scrapy--json(360美图)
之前开始学习scrapy,接触了AJax异步加载。一直没放到自己博客,趁现在不忙,也准备为下一个爬虫做知识储存,就分享给大家。
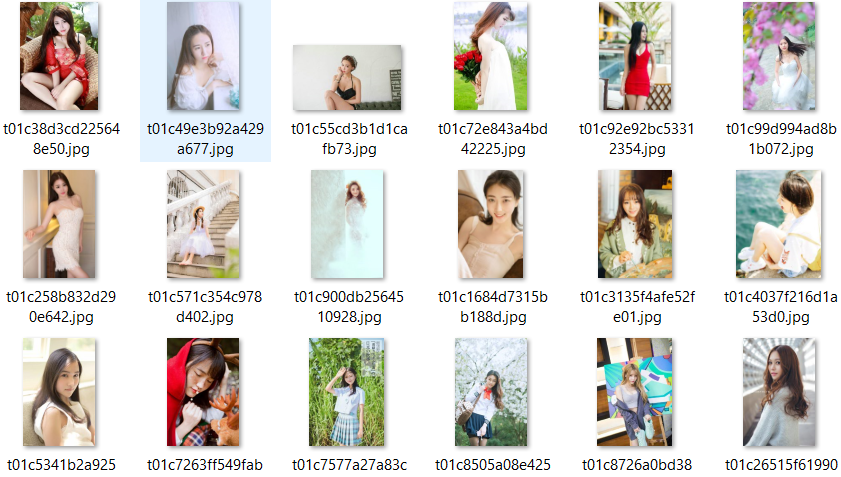
还是从爬取图片开始,先上图给大家看看成果,QAQ。
一、图片加载的方法
1.1:网页源码__javascript加载数据
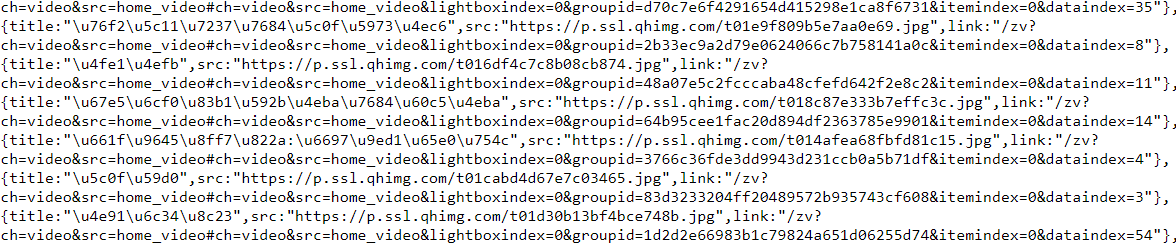
1.2:F12审查元素:滑动滑块,图片开始不断加载,
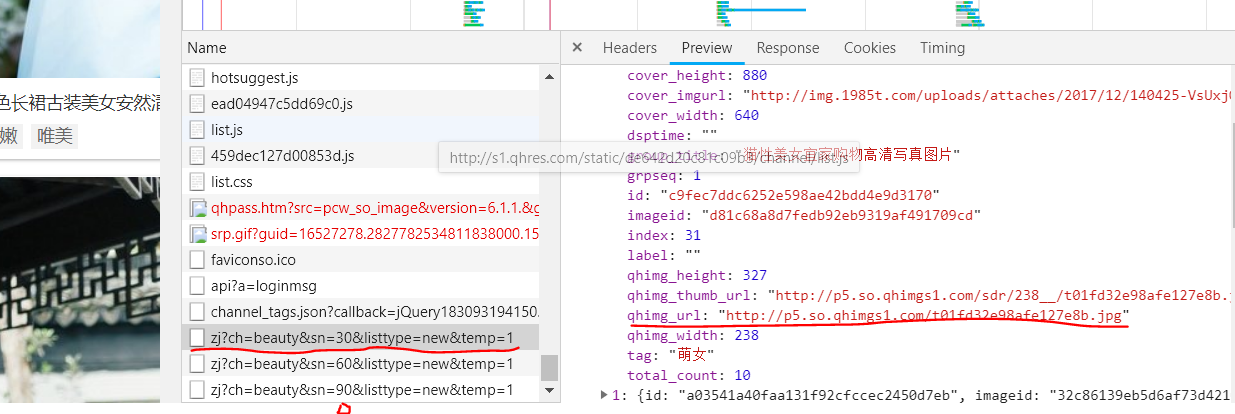
1.3:json数据:"http://image.so.com/zj?ch=beauty&sn=30&listtype=new&temp=1"

图片的URL储存在["list"]["qhimg_url"]
二、实现代码image.py.items.py,middlewares.py,settings.py,pipelines.py在我之前博客中能找到,在这里就不展示了,也可以进我的github:
# -*- coding: utf-8 -*-
import scrapy
from Tupian360.items import Tupian360Item
import json
import pdb
from Tupian360.settings import USER_AGENT
import random class ImageSpider(scrapy.Spider):
name = 'image'
allowed_domains = ['image.so.com']
pager_count = 0 headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'image.so.com',
'Origin': 'image.so.com',
'Referer': 'http://image.so.com/zj?ch=beauty&sn=%s&listtype=new&temp=1'%pager_count,
'User-Agent': USER_AGENT,
'X-Requested-With': 'XMLHttpRequest',
} old_urls = 'http://image.so.com/zj?ch=beauty&sn=%s&listtype=new&temp=1'
start_urls = [old_urls%pager_count] def parse(self, response):
tupian = Tupian360Item()
sel = json.loads(response.body.decode('utf8'))
counts = sel['count']
self.pager_count += int(counts)
new_url = self.old_urls%self.pager_count
for link in sel['list']:
tupian['image_urls'] = link['qhimg_url']
yield tupian yield scrapy.Request(new_url,callback=self.parse)
scrapy--json(360美图)的更多相关文章
- 分析AJAX抓取今日头条的街拍美图并把信息存入mongodb中
今天学习分析ajax 请求,现把学得记录, 把我们在今日头条搜索街拍美图的时候,今日头条会发起ajax请求去请求图片,所以我们在网页源码中不能找到图片的url,但是今日头条网页中有一个json 文件, ...
- thinkphp + 美图秀秀api 实现图片裁切上传,带数据库
思路: 1.数据库 创建test2 创建表img,字段id,url,addtime 2.前台页: 1>我用的是bootstrap 引入必要的js,css 2>引入美图秀秀的js 3.后台: ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 美图DPOS以太坊教程(Docker版)
一.前言 最近,需要接触区块链项目的主链开发,在EOS.BTC.ethereum.超级账本这几种区块链技术当中,相互对比后,最终还是以go-ethereum为解决方案. 以ethereum为基准去找解 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 小幻美图 API
『不忘初心,方得始终.』 小幻美图 API 更新:2015.03.29 目前提供的API共有10种! 必应各种今日获取API共4种! 本站收录图片获取API共4种! 网络图片尺寸修改API共1枚! 百 ...
随机推荐
- C++ map的基本操作和用法
1.map简介 map是一类关联式容器.它的特点是增加和删除节点对迭代器的影响很小,除了那个操作节点,对其他的节点都没有什么影响.对于迭代器来说,可以修改实值,而不能修改key. 2.map的功能 自 ...
- Xtrareport 多栏报表
首先看下布局designer 细节: 分组一定要用到GroupHeather 设置好有 右边会出现 接下来是代码部分 Form1中代码 using DevExpress.XtraReports.UI; ...
- .NET开发人员必知的八个网站
当前全球有数百万的开发人员在使用微软的.NET技术.如果你是其中之一,或者想要成为其中之一的话,我下面将要列出的每一个站点都应该是你的最爱,都应该收藏到书签中去.对于不熟悉.NET技术的朋友,需要说明 ...
- jeecg3.8在子表页面中使用WebUploader组件
bcAbout-update.jsp改动如下: 因为默认子表的上传组件不能回显,所以改造成WebUploader 1.在更新页面注销掉生成代码 <%--<script type=" ...
- ndk制作so库,ndk-build不是内部或外部命令。。。的错误
想了想大概就需要下面这几步: 1.下载ndk 2.配置ndk的环境变量 3.在android studio添加一些ndk的配置 4.编写c文件 5.生成so库 6.调用so库 上面提到的大部分问题你都 ...
- strdup和strndup函数
首先说明一下:这两个函数不建议使用,原因是返回内存地址把释放权交给别的变量,容易忘记释放. 一.strdup函数 函数原型 头文件:#include <string.h> char *st ...
- 数据仓库是什么?OLTP和OLAP是什么?
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented).集成的(Integrate).相对稳定的(Non-Volatile).反映历史变化(Time Varian ...
- 更改Anaconda中Jupyter的默认文件保存目录
转载:https://blog.csdn.net/u014552678/article/details/62046638 总结:修改Anaconda中的Jupyter Notebook默认工作路径的三 ...
- Scala OOP
Scala OOP 1.介绍 Scala是对java的封装,底层仍然采用java来实现,因此Scala也是面向对象的.其中scala给出了class.object和trait三种面向对象的组件.
- Windows计算下载文件的SHA256 MD5 SHA1
引用自 http://blog.163.com/licanli2082@126/blog/static/35748686201284611330/ certutil -hashfile yourfil ...