodna时安装的jupyter,在正常的terminal下 查看jupyter的安装路径
which ipyhon
它在anaconda的路径下的bin文件夹中
在conda tensorflow环境下打开的jupyter是在conda tensorflow环境下新安装的tensorflow,与上面的jupyter不同
它在conda的env下的tensorflow的bin文件夹下
从下图可以想起地看到,两个jupyter的安装路径完成不同
后续如果需要在使用tensorflow时使用其他的库,也一定要在对应的conda环境下安装,否则指定的库找不到。
(4) 缺少模块及安装
- ImportError: no module named Image, ImportError: no module named PIL
解决:conda install pillow- 运行Tensorflow环境下的jupyter notebook:

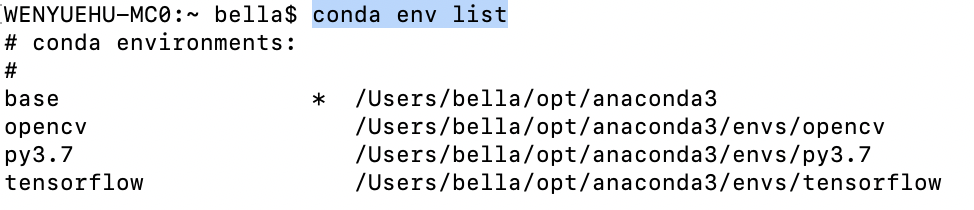
查看当前有多少个环境:
conda env list
在linux服务器上配置anaconda和Tensorflow,并运行的更多相关文章
- 在Linux服务器上配置phpMyAdmin
使用php和mysql开发网站的话,phpmyadmin是一个非常友好的mysql管理工具,并且免费开源,国内很多虚拟主机都自带这样的管理工具,配置很简单,接下来在linux服务器上配置phpmyad ...
- 本地Linux服务器上配置Git
当我们需要拉取远程服务器代码到本地服务器时,我们首先要确定已经配置了正确的Git账号,可以从~/.gitconfig文件(为隐藏文件,需要使用ls -a查看),以及~/.ssh下的id_rsa.pub ...
- linux服务器上配置多个svn仓库
linux服务器上配置多个svn仓库 1.在指定目录建立仓库保存总目录,本文示例目录设定为:/usr/local/svn/svnrepos # mkdir -p /usr/local/svn/svnr ...
- linux服务器上配置进行kaggle比赛的深度学习tensorflow keras环境详细教程
本文首发于个人博客https://kezunlin.me/post/6b505d27/,欢迎阅读最新内容! full guide tutorial to install and configure d ...
- 在Linux服务器上配置Transmission来离线下载BT种子
Transmission简介 Transmission是一种BitTorrent客户端,特点是跨平台的后端和简洁的用户界面,硬件资源消耗极少,支持包括Linux.BSD.Solaris.Mac OS ...
- Linux服务器上配置2个Tomcat或者多个Tomcat
一.当在一个服务器上面安装2个tomcat的时候,修改第二个tomcat的conf目录下server.xml文件里面的端口号(原8080改成8081,原8005改成8006)可以达到两个tomcat都 ...
- [亲测]ASP.NET Core 2.0怎么发布/部署到Ubuntu Linux服务器并配置Nginx反向代理实现域名访问
前言 ASP.NET Core 2.0 怎么发布到Ubuntu服务器?又如何在服务器上配置使用ASP.NET Core网站绑定到指定的域名,让外网用户可以访问呢? 步骤 第1步:准备工作 一台Liun ...
- [亲测]七步学会ASP.NET Core 2.0怎么发布/部署到Ubuntu Linux服务器并配置Nginx反向代理实现域名访问
前言 ASP.NET Core 2.0 怎么发布到Ubuntu服务器?又如何在服务器上配置使用ASP.NET Core网站绑定到指定的域名,让外网用户可以访问呢? 步骤 第1步:准备工作 一台Liun ...
- 【深度学习】在linux和windows下anaconda+pycharm+tensorflow+cuda的配置
在linux和windows下anaconda+pycharm+tensorflow+cuda的配置 在linux和windows下anaconda+pycharm+tensorflow+cuda的配 ...
随机推荐
- spring 框架jdbc连接数据库
user=LF password=LF url=jdbc:oracle:thin:@localhost:1521:orcl driver=oracle.jdbc.driver.OracleDriver ...
- 项目二:品优购 第二天 AngularJS使用 brand商品页面的增删改查
品优购电商系统开发 第2章 品牌管理 传智播客.黑马程序员 1.前端框架AngularJS入门 1.1 AngularJS简介 AngularJS 诞生于2009年,由Misko Hevery 等人 ...
- Django cache
Django中使用redis 方式一: utils文件夹下,建立redis_pool.py import redis POOL = redis.ConnectionPool(host='127.0.0 ...
- URAL 1355. Bald Spot Revisited(数论)
题目链接 题意 : 一个学生梦到自己在一条有很多酒吧的街上散步.他可以在每个酒吧喝一杯酒.所有的酒吧有一个正整数编号,这个人可以从n号酒吧走到编号能整除n的酒吧.现在他要从a号酒吧走到b号,请问最多能 ...
- ASP.NET多页面传递数据,附框架源码
很多时候我们需要把数据传递到多个页面,比如表单提交可以指定提交数据到某个页面,那么关闭某个页面怎么把数据传递到上一个页面或者它的父页面. 在这里我附一段源码用于当前页面关闭指定某个页面刷新. 子页面方 ...
- TensorFlow安装教程
Windows7 安装TensorFlow(本人试了好多方法后的成果):https://www.cnblogs.com/bxyan/p/6869237.html Linux: sudo pip ins ...
- 编写高质量代码改善C#程序的157个建议——建议54:为无用字段标注不可序列化
建议54:为无用字段标注不可序列化 序列化是指这样一种技术:把对象转变成流.相反过程,我们称为反序列化.在很多场合都需要用到这项技术. 把对象保存到本地,在下次运行程序的时候,恢复这个对象. 把对象传 ...
- SQLServer 附加数据库后只读或报错解决方法
百度文库地址 http://wenku.baidu.com/link?url=3EnK52mOtll3svjce0OGUUu7h9EOWkUgty8VChkxRdX7LQlm9Ll6N_78ENngN ...
- Boost 安装详解
一 Linux(redhat)篇 1.1 获取boost库 解压tar -zxvf boost_1.48.0.tar.gz 进入解压目录cd boost_1_48_0 1.2 编译安装 使用下面的命令 ...
- 课后练习Javascript
<script type="text/javascript"> alert (isNaN(prompt("输入个数字进来","只能输入数字 ...