Flume推送数据到SparkStreaming案例实战和内幕源码解密
本期内容:
1. Flume on HDFS案例回顾
2. Flume推送数据到Spark Streaming实战
3. 原理绘图剖析
1. Flume on HDFS案例回顾
上节课要求大家自己安装配置Flume,并且测试数据的传输。我昨天是要求传送的HDFS上。
文件配置:
~/.bashrc:
export FLUME_HOME=/usr/local/flume/apache-flume-1.6.0-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
PATH中增加:${FLUME_HOME}/bin;
拷贝conf/flume-conf.properties.template,更名为conf/flume-cong.properties,只写以下内容:
agent1表示代理名称
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#配置source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/local/flume/tmp/TestDir
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#配置sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=hdfs://master:9000/library/flume
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
#agent1.sinks.sink1.type=avro
#agent1.sinks.sink1.channel=channel1
#agent1.sinks.sink1.hostname=Master
#agent1.sinks.sink1.port=9999
#配置channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir=/usr/local/flume/tmp/checkpointDir
agent1.channels.channel1.dataDirs=/usr/local/flume/tmp/dataDirs
flume-env.sh配置:
# export JAVA_HOME=/usr/lib/jvm/java-6-sun
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
# Give Flume more memory and pre-allocate, enable remote monitoring via JMX
# export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
建立文件夹 /usr/local/flume/tmp/TestDir。
在hdfs上建立/library/flume文件夹。
flume的bin文件夹下启动Flume:
./flume-ng agent -n agent1 -c conf -f /usr/local/flume/apache-flume-1.6.0-bin/conf/flume-conf.properties -Dflume.root.logger=DEBUG,console
在/usr/local/flume/tmp/TestDir下,拷入测试用的文件,比如:NOTICE
flume 控制台会有一些相关信息:
16/04/22 11:03:49 INFO avro.ReliableSpoolingFileEventReader: Preparing to move file /usr/local/flume/tmp/TestDir/NOTICE to /usr/local/flume/tmp/TestDir/NOTICE.COMPLETED
16/04/22 11:03:51 INFO hdfs.HDFSDataStream: Serializer = TEXT, UseRawLocalFileSystem = false
16/04/22 11:03:51 INFO hdfs.BucketWriter: Creating hdfs://master:9000/library/flume/2016-04-22.1461294231806.tmp
16/04/22 11:03:52 INFO hdfs.BucketWriter: Closing hdfs://master:9000/library/flume/2016-04-22.1461294231806.tmp
16/04/22 11:03:52 INFO hdfs.BucketWriter: Renaming hdfs://master:9000/library/flume/2016-04-22.1461294231806.tmp to hdfs://master:9000/library/flume/2016-04-22.1461294231806
可以发现本地的NOTICE文件更名为NOTICE.COMPLETED。
用浏览器查询:http://localhost:50070/explorer.html#/library/flume,可看到Flume把NOTICE文件传送到 HDFS的/library/flume下,文件名为 2016-04-22.1461294231806。打开文件看内容可以验证。说明当Flume指定的源文件夹中有新文件时,Flume会自动将此文件,导入到Flume配置时指定的HDFS文件夹中。
一般正常业务情况下,应该是把Flume的数据放到Kafka中,然后让不同的数据消费者去消费数据。如果要在Flume和Kafka两者间做选择的话,则要看业务中数据是否持续不断的产生。如果是这样,则应该选择Kafka。如果产生的数据时大时小,甚至有些时间没有数据,则没必要用Kafka,可以节省资源。
2. Flume推送数据到Spark Streaming实战
现在我们不把Flume的数据导入到HDFS中,而是把数据推送到Spark Streaming中。
修改conf/flume-cong.properties文件,改导入到HDFS,变为推送到Spark Streaming。
#配置sink1
#agent1.sinks.sink1.type=hdfs
#agent1.sinks.sink1.hdfs.path=hdfs://master:9000/library/flume
#agent1.sinks.sink1.hdfs.fileType=DataStream
#agent1.sinks.sink1.hdfs.writeFormat=TEXT
#agent1.sinks.sink1.hdfs.rollInterval=1
#agent1.sinks.sink1.channel=channel1
#agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d
agent1.sinks.sink1.type=avro
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hostname=Master
agent1.sinks.sink1.port=9999
编写Spark Streaming应用的Java程序:
public class FlumePushData2SparkStreaming {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local[4]").setAppName("FlumePushDate2SparkStreaming");
JavaStreamingContext jsc = new JavaStreamingContext(conf, Durations.seconds(30));
JavaReceiverInputDStream lines = FlumeUtils.createStream(jsc,"Master", 9999);
// 注意此处输入的event类型是SparkFlumeEvent类型。
JavaDStream<String> words = lines.flatMap(new FlatMapFunction<SparkFlumeEvent, String>() {
@Override
public Iterable<String> call(SparkFlumeEvent event) throws Exception {
String line = new String(event.event().getBody().array());
return Arrays.asList(line.split(" "));
}
});
JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordsCount.print();
jsc.start();
jsc.awaitTermination();
jsc.close();
}
}
代码中用到了FlumeUtils。我们剖析一下代码中用到的FlumeUtils。
以上代码中FlumeUtil的方法createStream:
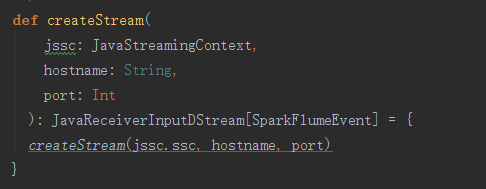
实际是调用以下createStream方法:
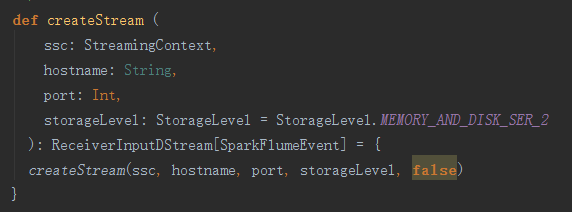
可以看到流处理默认的存储方式是,既在内存,又在磁盘中,同时做序列化,而且用两台机器。
继续看调用的createStream方法:

实际上返回的是FlumeInputDStream对象,而且事件是Flume所定义的事件SparkFlumeEvent。所以要注意,在以上Java代码做flatMap时,FlatMapFunction的输入类型必须是SparkFlumeEvent类型。
再看看FlumeInputDStream的代码:
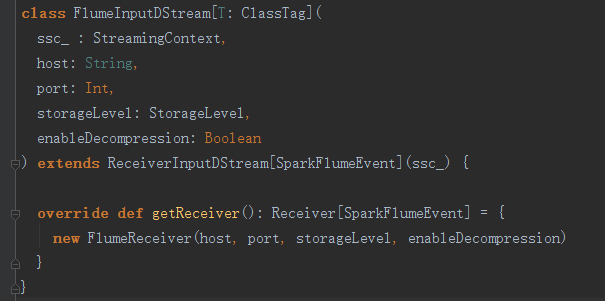
可以看到getReceiver返回的是用于接收数据的FlumeReceiver对象。再看FlumeReceiver:

可以发现Flume使用了Netty。如果搞分布式编程,要重视使用Netty。
把以上的应用Spark Streaming的Java程序运行起来。确认Flume也在运行。
我们找若干文件拷入TestDir文件夹,比如:flume下的若干文本文件。那么在Java运行的控制台,可以发现以下信息:

说明Flume推送数据到了Spark Streaming,Spark Streaming对数据及时进行了处理。
3. 原理绘图剖析

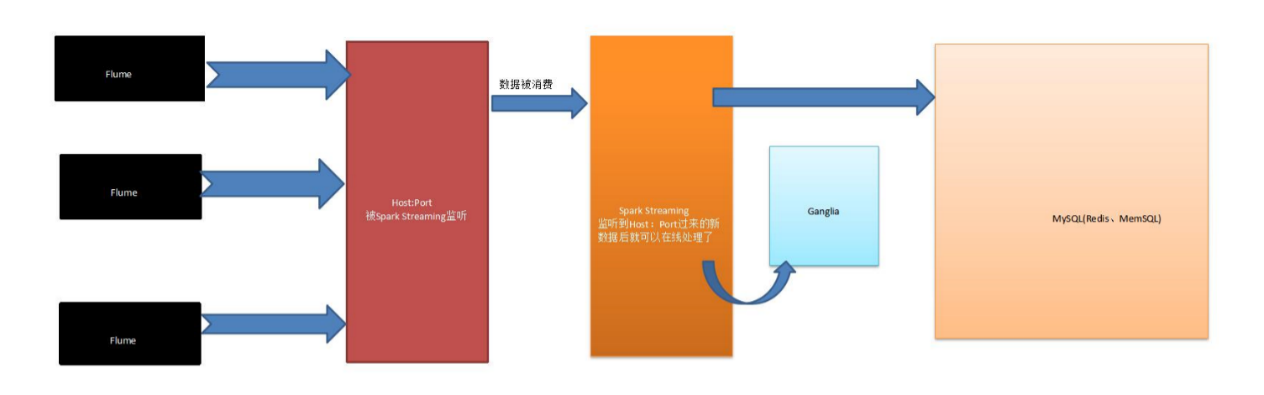
总结:
备注:87课
更多私密内容,请关注微信公众号:DT_Spark
Flume推送数据到SparkStreaming案例实战和内幕源码解密的更多相关文章
- 基于HDFS的SparkStreaming案例实战和内幕源码解密
一:Spark集群开发环境准备 启动HDFS,如下图所示: 通过web端查看节点正常启动,如下图所示: 2.启动Spark集群,如下图所示: 通过web端查看集群启动正常,如下图所示: 3.启动sta ...
- Spark Streaming updateStateByKey案例实战和内幕源码解密
本节课程主要分二个部分: 一.Spark Streaming updateStateByKey案例实战二.Spark Streaming updateStateByKey源码解密 第一部分: upda ...
- Spark Streaming从Flume Poll数据案例实战和内幕源码解密
本节课分成二部分讲解: 一.Spark Streaming on Polling from Flume实战 二.Spark Streaming on Polling from Flume源码 第一部分 ...
- SQL Server 2000向SQL Server 2008 R2推送数据
[文章摘要]最近做的一个项目要获取存在于其他服务器的一些数据,为了安全起见,采用由其他“服务器”向我们服务器推送的方式实现.我们服务器使用的是SQL Server 2008 R2,其他“服务器”使用的 ...
- WebService推送数据,数据结构应该怎样定义?
存放在Session有一些弊端,不能实时更新.server压力增大等... 要求:将从BO拿回来的数据存放在UI Cache里面,数据库更新了就通过RemoveCallback "告诉&qu ...
- java接口对接——调用别人接口推送数据
实际开发中经常会遇到要和其他平台或系统对接的情况,实际操作就是互相调用别人的接口获取或者推送数据, 当我们调用别人接口推送数据时,需要对方给一个接口地址以及接口的规范文档,规范中要包括接口的明确入参及 ...
- SuperSocket主动从服务器端推送数据到客户端
关键字: 主动推送, 推送数据, 客户端推送, 获取Session, 发送数据, 回话快照 通过Session对象发送数据到客户端 前面已经说过,AppSession 代表了一个逻辑的 socke ...
- httpclient post推送数据
客户端代码 /** * 从接口获取数据 * @param url 服务器接口地址 * @param json 传入的参数 若获取全部,此项为空 * @return 返回查询到的数据 * @throws ...
- Asp.net Core3.1+Vue 使用SignalR推送数据
本文就简单使用 往前端页面推送消息 SignalR 是什么 SignalR是一个.NET Core/.NET Framework的开源实时框架. SignalR的可使用Web Socket, Serv ...
随机推荐
- 多校4 lazy running (最短路)
lazy running(最短路) 题意: 一个环上有四个点,从点2出发回到起点,走过的距离不小于K的最短距离是多少 \(K <= 10^{18} 1 <= d <= 30000\) ...
- Codeforces 932.A Palindromic Supersequence
A. Palindromic Supersequence time limit per test 2 seconds memory limit per test 256 megabytes input ...
- android 跨进程通信
转自:http://www.androidsdn.com/article/show/137 由于android系统中应用程序之间不能共享内存.因此,在不同应用程序之间交互数据(跨进程通讯)就稍微麻烦一 ...
- HDU 3389 Game (阶梯博弈)
Game Time Limit: 1000MS Memory Limit: 32768KB 64bit IO Format: %I64d & %I64u Submit Status D ...
- Html5学习进阶四 表单元素和表单属性
HTML5 的新的表单元素: HTML5 拥有若干涉及表单的元素和属性. 本章介绍以下新的表单元素: datalist keygen output 浏览器支持 Input type IE Firefo ...
- windows实时监测热插拔设备的变化2
//动态监测设备插拔 #include <Dbt.h> BEGIN_MESSAGE_MAP(ParticipateMeeting, CDialogEx) ON_WM_DEVICECHANG ...
- v4l2 spec 中文 Ch01【转】
转自:http://blog.csdn.net/wuhzossibility/article/details/6638245 目录(?)[-] Chapter 1 通用APICommon API El ...
- off charging mode flow
/system/core/init/init.cpp ..... ..... ..... int main(int argc, char** argv) { ..... ..... ..... // ...
- python 独立环境安装
python 即使是单独编译安装的,库文件的安装还是会与其它python的库存放到相同的地方 使用同版本库不会有问题,但是需要升级库的时候,就会出现冲突,导致依赖这个旧库的python出现问题 这时候 ...
- JS或jsp获取Session中保存的值
JS是不能读取Session中的值的 . session是服务器对象, javascript是客户端脚本,你能做的操作就是把这个值用 <%=%>输出到页面的javascript中参与运算, ...