Python 手写数字识别-knn算法应用
在上一篇博文中,我们对KNN算法思想及流程有了初步的了解,KNN是采用测量不同特征值之间的距离方法进行分类,也就是说对于每个样本数据,需要和训练集中的所有数据进行欧氏距离计算。这里简述KNN算法的特点:
优点:精度高,对异常值不敏感,无数据输入假定
缺点:计算复杂度高,空间复杂度高
适用数据范围:数值型和标称型(具有有穷多个不同值,值之间无序)
knn算法代码:
#-*- coding: utf-8 -*-
from numpy import *
import operator
import time
from os import listdir
def classify(inputPoint,dataSet,labels,k):
dataSetSize = dataSet.shape[0] #已知分类的数据集(训练集)的行数
#先tile函数将输入点拓展成与训练集相同维数的矩阵,再计算欧氏距离
diffMat = tile(inputPoint,(dataSetSize,1))-dataSet #样本与训练集的差值矩阵
sqDiffMat = diffMat ** 2 #差值矩阵平方
sqDistances = sqDiffMat.sum(axis=1) #计算每一行上元素的和
distances = sqDistances ** 0.5 #开方得到欧拉距离矩阵
sortedDistIndicies = distances.argsort() #按distances中元素进行升序排序后得到的对应下标的列表
#选择距离最小的k个点
classCount = {}
for i in range(k):
voteIlabel = labels[ sortedDistIndicies[i] ]
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
#按classCount字典的第2个元素(即类别出现的次数)从大到小排序
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]
下面介绍如何使用knn算法对手写识别数据进行分类,这里构造的分类系统只能识别数字0到9,数字经图形处理软件处理成具有相同的色彩和大小,宽高为32x32像素,为了便于处理,已将图像转换为文本格式,其效果图如下:

数据集可在这里下载,解压后有两个目录,其中目录trainingDigits中包含了1934个例子,命名规则如 9_45.txt,表示该文件的分类是9,是数字9的第45个实例,每个数字大概有200个实例。testDigits目录中包含946个例子。使用trainingDigits中的数据作为训练集,使用testDigits中的数据作为测试集测试分类的效果。两组数据没有重叠。
算法应用步骤如下:
1. 数据准备:数字图像文本向量化,这里将32x32的二进制图像文本矩阵转换成1x1024的向量。循环读出文件的前32行,存储在向量中。
#文本向量化 32x32 -> 1x1024
def img2vector(filename):
returnVect = []
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect.append(int(lineStr[j]))
return returnVect
2. 构建训练数据集:利用目录trainingDigits中的文本数据构建训练集向量,以及对应的分类向量
#从文件名中解析分类数字
def classnumCut(fileName):
fileStr = fileName.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
return classNumStr
#构建训练集数据向量,及对应分类标签向量
def trainingDataSet():
hwLabels = []
trainingFileList = listdir('trainingDigits') #获取目录内容
m = len(trainingFileList)
trainingMat = zeros((m,1024)) #m维向量的训练集
for i in range(m):
fileNameStr = trainingFileList[i]
hwLabels.append(classnumCut(fileNameStr))
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
return hwLabels,trainingMat
3. 测试集数据测试:通过测试testDigits目录下的样本,来计算算法的准确率。
#测试函数
def handwritingTest():
hwLabels,trainingMat = trainingDataSet() #构建训练集
testFileList = listdir('testDigits') #获取测试集
errorCount = 0.0 #错误数
mTest = len(testFileList) #测试集总样本数
t1 = time.time()
for i in range(mTest):
fileNameStr = testFileList[i]
classNumStr = classnumCut(fileNameStr)
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
#调用knn算法进行测试
classifierResult = classify(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of tests is: %d" % mTest #输出测试总样本数
print "the total number of errors is: %d" % errorCount #输出测试错误样本数
print "the total error rate is: %f" % (errorCount/float(mTest)) #输出错误率
t2 = time.time()
print "Cost time: %.2fmin, %.4fs."%((t2-t1)//60,(t2-t1)%60) #测试耗时 if __name__ == "__main__":
handwritingTest()
运行结果如下:
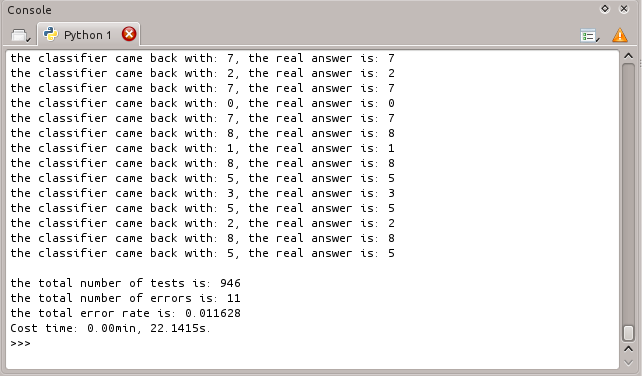
利用knn算法识别手写数字数据集,错误率为1.6%,算法的准确率还算可观。也可以通过改变变量k的值,观察错误率的变化,关于k值的选择,一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。
通过运行以上代码,我们会发现knn算法的执行效率并不高,因为算法需要为每个测试向量计算约2000次欧氏距离,每个距离计算包括1024个维度浮点运算,全部样本要执行900多次,可见算法实际耗时长,另外,knn算法必须保存全部数据集,每次需为测试向量准备2MB的存储空间(2个1024x1024矩阵的空间)。所以如何优化算法,减少存储空间和计算时间的开销,需要我们进一步深入学习。
参考资料:
《机器学习实战》
Python 手写数字识别-knn算法应用的更多相关文章
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- 基于OpenCV的KNN算法实现手写数字识别
基于OpenCV的KNN算法实现手写数字识别 一.数据预处理 # 导入所需模块 import cv2 import numpy as np import matplotlib.pyplot as pl ...
- Kaggle竞赛丨入门手写数字识别之KNN、CNN、降维
引言 这段时间来,看了西瓜书.蓝皮书,各种机器学习算法都有所了解,但在实践方面却缺乏相应的锻炼.于是我决定通过Kaggle这个平台来提升一下自己的应用能力,培养自己的数据分析能力. 我个人的计划是先从 ...
- 机器学习(二)-kNN手写数字识别
一.kNN算法是机器学习的入门算法,其中不涉及训练,主要思想是计算待测点和参照点的距离,选取距离较近的参照点的类别作为待测点的的类别. 1,距离可以是欧式距离,夹角余弦距离等等. 2,k值不能选择太大 ...
- 手写数字识别 ----卷积神经网络模型官方案例注释(基于Tensorflow,Python)
# 手写数字识别 ----卷积神经网络模型 import os import tensorflow as tf #部分注释来源于 # http://www.cnblogs.com/rgvb178/p/ ...
- 手写数字识别 ----Softmax回归模型官方案例注释(基于Tensorflow,Python)
# 手写数字识别 ----Softmax回归模型 # regression import os import tensorflow as tf from tensorflow.examples.tut ...
- [Python]基于CNN的MNIST手写数字识别
目录 一.背景介绍 1.1 卷积神经网络 1.2 深度学习框架 1.3 MNIST 数据集 二.方法和原理 2.1 部署网络模型 (1)权重初始化 (2)卷积和池化 (3)搭建卷积层1 (4)搭建卷积 ...
- kaggle 实战 (1): PCA + KNN 手写数字识别
文章目录 加载package read data PCA 降维探索 选择50维度, 拆分数据为训练集,测试机 KNN PCA降维和K值筛选 分析k & 维度 vs 精度 预测 生成提交文件 本 ...
- C#中调用Matlab人工神经网络算法实现手写数字识别
手写数字识别实现 设计技术参数:通过由数字构成的图像,自动实现几个不同数字的识别,设计识别方法,有较高的识别率 关键字:二值化 投影 矩阵 目标定位 Matlab 手写数字图像识别简介: 手写 ...
随机推荐
- MAC地址泛洪攻击测试
测试环境:kali系统(2个kali分别作攻击人和目标用户) win7系统(主机) 1.步配置FTP设置用户名密码 2.在攻击kali端测试网络的连通性 3.测试tpf是否正常 开始泛洪 4.开始抓包 ...
- BW常用事务码Tcode
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- cubic-bezier贝塞尔曲线css3动画工具
今天在一本叫<HTML5触摸界面设计与开发>上看到一个做弹跳球的复杂动画效果,首先加速下降,停止,然后弹起时逐渐减速.是用cubic-bezier贝塞尔曲线来完成的.所以特地去学习了一下关 ...
- eclipse 条件断点的使用
在某些特殊情况下,我们可能需要远程debug服务器进行问题追踪排查.比如在系统日志不够完善,没法定位问题的情况下需要远程debug进行排查. 但是服务器处于并发调用状态,怎样才能不影响其他业务系统调用 ...
- 新建web工程Jdk怎么不是自己安装的, 是自带的
需要在eclipse中配置默认的jdk环境的,不要用它默认的那个,这个不能用的http://blog.csdn.net/clj198606061111/article/details/11881575 ...
- oracle连接本地数据库
连接方式: 通过SQL Developer进行连接: 通过sql plus 进行连接: SQL Developer进行连接1.安装Oracle 11g会自带一个叫做SQL Developer的工具,它 ...
- [分享] WIN7x64封装体积小于4G制作过程
raymond 发表于 2015-11-1 18:27:17 https://www.itsk.com/thread-359041-1-1.html 前人栽树,后人乘凉!感谢各位大神的作品!我只是按部 ...
- JS历史
JavaScript伴随着互联网的发展一起发展.互联网周边技术的快速发展,刺激和推动了JavaScript语言的发展. 2006年,jQuery函数库诞生,作者为John Resig.jQuery为操 ...
- 【转】关于 Web GIS
以下部分选自2015-03-01出版的<Web GIS从基础到开发实践(基于ArcGIS API for JavaScript)>一书中的前言部分: Web GIS 概念于1994 年首次 ...
- PostgreSQL的时间/日期函数使用 转
http://www.cnblogs.com/mchina/archive/2013/04/15/3010418.html