LDA主题模型评估方法–Perplexity
在LDA主题模型之后,需要对模型的好坏进行评估,以此依据,判断改进的参数或者算法的建模能力。
Blei先生在论文《Latent Dirichlet Allocation》实验中用的是Perplexity值作为评判标准。
一、Perplexity定义
源于wiki:http://en.wikipedia.org/wiki/Perplexity
perplexity是一种信息理论的测量方法,b的perplexity值定义为基于b的熵的能量(b可以是一个概率分布,或者概率模型),通常用于概率模型的比较
wiki上列举了三种perplexity的计算:
1.1 概率分布的perplexity
公式: 
其中H(p)就是该概率分布的熵。当概率P的K平均分布的时候,带入上式可以得到P的perplexity值=K。
1.2 概率模型的perplexity
公式: 
公式中的Xi为测试局,可以是句子或者文本,N是测试集的大小(用来归一化),对于未知分布q,perplexity的值越小,说明模型越好。
指数部分也可以用交叉熵来计算,略过不表。
1.3单词的perplexity
perplexity经常用于语言模型的评估,物理意义是单词的编码大小。例如,如果在某个测试语句上,语言模型的perplexity值为2^190,说明该句子的编码需要190bits
二、如何对LDA建模的主题模型
Blei先生在论文里只列出了perplexity的计算公式,并没有做过多的解释。
在摸索过得知,M代表测试语料集的文本数量(即多少篇文本),Nd代表第d篇文本的大小(即单词的个数),P(Wd)代表文本的概率,文本的概率是怎么算出来的呢?
在解决这个问题的时候,看到rickjin这样解释的:

p(z)表示的是文本d在该主题z上的分布,应该是p(z|d)
这里有个误区需要注意:Blei是从每篇文本的角度来计算perplexity的,而rickjin是从单词的角度计算perplexity的,不要弄混了。
总结一下:
测试文本集中有M篇文本,对词袋模型里的任意一个单词w,P(w)=∑z p(z|d)*p(w|z),即该词在所有主题分布值和该词所在文本的主题分布乘积。
模型的perplexity就是exp^{ – (∑log(p(w))) / (N) },∑log(p(w))是对所有单词取log(直接相乘一般都转化成指数和对数的计算形式),N的测试集的单词数量(不排重)
评估LDA主题模型-perflexity
LDA主题模型好坏的评估,判断改进的参数或者算法的建模能力。
perplexity is only a crude measure, it's helpful (when using LDA) to get 'close' to the appropriate number of topics in a corpus.
Blei先生在论文《Latent Dirichlet Allocation》实验中用的是Perplexity值作为评判标准,并在论文里只列出了perplexity的计算公式。

Note:M代表测试语料集的文本数量,Nd代表第d篇文本的大小(即单词的个数),P(Wd)代表文本的概率
文本的概率的计算:

p(z)表示的是文本d在该主题z上的分布,应该是p(z|d)
Note:
1. Blei是从每篇文本的角度来计算perplexity的,而上面是从单词的角度计算perplexity。
2. 测试文本集中有M篇文本,对词袋模型里的任意一个单词w,P(w)=∑z p(z|d)*p(w|z),即该词在所有主题分布值和该词所在文本的主题分布乘积。
3. 模型的perplexity就是exp^{ - (∑log(p(w))) / (N) },∑log(p(w))是对所有单词取log(直接相乘一般都转化成指数和对数的计算形式),N的测试集的单词数量(不排重)
4. P(w)=∑z p(z|d)*p(w|z)这个w是测试集上的词汇
[http://blog.csdn.net/pipisorry/article/details/42460023]
[http://faculty.cs.byu.edu/~ringger/CS601R/papers/Heinrich-GibbsLDA.pdf - 29页]
Estimate the perplexity within gensim
The `LdaModel.bound()` method computes a lower bound on perplexity, based on a supplied corpus (~of held-out documents).
This is the method used in Hoffman&Blei&Bach in their "Online Learning for LDA" NIPS article.
[https://groups.google.com/forum/#!topic/gensim/LM619SB57zM]
you can also use model.log_perplexity(heldout), which is a convenience wrapper.
[Questions find in : the mailing list of gensim]
评价一个语言模型Evaluating Language
假设我们有一些测试数据,test data.测试数据中有m个句子;s1,s2,s3…,sm
我们可以查看在某个模型下面的概率: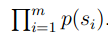
我们也知道,如果计算相乘是非常麻烦的,可以在此基础上,以另一种形式来计算模型的好坏程度。
在相乘的基础上,运用Log,来把乘法转换成加法来计算。
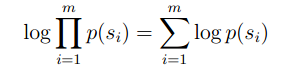
补充一下,在这里的p(Si)其实就等于我们前面所介绍的q(the|*,*)*q(dog|*,the)*q(…)…
有了上面的式子,评价一个模型是否好坏的原理在于:
a good model should assign as high probability as possible to these test data sentences.
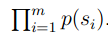 ,this value as being a measure of how well the alleviate to make sth less painful or difficult to deal with language model predict these test data sentences.
,this value as being a measure of how well the alleviate to make sth less painful or difficult to deal with language model predict these test data sentences.
The higher the better.
上面的意思也就是说,如果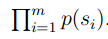 的值越大,那么这个模型就越好。
的值越大,那么这个模型就越好。
- 实际上,普遍的评价的指标是perplexity

其中,M的值是测试数据test data中的所有的数量。
那么从公式当中查看,可以知道。perplexity的值越小越好。
为了更好的理解perplexity,看下面这个例子:
- 我们现在有一个单词集V,N=|V|+1
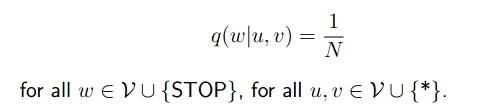
有了上面的条件,可以很容易的计算出:
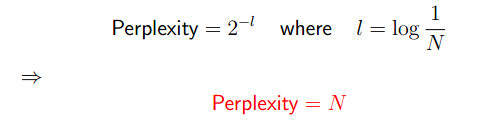
Perplexity是测试branching factor的数值。
branching factor又是什么呢?有的翻译为分叉率。如果branching factor高,计算起来代价会越大。也可以理解成,分叉率越高,可能性就越多,需要计算的量就越大。
上面的例子q=1/N只是一个举例,再看看下面这些真实的数据:
- Goodman的结果,其中|V|=50000,在trigram model的
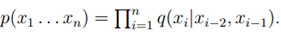 中,Perplexity=74
中,Perplexity=74 - 在bigram model中,
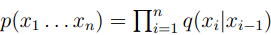 ,Perplexity=137
,Perplexity=137 - 在unigram model中,
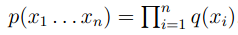 ,perplexity=955
,perplexity=955
在这里也看到了,几个模型的perplexity的值是不同的,这也就表明了三元模型一般是性能良好的。
[评价一个语言模型Evaluating Language Models:Perplexity]
Topic Coherence
一种可能更好的主题模型评价标准
[Optimizing semantic coherence in topic models.]
from:http://blog.csdn.net/pipisorry/article/details/42460023
ref:Topic models evaluation in Gensim
http://stackoverflow.com/questions/19615951/topic-models-evaluation-in-gensim
http://www.52ml.net/14623.html
Ngram model and perplexity in NLTK
http://www.researchgate.net/publication/221484800_Improving_language_model_perplexity_and_recognition_accuracy_for_medical_dictations_via_within-domain_interpolation_with_literal_and_semi-literal_corpora
Investigating the relationship between language model perplexity and IR precision-recall measures.
LDA/NMF/LSA多模型/多主题一致性评价方法《Exploring topic coherence over many models and many topics》K Stevens, P Kegelmeyer, D Andrzejewski... [University of California Los Angeles] (2012) GITHUB
论文:(概率)生成模型评价方法研究《A note on the evaluation of generative models》Lucas Theis, Aäron van den Oord, Matthias Bethge (2015)
Notes on A note on the evaluation of generative models by Hugo Larochelle
LDA主题模型评估方法–Perplexity的更多相关文章
- R语言︱LDA主题模型——最优主题数选取(topicmodels)+LDAvis可视化(lda+LDAvis)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:在自己学LDA主题模型时候,发现该模 ...
- 机器学习-LDA主题模型笔记
LDA常见的应用方向: 信息提取和搜索(语义分析):文档分类/聚类.文章摘要.社区挖掘:基于内容的图像聚类.目标识别(以及其他计算机视觉应用):生物信息数据的应用; 对于朴素贝叶斯模型来说,可以胜任许 ...
- Gensim LDA主题模型实验
本文利用gensim进行LDA主题模型实验,第一部分是基于前文的wiki语料,第二部分是基于Sogou新闻语料. 1. 基于wiki语料的LDA实验 上一文得到了wiki纯文本已分词语料 wiki.z ...
- [综] Latent Dirichlet Allocation(LDA)主题模型算法
多项分布 http://szjc.math168.com/book/ebookdetail.aspx?cateid=1&§ionid=983 二项分布和多项分布 http:// ...
- 用scikit-learn学习LDA主题模型
在LDA模型原理篇我们总结了LDA主题模型的原理,这里我们就从应用的角度来使用scikit-learn来学习LDA主题模型.除了scikit-learn, 还有spark MLlib和gensim库 ...
- Spark:聚类算法之LDA主题模型算法
http://blog.csdn.net/pipisorry/article/details/52912179 Spark上实现LDA原理 LDA主题模型算法 [主题模型TopicModel:隐含狄利 ...
- R语言︱LDA主题模型——最优主题...
R语言︱LDA主题模型——最优主题...:https://blog.csdn.net/sinat_26917383/article/details/51547298#comments
- 自然语言处理之LDA主题模型
1.LDA概述 在机器学习领域,LDA是两个常用模型的简称:线性判别分析(Linear Discriminant Analysis)和 隐含狄利克雷分布(Latent Dirichlet Alloca ...
- 机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)
函数说明 1.LDA(n_topics, max_iters, random_state) 用于构建LDA主题模型,将文本分成不同的主题 参数说明:n_topics 表示分为多少个主题, max_i ...
随机推荐
- springmvc请求参数获取(自动绑定)的几种方法
1.直接把表单的参数写在Controller相应的方法的形参中,适用于get方式提交,不适用于post方式提交. /** * 1.直接把表单的参数写在Controller相应的方法的形参中 * @pa ...
- Redis 入门 3.3 散列类型
3.3.1 介绍 散列类型(hash)的键值也是一种字典结构,其储存了字段(field)和字段值的映射,但字段值只能是字符串,不支持其他数据类型,换句话说,散列类型不能嵌套其他的数据类型.一个散列 ...
- vtkExampleWarpVector和vtkWarpScalar
vtkWarpVector : deform geometry with vector data vtkWarpVector is a filter that modifies point coord ...
- js里面for循环的++i与i++
首先我们应该都知道++i与i++的区别是: ++i 是先执行 i=i+1 再使用 i 的值,而 i++ 是先使用 i 的值再执行 i=i+1: 然后我们也知道for循环的执行顺序如下: for(A;B ...
- Egret入门学习日记 --- 第二篇 (书籍的选择 && 书籍目录 && 书中 3.3 节 内容)
第二篇 (书籍的选择 && 书籍目录 && 书中 3.3 节 内容) 既然选好了Egret,那我就要想想怎么学了. 开始第一步,先加个Q群先,这不,拿到了一本<E ...
- 人工智能AI------有限状态机、分层状态机、行为树
https://www.cnblogs.com/zhanlang96/p/4793511.html 人工智能遵循着:感知->思考->行动决策方法:有限状态机(Finite-State Ma ...
- 将dos窗口调白教程
将dos弹出窗口调白教程 第1步:同时按住Win+R键,输入cmd 第2步:右键点击标题栏 第3步:点击默认值,然后再点击颜色 第四步:将窗口颜色设置为白色,字体颜色设置为黑色(效果测试)
- #Java学习之路——基础阶段二(第十四篇)
我的学习阶段是跟着CZBK黑马的双源课程,学习目标以及博客是为了审查自己的学习情况,毕竟看一遍,敲一遍,和自己归纳总结一遍有着很大的区别,在此期间我会参杂Java疯狂讲义(第四版)里面的内容. 前言: ...
- EINT DINT ERTM DRTM EALLOW EDIS ESTOP0的理解
本文参考以下资料整理 https://wenku.baidu.com/view/6b0d6906cf84b9d528ea7a66.html http://pangqicheng123.blog.163 ...
- kali安装redis
下载 wget http://download.redis.io/releases/redis-4.0.11.tar.gz 解压 tar -zxvf redis-4.0.11.tar.gz 切换目录 ...