机器学习性能指标之ROC和AUC理解与曲线绘制
一. ROC曲线
1、roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性。
横轴:负正类率(false postive rate FPR)特异度,划分实例中所有负例占所有负例的比例;(1-Specificity)
纵轴:真正类率(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率)
2、针对一个二分类问题,将实例分成正类(postive)或者负类(negative)。但是实际中分类时,会出现四种情况.
(1)若一个实例是正类并且被预测为正类,即为真正类(True Postive TP)
(2)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
(3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
(4)若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN)
TP:正确的肯定数目
FN:漏报,没有找到正确匹配的数目
FP:误报,没有的匹配不正确
TN:正确拒绝的非匹配数目
列联表如下,1代表正类,0代表负类:
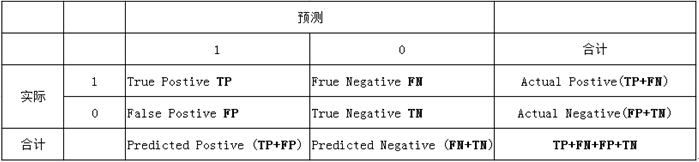
由上表可得出横,纵轴的计算公式:
(1)真正类率(True Postive Rate)TPR: TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。
(2)负正类率(False Postive Rate)FPR: FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例。
(3)真负类率(True Negative Rate)TNR: TN/(FP+TN),代表分类器预测的负类中实际负实例占所有负实例的比例,TNR=1-FPR。
假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
如下面这幅图,(a)图中实线为ROC曲线,线上每个点对应一个阈值。
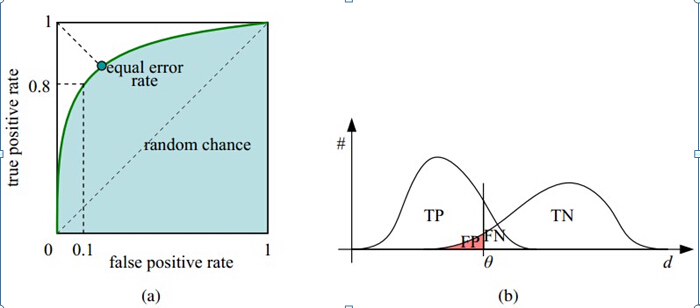
横轴FPR:1-TNR,1-Specificity,FPR越大,预测正类中实际负类越多。
纵轴TPR:Sensitivity(正类覆盖率),TPR越大,预测正类中实际正类越多。
二. 如何画roc曲线
假设已经得出一系列样本被划分为正类的概率,然后按照大小排序,下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。
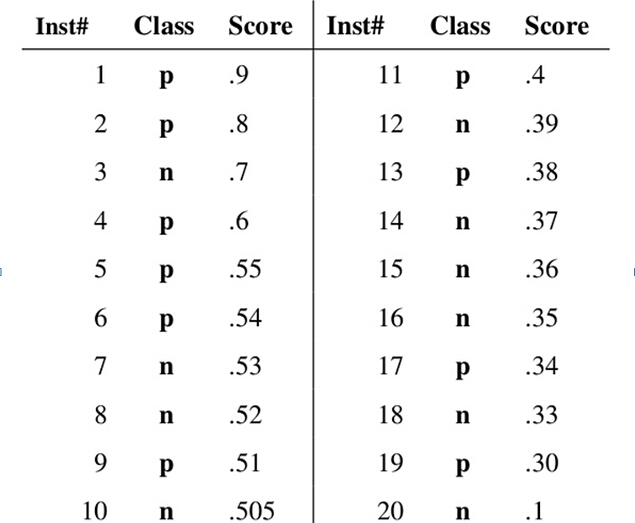
接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:
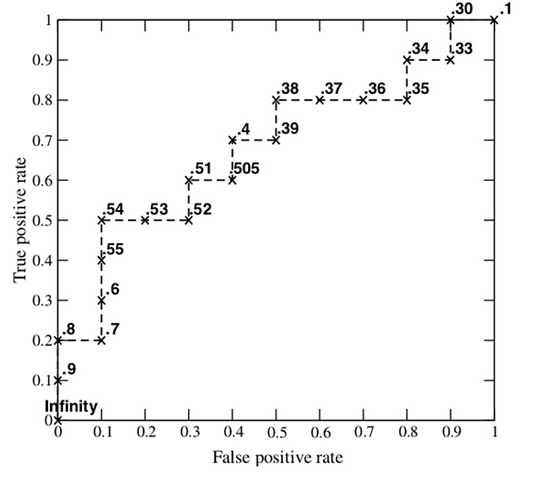
上图ROC曲线一些点怎么得到的分析
具体分析如下:
可以看出实际类别为P的有10个,实际类别为N的也有10个
- Score = 0.9时,样本1被认为(预测)是正类(P)。此时根据混淆矩阵有: TP = 1, FN = 9, FP = 0,TN = 10。
这是因为样本1为正类(P)被正确预测为正类(P),因此TP = 1; 其他实际正类类别(class为P的)样本有9个,它们被预测为负类(N)了,因此FN = 9; 样本实际为负类(N)的,被预测为正类(P)的没有一个,因此FP = 0, 其他实际负类类别(class为N的)样本有10个,它们全部被预测为负类(N)了,因此TN = 10 。故TPR = 1/(1+9) = 0.1- Score = 0.8时, 同理有: TP = 2, FN = 8,FP = 0, TN = 10。 故TPR = 2/(2+8) = 0.2
- Score = 0.7时,有: TP = 2, FN = 8,FP = 1, TN = 9。 故TPR = 2/(2+8) = 0.2
- Score = 0.6时,有:TP = 3, FN = 7,FP = 1, TN = 9。 故TPR = 3/(3+7) = 0.3
以此类推
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。
首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
三 为什么使用Roc和Auc评价分类器
既然已经这么多标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。下图是ROC曲线和Presision-Recall曲线的对比:
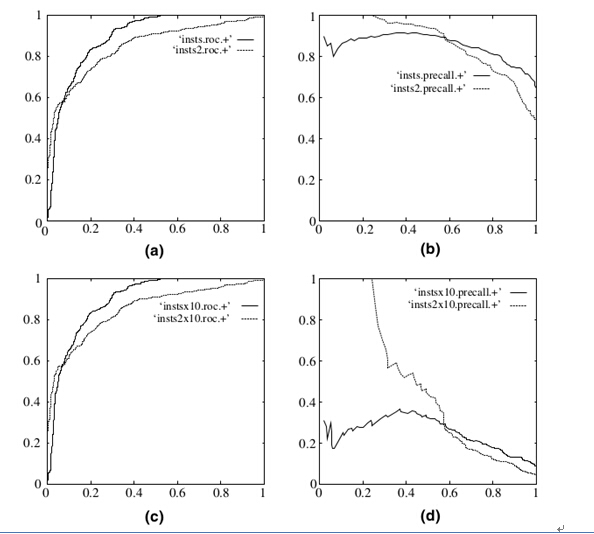
在上图中,(a)和(c)为Roc曲线,(b)和(d)为Precision-Recall曲线。
(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果,可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线变化较大。
绘制ROC曲线计算AUC值
输入的数据集可以参考svm预测结果
- case1: 只去前面36行样本数据,txt文件名为:
evaluate_result2
'''
这里的.txt文件格式如:http://kubicode.me/img/AUC-Calculation-by-Python/evaluate_result.txt
'''
#绘制二分类ROC曲线
import matplotlib.pyplot as plt
from math import log, exp, sqrt
evaluate_result = './evaluate_result2.txt'
db = [ ] #[score,nonclk,clk]
pos, neg = 0, 0
with open(evaluate_result, 'r') as fs:
for line in fs:
nonclk, clk, score = line.strip().split('\t') #变成列表list形式
nonclk = int(nonclk)
clk = int(clk)
db.append([score,nonclk,clk])
score = float(score)
neg = neg + nonclk
#print("neg数量====", neg, end = '')
pos = pos + clk
#print(", pos数量====", pos)
#print("db= ",db)
db = sorted(db, key=lambda x:x[0], reverse=True) #对ad的score进行降序排序
#print("db_reverse= ",db)
#计算ROC坐标点
xy_arr = [ ]
tp, fp = 0., 0.
for i in range(len(db)):
fp += db[i][1]
#print("fp ===", fp, end = '')
tp += db[i][2]
#print(", tp ===",tp)
xy_arr.append([fp/neg, tp/pos]) #fp除以negative数目, tp除以positive数目。作为坐标点
#print(xy_arr) #[[0.06666666666666667, 0.0], [0.06666666666666667, 0.029411764705882353],...]
# 计算曲线下面积
auc = 0.
prev_x = 0
for x, y in xy_arr: # x= fp/neg, y = tp/pos
if x != prev_x:
auc += (x - prev_x) * y #矩形面积累加
prev_x = x
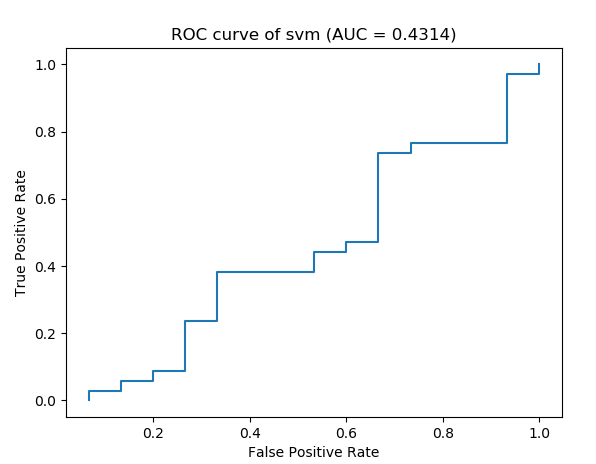
print("The auc is %s" %auc)
x = [ v[0] for v in xy_arr]
y = [ v[1] for v in xy_arr]
plt.title("ROC curve of %s (AUC = %.4f)" % ('svm',auc))
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.plot(x, y)
plt.show()
输出:
The auc is 0.43137254901960786
- case2: 取全部数据,txt文件名为:
evaluate_result
'''
这里的.txt文件格式如:http://kubicode.me/img/AUC-Calculation-by-Python/evaluate_result.txt
'''
#绘制二分类ROC曲线
import matplotlib.pyplot as plt
from math import log, exp, sqrt
evaluate_result = './evaluate_result.txt'
db = [ ] #[score,nonclk,clk]
pos, neg = 0, 0
with open(evaluate_result, 'r') as fs:
for line in fs:
nonclk, clk, score = line.strip().split('\t') #变成列表list形式
nonclk = int(nonclk)
clk = int(clk)
db.append([score,nonclk,clk])
score = float(score)
neg = neg + nonclk
#print("neg数量====", neg, end = '')
pos = pos + clk
#print(", pos数量====", pos)
#print("db= ",db)
db = sorted(db, key=lambda x:x[0], reverse=True) #对ad的score进行降序排序
#print("db_reverse= ",db)
#计算ROC坐标点
xy_arr = [ ]
tp, fp = 0., 0.
for i in range(len(db)):
fp += db[i][1]
#print("fp ===", fp, end = '')
tp += db[i][2]
#print(", tp ===",tp)
xy_arr.append([fp/neg, tp/pos]) #fp除以negative数目, tp除以positive数目。作为坐标点
#print(xy_arr) #[[0.06666666666666667, 0.0], [0.06666666666666667, 0.029411764705882353],...]
# 计算曲线下面积
auc = 0.
prev_x = 0
for x, y in xy_arr: # x= fp/neg, y = tp/pos
if x != prev_x:
auc += (x - prev_x) * y #矩形面积累加
prev_x = x
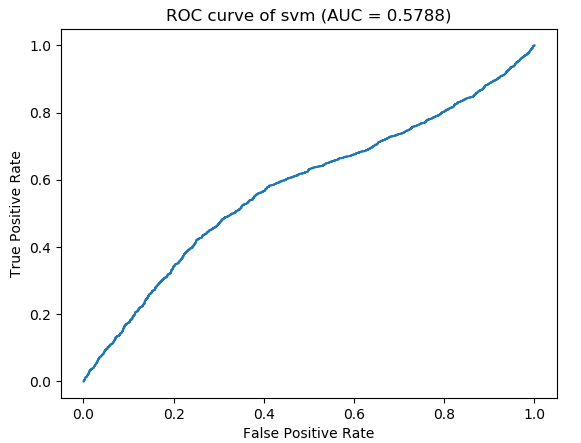
print("The auc is %s" %auc)
x = [ v[0] for v in xy_arr]
y = [ v[1] for v in xy_arr]
plt.title("ROC curve of %s (AUC = %.4f)" % ('svm',auc))
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.plot(x, y)
plt.show()
输出:
The auc is 0.5788039199235478
参考资料:
机器学习性能指标之ROC和AUC理解与曲线绘制的更多相关文章
- 机器学习性能指标(ROC、AUC、召回率)
混淆矩阵 构造一个高正确率或高召回率的分类器比较容易,但很难保证二者同时成立 ROC 横轴:FPR(假正样本率)=FP/(FP+TN) 即,所有负样本中被分错的比例 纵轴:TPR(真正样本率)=TP/ ...
- ROC和AUC理解
一. ROC曲线概念 二分类问题在机器学习中是一个很常见的问题,经常会用到.ROC (Receiver Operating Characteristic) 曲线和 AUC (Area Under th ...
- 机器学习之分类器性能指标之ROC曲线、AUC值
分类器性能指标之ROC曲线.AUC值 一 roc曲线 1.roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性 ...
- 机器学习-Confusion Matrix混淆矩阵、ROC、AUC
本文整理了关于机器学习分类问题的评价指标——Confusion Matrix.ROC.AUC的概念以及理解. 混淆矩阵 在机器学习领域中,混淆矩阵(confusion matrix)是一种评价分类模型 ...
- 机器学习性能指标精确率、召回率、F1值、ROC、PRC与AUC--周振洋
机器学习性能指标精确率.召回率.F1值.ROC.PRC与AUC 精确率.召回率.F1.AUC和ROC曲线都是评价模型好坏的指标,那么它们之间有什么不同,又有什么联系呢.下面让我们分别来看一下这几个指标 ...
- 五分钟秒懂机器学习混淆矩阵、ROC和AUC
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第18篇文章,我们来看看机器学习领域当中,非常重要的其他几个指标. 混淆矩阵 在上一篇文章当中,我们在介绍召回率.准确率 ...
- 【分类问题中模型的性能度量(二)】超强整理,超详细解析,一文彻底搞懂ROC、AUC
文章目录 1.背景 2.ROC曲线 2.1 ROC名称溯源(选看) 2.2 ROC曲线的绘制 3.AUC(Area Under ROC Curve) 3.1 AUC来历 3.2 AUC几何意义 3.3 ...
- ROC和AUC介绍以及如何计算AUC ---好!!!!
from:https://www.douban.com/note/284051363/?type=like 原帖发表在我的博客:http://alexkong.net/2013/06/introduc ...
- 【转】ROC和AUC介绍以及如何计算AUC
转自:https://www.douban.com/note/284051363/ ROC(Receiver Operating Characteristic)曲线和AUC常被用来评价一个二值分类器( ...
随机推荐
- .NET 单点登录解决方案
这里指的单点,泛指在WEB服务端,一个账户同一时刻只能存在一个票据! 大家开发中可能都碰到的一个问题,怎么使同一个用户,在同一时间内只允许登录一次. 很多人都会想到在数据库中用一个标识字段,登录进去置 ...
- Apache thrift - 使用,内部实现及构建一个可扩展的RPC框架
本文首先介绍了什么是Apache Thrift,接着介绍了Thrift的安装部署及如何利用Thrift来实现一个简单的RPC应用,并简单的探究了一下Thrift的内部实现原理,最后给出一个基于Thri ...
- day23面向对象第一篇
python之路——初识面向对象 阅读目录 楔子 面向过程vs面向对象 初识面向对象 类的相关知识 对象的相关知识 对象之间的交互 类命名空间与对象.实例的命名空间 类的组合用法 初识面向对象 ...
- day4笔记
今日讲解内容:1,int数字:运算.1 ,2,3... # 数字类型:int #范围.用于运算, + - * / // %.... bit_lenth :十进制数字用二进制表示的最小位数 a=10 p ...
- sql duplicate key
本文来自:高爽,转载请注明. 向数据库插入记录时,有时会有这种需求,当符合某种条件的数据存在时,去修改它,不存在时,则新增,也就是saveOrUpdate操作.这种控制可以放在业务层,也可以放在数据库 ...
- 启发式搜索技术A*
开篇 这篇文章介绍找最短路径的一种算法,它的字我比较喜欢:启发式搜索. 对于入门的好文章不多,而这篇文章就是为初学者而写的,很适合入门的一篇.文章定位:非专业性A*文章,很适合入门. 有图有真相,先给 ...
- tomcat8热部署配置--maven自动发布项目到tomcat8(如何支持远程访问部署)
1.tomcat8实现热部署的配置 我们实现热部署后,自然就可以通过maven操作tomcat了,所以就需要maven取得操作tomcat的权限,现在这一步就是配置tomcat的可操作权限. #进入 ...
- Server Objects Extension(SOE)开发(二)
前言 SOE的提供了REST和Soap两种模板,只要在模板特定的方法中添加自己的业务逻辑代码即可,开发流程非常的简单便捷.那怎么知道自己的业务逻辑代码该写在模板的那个方法里面呢?这就需要很好的理解SO ...
- ES6学习笔记(二)——字符串扩展
相信很多人也和我一样,不喜欢这样循规蹈矩的逐条去学习语法,很枯燥乏味.主要是这样学完一遍之后,没过一段时间就忘到九霄云外了.不如实际用到的时候研究它记得牢靠,所以我就整理成笔记,加深记忆的同时便于复习 ...
- 阿里云短信验证解决方案(java版)(redis存储)
最近搞了一个互联网项目的注册,需要写一个手机号验证(由于之前没有轮子,只能自己摸索了); 1:基本思路: 1>购买了阿里云短信服务->下载阿里云短信发送demo(java版); 2> ...