完全分布式部署Hadoop
完全分布式部署 Hadoop
分析:
1)准备 3 台客户机(关闭防火墙、静态 ip、主机名称)
2)安装 jdk
3)配置环境变量
4)安装 hadoop
5)配置环境变量
6)安装 ssh
7)配置集群
8)启动测试集群
scp
1)scp 可以实现服务器与服务器之间的数据拷贝。
2)案例实操
(1)将 hadoop101 中/opt/module 和/opt/software 文件拷贝到 hadoop102、hadoop103 和
hadoop104 上。
[root@hadoop101 /]# scp -r /opt/module/ root@hadoop102:/opt
[root@hadoop101 /]# scp -r /opt/software/ root@hadoop102:/opt
[root@hadoop101 /]# scp -r /opt/module/ root@hadoop103:/opt
[root@hadoop101 /]# scp -r /opt/software/ root@hadoop103:/opt
[root@hadoop101 /]# scp -r /opt/module/ root@hadoop104:/opt
[root@hadoop101 /]# scp -r /opt/software/ root@hadoop105:/opt
(2)将 hadoop101 服务器上的/etc/profile 文件拷贝到 hadoop102 上。
[root@hadoop102 opt]# scp root@hadoop101:/etc/profile /etc/profile
(3)实现两台远程机器之间的文件传输(hadoop103 主机文件拷贝到 hadoop104 主机上)
[atguigu@hadoop102 test]$ scp atguigu@hadoop103:/opt/test/haha
atguigu@hadoop104:/opt/test/
SSH 无密码登录 (配置集群必备)
1)配置 ssh
(1)基本语法
ssh 另一台电脑的 ip 地址
(2)ssh 连接时出现 Host key verification failed 的解决方法
[root@hadoop102 opt]# ssh 192.168.1.103
The authenticity of host '192.168.1.103 (192.168.1.103)' can't be established.
RSA key fingerprint is cf:1e:de:d7:d0:4c:2d:98:60:b4:fd:ae:b1:2d:ad:06.
Are you sure you want to continue connecting (yes/no)?
Host key verification failed.
(3)解决方案如下:直接输入 yes
2)无密钥配置
(1)进入到我的 home 目录
[atguigu@hadoop102 opt]$ cd ~/.ssh
(2)生成公钥和私钥:
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
3).ssh 文件夹下的文件功能解释
(1)~/.ssh/known_hosts :记录 ssh 访问过计算机的公钥(public key)
(2)id_rsa :生成的私钥
(3)id_rsa.pub :生成的公钥
(4)authorized_keys :存放授权过得无秘登录服务器公钥
rsync
rsync 远程同步工具,主要用于备份和镜像。具有速度快、避免复制相同内容和支持符
号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更
新。scp 是把所有文件都复制过去。
(1)查看 rsync 使用说明
man rsync | more
(2)基本语法
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
命令 命令参数 要拷贝的文件路径/名称 目的用户@主机:目的路径
选项
-r 递归
-v 显示复制过程
-l 拷贝符号连接
编写集群分发脚本 xsync
1)需求分析:循环复制文件到所有节点的相同目录下。
(1)原始拷贝:
rsync -rvl /opt/module root@hadoop103:/opt/
(2)期望脚本:
xsync 要同步的文件名称
(3)在/usr/local/bin 这个目录下存放的脚本,可以在系统任何地方直接执行。
2)案例实操:
(1)在/usr/local/bin 目录下创建 xsync 文件,文件内容如下:
[root@hadoop102 bin]# touch xsync
[root@hadoop102 bin]# vi xsync
|
#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1);pwd` echo pdir=$pdir user=`whoami` #5 循环 for((host=103; host<105; host++)); do #echo $pdir/$fname $user@hadoop$host:$pdir echo --------------- hadoop$host ---------------- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done |
(2)修改脚本 xsync 具有执行权限
[root@hadoop102 bin]# chmod 777 xsync
[root@hadoop102 bin]# chown atguigu:atguigu -R xsync
配置集群
1)集群部署规划 hadoop102 hadoop103 hadoop104
| hadooop102 | hadoop103 | hadoop104 | |
| HDFS |
NameNode DataNode |
DataNode |
SacondaryNameNode DataNode |
| YARN | Nodemanager |
ResourceManager NodeManager |
Nodemanager |
2)配置文件
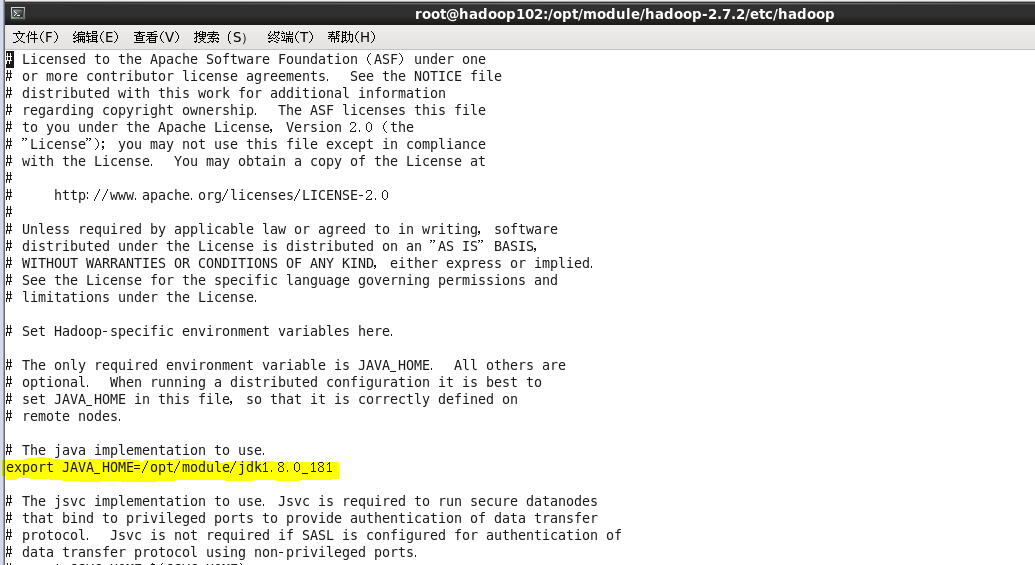
1---------vi hadoop-env.sh
export JAVA_HOME=/hadoop/jdk1.7.0_75/
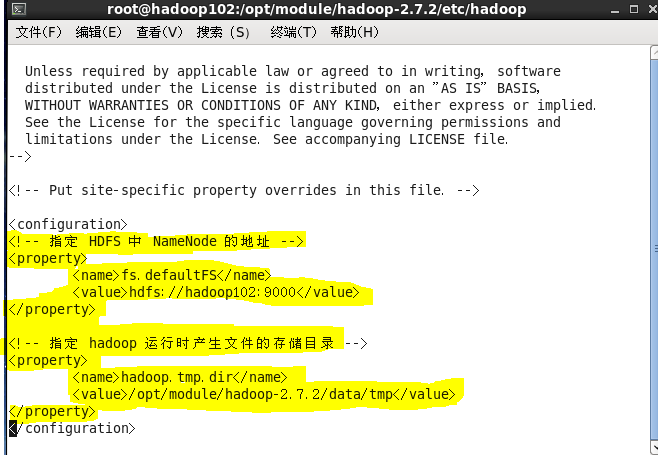
2---------vi core-site.xml
<configuration>
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
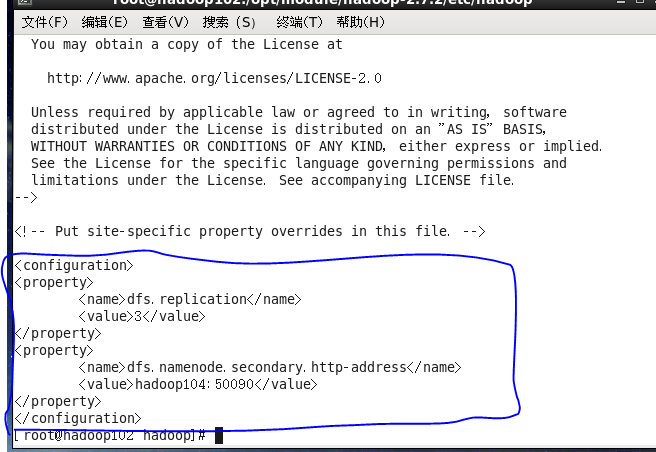
3------------vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
</configuration>
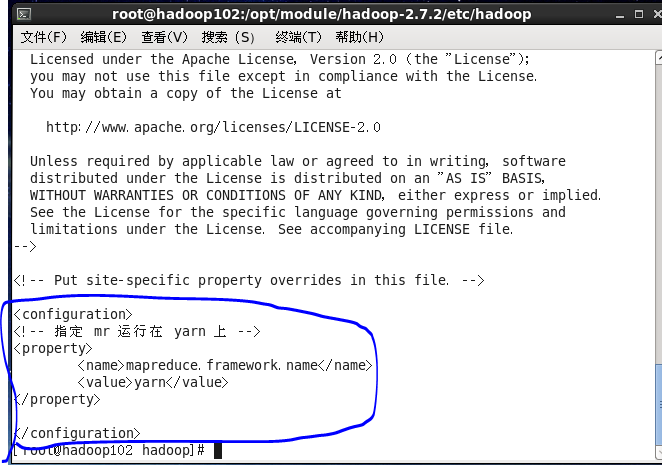
4:在这里是没有mapred-site.xm 的。需要先 mv mapred-site.xml.template mapred-site.xml 修改一下
----------vi mapred-site.xml
<!-- 指定 mr 运行在 yarn 上 -->
<configuration>
<!-- 指定 mr 运行在 yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5-----------vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
</configuration>

.启动集群:
1.初始化HDFS:hadoop namenode -format
2.启动HDFS:sbin/目录下 sh start-dfs.sh
3.启动YARN:sbin/目录下 sh start-yarn.sh
验证:
1.jps:查看服务启动
2、http://mini111:50070
3、http://moni111:8088
十.测试:
1.上传文件到HDFS:hadoop fs -mkdir -p /wordcount/input hadoop fs -put /hadoop/words.txt /wordcount/input
完全分布式部署Hadoop的更多相关文章
- Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)
系统:Centos 7,内核版本3.10 本文介绍如何从0利用Docker搭建Hadoop环境,制作的镜像文件已经分享,也可以直接使用制作好的镜像文件. 一.宿主机准备工作 0.宿主机(Centos7 ...
- Hadoop 完全分布式部署
完全分布式部署Hadoop 分析: 1)准备3台客户机(关闭防火墙.静态ip.主机名称) 2)安装jdk 3)配置环境变量 4)安装hadoop 5)配置环境变量 6)安装ssh 7)集群时间同步 7 ...
- Hadoop1 Centos伪分布式部署
前言: 毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了.对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环 ...
- Hadoop 2.6.0分布式部署參考手冊
Hadoop 2.6.0分布式部署參考手冊 关于本參考手冊的word文档.能够到例如以下地址下载:http://download.csdn.net/detail/u012875880/8291493 ...
- Apache Hadoop 2.9.2 完全分布式部署
Apache Hadoop 2.9.2 完全分布式部署(HDFS) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.环境准备 1>.操作平台 [root@node101.y ...
- Hadoop生态圈-zookeeper完全分布式部署
Hadoop生态圈-zookeeper完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客部署是建立在Hadoop高可用基础之上的,关于Hadoop高可用部署请参 ...
- Hadoop生态圈-Kafka的完全分布式部署
Hadoop生态圈-Kafka的完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要内容就是搭建Kafka完全分布式,它是在kafka本地模式(https:/ ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- Hadoop生态圈-phoenix完全分布式部署以及常用命令介绍
Hadoop生态圈-phoenix完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. phoenix只是一个插件,我们可以用hive给hbase套上一个JDBC壳,但是你 ...
随机推荐
- 【CF1181D】Irrigation
题目大意:给定 M 个城市,每年会选出一个城市举办比赛,现给出前 N 年城市举办比赛的情况.在接下来的年份中,每年会在举办比赛次数最小的城市举办比赛,如果有很多城市举办次数均为最小值,则在编号最小的城 ...
- Java GUI :Hello World
public class Demo01 extends Frame{ public Demo01(){ super("Demo01");//标题 this.setSize(450, ...
- MySql触发器简介
MySQL 数据库中触发器是一个特殊的存储过程,不同的是执行存储过程要使用 CALL 语句来调用,而触发器的执行不需要使用 CALL 语句来调用,也不需要手工启动,只要一个预定义的事件发生就会被 My ...
- 快速排序java代码
法一: //快速排序 通过测试 public class QuickSortTest2 { public static void quickSort(int[] data,int low,int hi ...
- yum 安装 mongodb
1 .添加阿里源 vi /etc/yum.repos.d/mongodb.repo [mongodb-org] name=MongoDB Repository baseurl=http://mirro ...
- hexdump命令
hexdump hexdump用于以16进制.10进制.8进制.ascii码形式打印文件内容,也可以是标准输入的内容. 用法 hexdump [选项] 文件 ... 选项 选项 参数 说明 -b ...
- Spring实例化相关问题
1.当Controller或者Service使用new来实例化时,能不能正常调用使用Resource声明的变量 不能,使用new来实例化时,所有使用Resource声明的变量均为null
- CF D. Number Of Permutations 排列
挺水的一道题~ 拿全排列随便乘一下就好了. #include <cstdio> #include <algorithm> #define N 300004 #define ll ...
- ORA-01440:要减小精度和标准,则要修改的列必须为空
修改字段的精度时,提示“ ORA-01440:要减小精度和标准,则要修改的列必须为空 ” 解决方法:将该表中的数据全部删除即可
- C++入门经典-例6.18-数组的动态分配,动态获得斐波那契数列
1:有时在获得一定的信息之前,我们并不确定数组的大小.动态分配数组则可以使用变量作为数组的大小,使数组的大小符合我们的要求. 2:科普一下斐波纳契数列:斐波那契数列指的是这样一个数列 1, 1, 2, ...